Quick scan for drift🙏🏻
ML based algorading is all about detecting any kind of non-randomness & exploiting it, kinda speculative stuff, not my way, but still...
Drift is one of the patterns that can be exploited, because pure random walks & noise aint got no drift.
This is an efficient method to quickly scan tons of timeseries on the go & detect the ones with drift by simply checking wherther drift < -0.5 or drift > 0.5. The code can be further optimized both in general and for specific needs, but I left it like dat for clarity so you can understand how it works in a minute not in an hour
^^ proving 0.5 and -0.5 are natural limits with no need to optimize anything, we simply put the metric on random noise and see it sits in between -0.5 and 0.5
You can simply take this one and never check anything again if you require numerous live scans on the go. The metric is purely geometrical, no connection to stats, TSA, DSA or whatever. I've tested numerous formulas involving other scaling techniques, drift estimates etc (even made a recursive algo that had a great potential to be written about in a paper, but not this time I gues lol), this one has the highest info gain aka info content.
The timeseries filtered by this lil metric can be further analyzed & modelled with more sophisticated tools.
Live Long and Prosper
P.S.: there's no such thing as polynomial trend/drift, it's alwasy linear, these curves you see are just really long cycles
P.S.: does cheer still work on TV? @admin
Drift

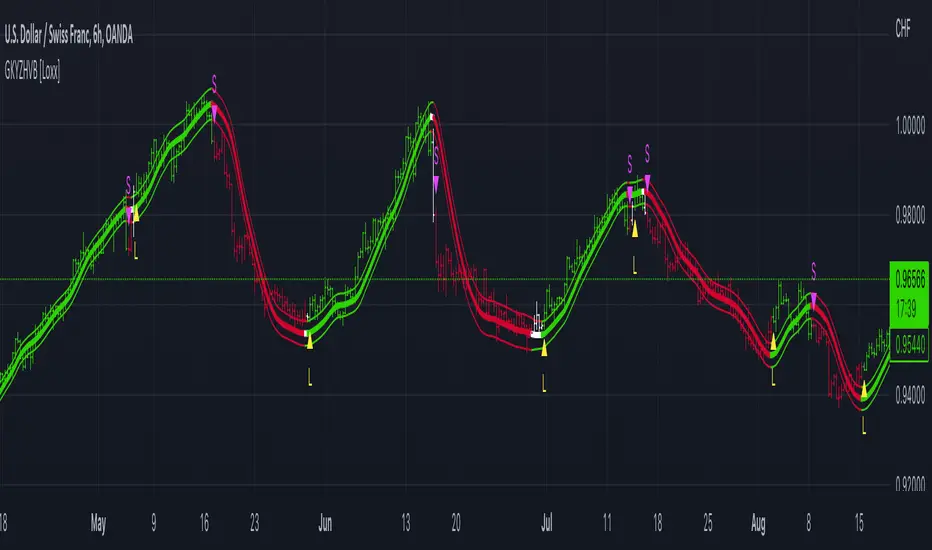
Garman-Klass-Yang-Zhang Historical Volatility Bands [Loxx]Garman-Klass-Yang-Zhang Historical Volatility Bands are constructed using:
Average as the middle line.
Upper and lower bands using the Garman-Klass-Yang-Zhang Historical Volatility Bands for bands calculation.
What is Garman-Klass-Yang-Zhang Historical Volatility?
Yang and Zhang derived an extension to the Garman Klass historical volatility estimator that allows for opening jumps. It assumes Brownian motion with zero drift. This is currently the preferred version of open-high-low-close volatility estimator for zero drift and has an efficiency of 8 times the classic close-to-close estimator. Note that when the drift is nonzero, but instead relative large to the volatility, this estimator will tend to overestimate the volatility. The Garman-Klass-Yang-Zhang Historical Volatility calculation is as follows:
GKYZHV = sqrt((Z/n) * sum((log(open(k)/close(k-1)))^2 + (0.5*(log(high(k)/low(k)))^2) - (2*log(2) - 1)*(log(close(k)/open(2:end)))^2))
The color of the middle line, unlike the bands colors, has 3 colors. When colors of the bands are the same, then the middle line has the same color, otherwise it's white.
Included
Alerts
Signals
Loxx's Expanded Source Types
Bar coloring
Related Indicators
Garman & Klass Estimator Historical Volatility Bands
Drift Study (Inspired by Monte Carlo Simulations with BM) [KL]Inspired by the Brownian Motion ("BM") model that could be applied to conducting Monte Carlo Simulations, this indicator plots out the Drift factor contributing to BM.
Interpretation : If the Drift value is positive, then prices are possibly moving in an uptrend. Vice versa for negative drifts.

ALMA PhysicsA super simple yet elegant indicator, "ALMA Physics" calculates the derivatives of the Arnaud Legoux Moving Average (ALMA) with respect to Time. Both the ALMA parameters and the time variable can be modified in the indicator's settings.
derivatives "physics":
Blue - ALMA Velocity (dALMA / dt)
Magenta - ALMA Acceleration (d_Velocity / dt)
White - ALMA Jerk (d_Acceleration / dt)
The indicator may be used to gauge market momentum. The simple code can also be used for pedagogical purposes for anyone interested in developing indicators in TradingView.

Forecasting - Drift MethodIntroduction
Nothing fancy in terms of code, take this post as an educational post where i provide information rather than an useful tool.
Time-Series Forecasting And The Drift Method
In time-series analysis one can use many many forecasting methods, some share similarities but they can all by classified in groups and sub-groups, the drift method is a forecasting method that unlike averages/naive methods does not have a constant (flat) forecast, instead the drift method can increase or decrease over time, this is why its a great method when it comes to forecasting linear trends.
Basically a drift forecast is like a linear extrapolation, first you take the first and last point of your data and draw a line between those points, extend this line into the future and you have a forecast, thats pretty much it.
One of the advantage of this method is first its simplicity, everyone could do it by hand without any mathematical calculations, then its ability to be non-conservative, conservative methods involve methods that fit the data very well such as linear/non-linear regression that best fit a curve to the data using the method of least-squares, those methods take into consideration all the data points, however the drift method only care about the first and last point.
Understanding Bias And Variance
In order to follow with the ability of methods to be non-conservative i want to introduce the concept of bias and variance, which are essentials in time-series analysis and machine learning.
First lets talk about training a model, when forecasting a time-series we can divide our data set in two, the first part being the training set and the second one the testing set. In the training set we fit a model to the training data, for example :
We use 200 data points, we split this set in two sets, the first one is for training which is in blue, and the other one for testing which is in green.
Basically the Bias is related to how well a forecasting model fit the training set, while the variance is related to how well the model fit the testing set. In our case we can see that the drift line does not fit the training set very well, it is then said to have high bias. If we check the testing set :
We can see that it does not fit the testing set very well, so the model is said to have high variance. It can be better to talk of bias and variance when using regression, but i think you get it. This is an important concept in machine learning, you'll often see the term "overfitting" which relate to a model fitting the training set really well, those models have a low to no bias, however when it comes to testing they don't fit well at all, they have high variance.
Conclusion On The Drift Method
The drift method is good at forecasting linear trends, and thats all...you see, when forecasting financial data you need models that are able to capture the complexity of the price structure as well as being robust to noise and outliers, the drift method isn't able to capture such complexity, its not a super smart method, same goes for linear regression. This is why more peoples are switching to more advanced models such a neural networks that can sometimes capture such complexity and return decent results.
So this method might not be the best but if you like lines then here you go.

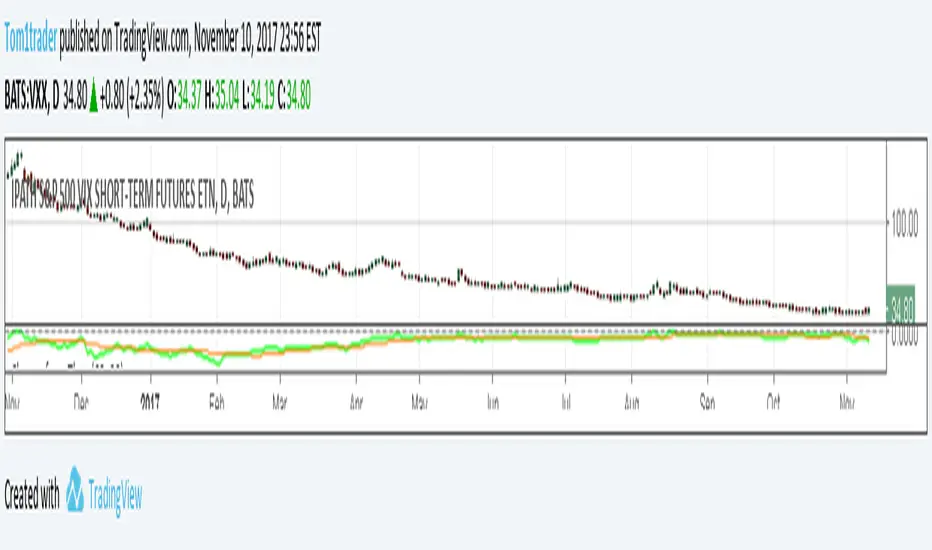
Change Per Period - Tom1traderwww.tradingview.com
Plots the values between current close and close (specified number of periods) ago. User chooses the period defaulted to 1 and the period of a simple moving average of the values in the series. Made this specifically to measure the drift of the VIX exchange traded funds VXX, UVXY and SVXY. The fact that they must drift can be strategic in trading.
In the chart example it shows that VXX drifts down usually between -$10 and -$20 over a 60 day period (eyeball) and that for a few days in February of 2017 it had drifted down -$75. To find a positive change (briefly) you can see you have to go back to November of 2016. If you use Heiken Ashi candles or ohlc bars or change between regular candles and these there is a set of variables in this code that lets you do that without changing your indicator results. Anyhow use it or any of the code if it helps you, good luck with your trading and keep smiling! (any feedback appreciated also :-) )