[blackcat] L2 Ehlers Three Pole Super SmootherLevel: 2
Background
John F. Ehlers introuced Three Pole Super Smoother in his "Cybernetic Analysis for Stocks and Futures" chapter 13 on 2004.
Function
The Super Smoother filter is formed by retaining the IIR part of a Butterworth digital filter. The order of Super Smoother filters can be increased indefinitely to increase the sharpness of the filter rejection, just as with Butterworth filters. A three-pole Super Smoother filter has far more attenuation in the reject band than the two-pole filters
Key Signal
Filt3 ---> Three Pole Super Smoother fast line
Trigger ---> Three Pole Super Smoother slow line
Pros and Cons
100% John F. Ehlers definition translation of original work, even variable names are the same. This help readers who would like to use pine to read his book. If you had read his works, then you will be quite familiar with my code style.
Remarks
The 32th script for Blackcat1402 John F. Ehlers Week publication.
Readme
In real life, I am a prolific inventor. I have successfully applied for more than 60 international and regional patents in the past 12 years. But in the past two years or so, I have tried to transfer my creativity to the development of trading strategies. Tradingview is the ideal platform for me. I am selecting and contributing some of the hundreds of scripts to publish in Tradingview community. Welcome everyone to interact with me to discuss these interesting pine scripts.
The scripts posted are categorized into 5 levels according to my efforts or manhours put into these works.
Level 1 : interesting script snippets or distinctive improvement from classic indicators or strategy. Level 1 scripts can usually appear in more complex indicators as a function module or element.
Level 2 : composite indicator/strategy. By selecting or combining several independent or dependent functions or sub indicators in proper way, the composite script exhibits a resonance phenomenon which can filter out noise or fake trading signal to enhance trading confidence level.
Level 3 : comprehensive indicator/strategy. They are simple trading systems based on my strategies. They are commonly containing several or all of entry signal, close signal, stop loss, take profit, re-entry, risk management, and position sizing techniques. Even some interesting fundamental and mass psychological aspects are incorporated.
Level 4 : script snippets or functions that do not disclose source code. Interesting element that can reveal market laws and work as raw material for indicators and strategies. If you find Level 1~2 scripts are helpful, Level 4 is a private version that took me far more efforts to develop.
Level 5 : indicator/strategy that do not disclose source code. private version of Level 3 script with my accumulated script processing skills or a large number of custom functions. I had a private function library built in past two years. Level 5 scripts use many of them to achieve private trading strategy.
Supersmoother

[blackcat] L2 Ehlers Two Pole Super SmootherLevel: 2
Background
John F. Ehlers introuced Two Pole Super Smoother in his "Cybernetic Analysis for Stocks and Futures" chapter 13 on 2004.
Function
The transfer response of the two-pole Super Smoother is almost identical to the transfer response of the Regularized filter. The difference between the two is that the characteristics of the Super Smoother are determined by a single parameter and the flatness of the passband response is guaranteed. The order of Super Smoother filters can be increased indefinitely to increase the sharpness of the filter rejection, just as with Butterworth filters.
Key Signal
Filt2 ---> Two Pole Super Smoother fast line
Trigger ---> Two Pole Super Smoother slow line
Pros and Cons
100% John F. Ehlers definition translation of original work, even variable names are the same. This help readers who would like to use pine to read his book. If you had read his works, then you will be quite familiar with my code style.
Remarks
The 31th script for Blackcat1402 John F. Ehlers Week publication.
Readme
In real life, I am a prolific inventor. I have successfully applied for more than 60 international and regional patents in the past 12 years. But in the past two years or so, I have tried to transfer my creativity to the development of trading strategies. Tradingview is the ideal platform for me. I am selecting and contributing some of the hundreds of scripts to publish in Tradingview community. Welcome everyone to interact with me to discuss these interesting pine scripts.
The scripts posted are categorized into 5 levels according to my efforts or manhours put into these works.
Level 1 : interesting script snippets or distinctive improvement from classic indicators or strategy. Level 1 scripts can usually appear in more complex indicators as a function module or element.
Level 2 : composite indicator/strategy. By selecting or combining several independent or dependent functions or sub indicators in proper way, the composite script exhibits a resonance phenomenon which can filter out noise or fake trading signal to enhance trading confidence level.
Level 3 : comprehensive indicator/strategy. They are simple trading systems based on my strategies. They are commonly containing several or all of entry signal, close signal, stop loss, take profit, re-entry, risk management, and position sizing techniques. Even some interesting fundamental and mass psychological aspects are incorporated.
Level 4 : script snippets or functions that do not disclose source code. Interesting element that can reveal market laws and work as raw material for indicators and strategies. If you find Level 1~2 scripts are helpful, Level 4 is a private version that took me far more efforts to develop.
Level 5 : indicator/strategy that do not disclose source code. private version of Level 3 script with my accumulated script processing skills or a large number of custom functions. I had a private function library built in past two years. Level 5 scripts use many of them to achieve private trading strategy.

Polynomial Regression Bands + Channel [DW]This is an experimental study designed to calculate polynomial regression for any order polynomial that TV is able to support.
This study aims to educate users on polynomial curve fitting, and the derivation process of Least Squares Moving Averages (LSMAs).
I also designed this study with the intent of showcasing some of the capabilities and potential applications of TV's fantastic new array functions.
Polynomial regression is a form of regression analysis in which the relationship between the independent variable x and the dependent variable y is modeled as a polynomial of nth degree (order).
For clarification, linear regression can also be described as a first order polynomial regression. The process of deriving linear, quadratic, cubic, and higher order polynomial relationships is all the same.
In addition, although deriving a polynomial regression equation results in a nonlinear output, the process of solving for polynomials by least squares is actually a special case of multiple linear regression.
So, just like in multiple linear regression, polynomial regression can be solved in essentially the same way through a system of linear equations.
In this study, you are first given the option to smooth the input data using the 2 pole Super Smoother Filter from John Ehlers.
I chose this specific filter because I find it provides superior smoothing with low lag and fairly clean cutoff. You can, of course, implement your own filter functions to see how they compare if you feel like experimenting.
Filtering noise prior to regression calculation can be useful for providing a more stable estimation since least squares regression can be rather sensitive to noise.
This is especially true on lower sampling lengths and higher degree polynomials since the regression output becomes more "overfit" to the sample data.
Next, data arrays are populated for the x-axis and y-axis values. These are the main datasets utilized in the rest of the calculations.
To keep the calculations more numerically stable for higher periods and orders, the x array is filled with integers 1 through the sampling period rather than using current bar numbers.
This process can be thought of as shifting the origin of the x-axis as new data emerges.
This keeps the axis values significantly lower than the 10k+ bar values, thus maintaining more numerical stability at higher orders and sample lengths.
The data arrays are then used to create a pseudo 2D matrix of x power sums, and a vector of x power*y sums.
These matrices are a representation the system of equations that need to be solved in order to find the regression coefficients.
Below, you'll see some examples of the pattern of equations used to solve for our coefficients represented in augmented matrix form.
For example, the augmented matrix for the system equations required to solve a second order (quadratic) polynomial regression by least squares is formed like this:
(∑x^0 ∑x^1 ∑x^2 | ∑(x^0)y)
(∑x^1 ∑x^2 ∑x^3 | ∑(x^1)y)
(∑x^2 ∑x^3 ∑x^4 | ∑(x^2)y)
The augmented matrix for the third order (cubic) system is formed like this:
(∑x^0 ∑x^1 ∑x^2 ∑x^3 | ∑(x^0)y)
(∑x^1 ∑x^2 ∑x^3 ∑x^4 | ∑(x^1)y)
(∑x^2 ∑x^3 ∑x^4 ∑x^5 | ∑(x^2)y)
(∑x^3 ∑x^4 ∑x^5 ∑x^6 | ∑(x^3)y)
This pattern continues for any n ordered polynomial regression, in which the coefficient matrix is a n + 1 wide square matrix with the last term being ∑x^2n, and the last term of the result vector being ∑(x^n)y.
Thanks to this pattern, it's rather convenient to solve the for our regression coefficients of any nth degree polynomial by a number of different methods.
In this script, I utilize a process known as LU Decomposition to solve for the regression coefficients.
Lower-upper (LU) Decomposition is a neat form of matrix manipulation that expresses a 2D matrix as the product of lower and upper triangular matrices.
This decomposition method is incredibly handy for solving systems of equations, calculating determinants, and inverting matrices.
For a linear system Ax=b, where A is our coefficient matrix, x is our vector of unknowns, and b is our vector of results, LU Decomposition turns our system into LUx=b.
We can then factor this into two separate matrix equations and solve the system using these two simple steps:
1. Solve Ly=b for y, where y is a new vector of unknowns that satisfies the equation, using forward substitution.
2. Solve Ux=y for x using backward substitution. This gives us the values of our original unknowns - in this case, the coefficients for our regression equation.
After solving for the regression coefficients, the values are then plugged into our regression equation:
Y = a0 + a1*x + a1*x^2 + ... + an*x^n, where a() is the ()th coefficient in ascending order and n is the polynomial degree.
From here, an array of curve values for the period based on the current equation is populated, and standard deviation is added to and subtracted from the equation to calculate the channel high and low levels.
The calculated curve values can also be shifted to the left or right using the "Regression Offset" input
Changing the offset parameter will move the curve left for negative values, and right for positive values.
This offset parameter shifts the curve points within our window while using the same equation, allowing you to use offset datapoints on the regression curve to calculate the LSMA and bands.
The curve and channel's appearance is optionally approximated using Pine's v4 line tools to draw segments.
Since there is a limitation on how many lines can be displayed per script, each curve consists of 10 segments with lengths determined by a user defined step size. In total, there are 30 lines displayed at once when active.
By default, the step size is 10, meaning each segment is 10 bars long. This is because the default sampling period is 100, so this step size will show the approximate curve for the entire period.
When adjusting your sampling period, be sure to adjust your step size accordingly when curve drawing is active if you want to see the full approximate curve for the period.
Note that when you have a larger step size, you will see more seemingly "sharp" turning points on the polynomial curve, especially on higher degree polynomials.
The polynomial functions that are calculated are continuous and differentiable across all points. The perceived sharpness is simply due to our limitation on available lines to draw them.
The approximate channel drawings also come equipped with style inputs, so you can control the type, color, and width of the regression, channel high, and channel low curves.
I also included an input to determine if the curves are updated continuously, or only upon the closing of a bar for reduced runtime demands. More about why this is important in the notes below.
For additional reference, I also included the option to display the current regression equation.
This allows you to easily track the polynomial function you're using, and to confirm that the polynomial is properly supported within Pine.
There are some cases that aren't supported properly due to Pine's limitations. More about this in the notes on the bottom.
In addition, I included a line of text beneath the equation to indicate how many bars left or right the calculated curve data is currently shifted.
The display label comes equipped with style editing inputs, so you can control the size, background color, and text color of the equation display.
The Polynomial LSMA, high band, and low band in this script are generated by tracking the current endpoints of the regression, channel high, and channel low curves respectively.
The output of these bands is similar in nature to Bollinger Bands, but with an obviously different derivation process.
By displaying the LSMA and bands in tandem with the polynomial channel, it's easy to visualize how LSMAs are derived, and how the process that goes into them is drastically different from a typical moving average.
The main difference between LSMA and other MAs is that LSMA is showing the value of the regression curve on the current bar, which is the result of a modelled relationship between x and the expected value of y.
With other MA / filter types, they are typically just averaging or frequency filtering the samples. This is an important distinction in interpretation. However, both can be applied similarly when trading.
An important distinction with the LSMA in this script is that since we can model higher degree polynomial relationships, the LSMA here is not limited to only linear as it is in TV's built in LSMA.
Bar colors are also included in this script. The color scheme is based on disparity between source and the LSMA.
This script is a great study for educating yourself on the process that goes into polynomial regression, as well as one of the many processes computers utilize to solve systems of equations.
Also, the Polynomial LSMA and bands are great components to try implementing into your own analysis setup.
I hope you all enjoy it!
--------------------------------------------------------
NOTES:
- Even though the algorithm used in this script can be implemented to find any order polynomial relationship, TV has a limit on the significant figures for its floating point outputs.
This means that as you increase your sampling period and / or polynomial order, some higher order coefficients will be output as 0 due to floating point round-off.
There is currently no viable workaround for this issue since there isn't a way to calculate more significant figures than the limit.
However, in my humble opinion, fitting a polynomial higher than cubic to most time series data is "overkill" due to bias-variance tradeoff.
Although, this tradeoff is also dependent on the sampling period. Keep that in mind. A good rule of thumb is to aim for a nice "middle ground" between bias and variance.
If TV ever chooses to expand its significant figure limits, then it will be possible to accurately calculate even higher order polynomials and periods if you feel the desire to do so.
To test if your polynomial is properly supported within Pine's constraints, check the equation label.
If you see a coefficient value of 0 in front of any of the x values, reduce your period and / or polynomial order.
- Although this algorithm has less computational complexity than most other linear system solving methods, this script itself can still be rather demanding on runtime resources - especially when drawing the curves.
In the event you find your current configuration is throwing back an error saying that the calculation takes too long, there are a few things you can try:
-> Refresh your chart or hide and unhide the indicator.
The runtime environment on TV is very dynamic and the allocation of available memory varies with collective server usage.
By refreshing, you can often get it to process since you're basically just waiting for your allotment to increase. This method works well in a lot of cases.
-> Change the curve update frequency to "Close Only".
If you've tried refreshing multiple times and still have the error, your configuration may simply be too demanding of resources.
v4 drawing objects, most notably lines, can be highly taxing on the servers. That's why Pine has a limit on how many can be displayed in the first place.
By limiting the curve updates to only bar closes, this will significantly reduce the runtime needs of the lines since they will only be calculated once per bar.
Note that doing this will only limit the visual output of the curve segments. It has no impact on regression calculation, equation display, or LSMA and band displays.
-> Uncheck the display boxes for the drawing objects.
If you still have troubles after trying the above options, then simply stop displaying the curve - unless it's important to you.
As I mentioned, v4 drawing objects can be rather resource intensive. So a simple fix that often works when other things fail is to just stop them from being displayed.
-> Reduce sampling period, polynomial order, or curve drawing step size.
If you're having runtime errors and don't want to sacrifice the curve drawings, then you'll need to reduce the calculation complexity.
If you're using a large sampling period, or high order polynomial, the operational complexity becomes significantly higher than lower periods and orders.
When you have larger step sizes, more historical referencing is used for x-axis locations, which does have an impact as well.
By reducing these parameters, the runtime issue will often be solved.
Another important detail to note with this is that you may have configurations that work just fine in real time, but struggle to load properly in replay mode.
This is because the replay framework also requires its own allotment of runtime, so that must be taken into consideration as well.
- Please note that the line and label objects are reprinted as new data emerges. That's simply the nature of drawing objects vs standard plots.
I do not recommend or endorse basing your trading decisions based on the drawn curve. That component is merely to serve as a visual reference of the current polynomial relationship.
No repainting occurs with the Polynomial LSMA and bands though. Once the bar is closed, that bar's calculated values are set.
So when using the LSMA and bands for trading purposes, you can rest easy knowing that history won't change on you when you come back to view them.
- For those who intend on utilizing or modifying the functions and calculations in this script for their own scripts, I included debug dialogues in the script for all of the arrays to make the process easier.
To use the debugs, see the "Debugs" section at the bottom. All dialogues are commented out by default.
The debugs are displayed using label objects. By default, I have them all located to the right of current price.
If you wish to display multiple debugs at once, it will be up to you to decide on display locations at your leisure.
When using the debugs, I recommend commenting out the other drawing objects (or even all plots) in the script to prevent runtime issues and overlapping displays.

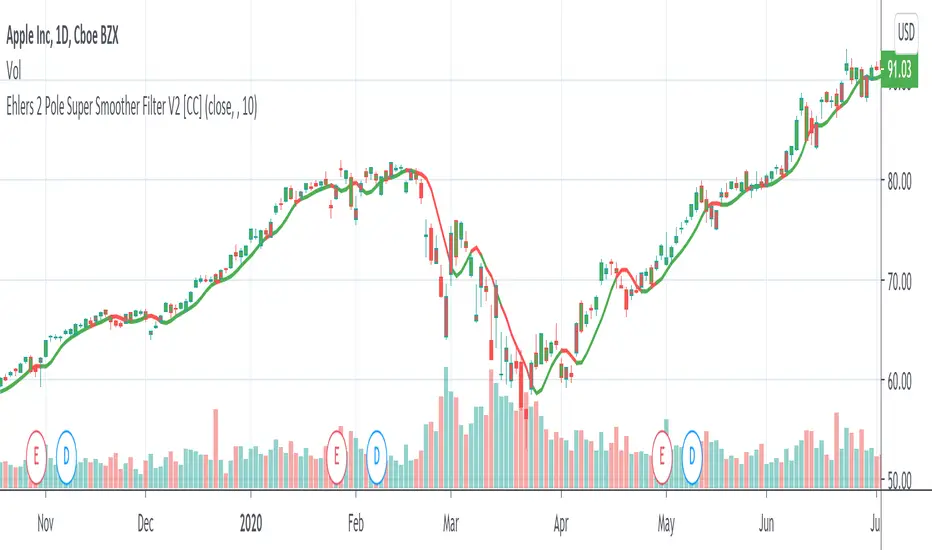
Ehlers 2 Pole Super Smoother Filter V2 [CC]The 2 Pole Super Smoother Filter was created by John Ehlers (Cycle Analytics For Traders pg 32) and this follows the price very closely and very useful because it is consistent with uptrends and falls sharply during a sudden downtrend so it should be able to help you stay more profitable. Buy when the indicator line turns green and sell when it turns red.
Let me know if there are other indicators you would like to see me publish or if you want something custom done!
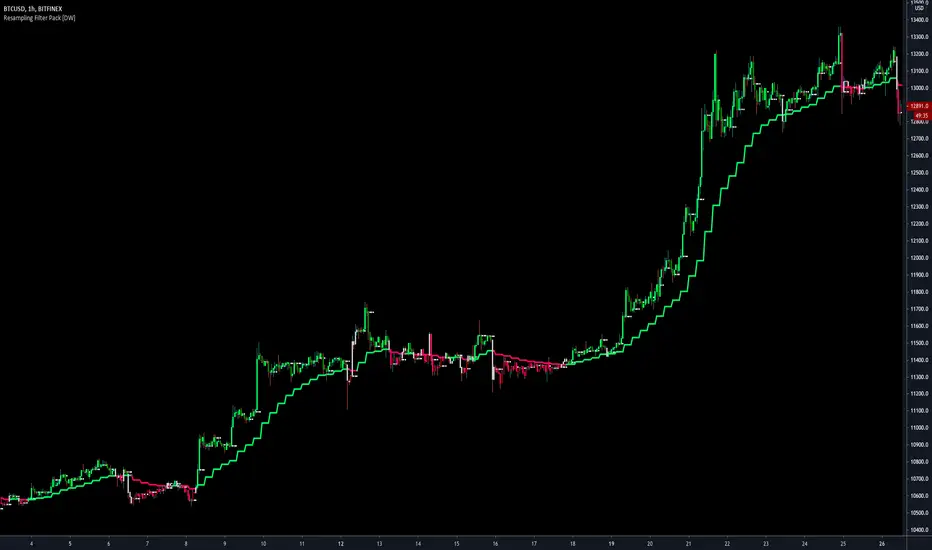
Resampling Filter Pack [DW]This is an experimental study that calculates filter values at user defined sample rates.
This study is aimed to provide users with alternative functions for filtering price at custom sample rates.
First, source data is resampled using the desired rate and cycle offset. The highest possible rate is 1 bar per sample (BPS).
There are three resampling methods to choose from:
-> BPS - Resamples based on the number of bars.
-> Interval - Resamples based on time in multiples of current charting timeframe.
-> PA - Resamples based on changes in price action by a specified size. The PA algorithm in this script is derived from my Range Filter algorithm.
The range for PA method can be sized in points, pips, ticks, % of price, ATR, average change, and absolute quantity.
Then, the data is passed through one of my custom built filter functions designed to calculate filter values upon trigger conditions rather than bars.
In this study, these functions are used to calculate resampled prices based on bar rates, but they can be used and modified for a number of purposes.
The available conditional sampling filters in this study are:
-> Simple Moving Average (SMA)
-> Exponential Moving Average (EMA)
-> Zero Lag Exponential Moving Average (ZLEMA)
-> Double Exponential Moving Average (DEMA)
-> Rolling Moving Average (RMA)
-> Weighted Moving Average (WMA)
-> Hull Moving Average (HMA)
-> Exponentially Weighted Hull Moving Average (EWHMA)
-> Two Pole Butterworth Low Pass Filter (BLP)
-> Two Pole Gaussian Low Pass Filter (GLP)
-> Super Smoother Filter (SSF)
Downsampling is a powerful filtering approach that can be applied in numerous ways. However, it does suffer from a trade off, like most studies do.
Reducing the sample rate will completely eliminate certain levels of noise, at the cost of some spectral distortion. The lower your sample rate is, the more distortion you'll see.
With that being said, for analyzing trends, downsampling may prove to be one of your best friends!
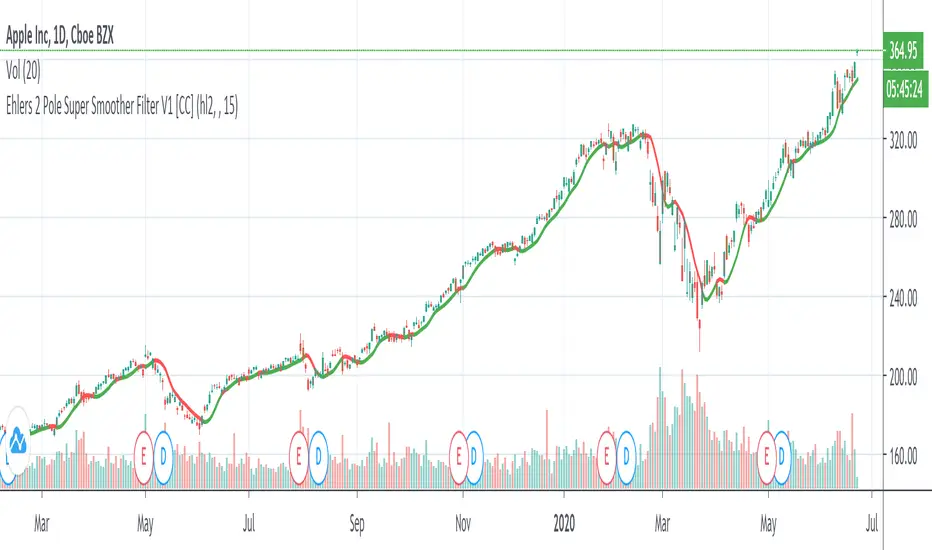
Ehlers 2 Pole Super Smoother Filter V1 [CC]The 2 Pole Super Smoother Filter was created by John Ehlers (Cybernetic Analysis For Stocks And Futures pg 202) and this one of his filters that follows the price very closely. I would recommend to change the default settings to what fits your trading style the best. Buy when the indicator line turns green and sell when it turns red.
Let me know if there are other scripts you would like to see or if you want something custom done!
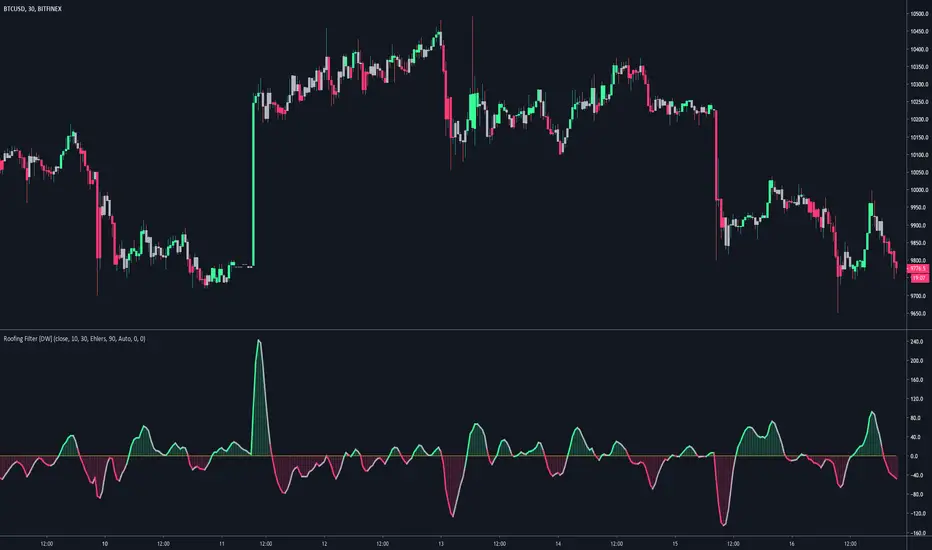
Roofing Filter [DW]This is an experimental study built on the concept of using roofing filters on price data proposed by John Ehlers.
Roofing filters are a type of bandpass filter conventionally used in HF radio receivers in the first IF stage to limit the frequency spectrum passed on to later stages in the receiver.
The goal in applying roofing filters to a price signal is to simultaneously attenuate high frequency noise and low frequency distortion to pass an oscillating signal with a nearly zero mean for analysis and/or further calculation.
In this study, there are three filter types to choose from:
-> Ehlers Roofing Filter, which passes data through a 2 pole high pass filter, then through a Super Smoother filter.
-> Gaussian Roofing Filter, which passes data through a 2 pole Gaussian high pass filter, then through a 2 pole Gaussian low pass filter.
-> Butterworth Roofing Filter, which passes data through a 2 pole Butterworth high pass filter, then through a 2 pole Butterworth low pass filter.
Each filter type has different amplitude and delay characteristics, so play around with each type and see which response suits your needs best.
There is an option to normalize the scale of the output as well. The normalization process in this script is computed by comparing positive and negative outputs to the filter's moving RMS value.
The resulting oscillator can be fed through numerous conventional indicators including Stochastic Oscillator, RSI, CCI, etc. to generate smoother, less distorted indicators for a clearer view of turning points.
Alternatively, it can also act as an indicator itself, as implied by the corresponding color scheme included in the script.
Although roofing filters are not conventionally used in the analysis of market data, applying such spectral analysis techniques may prove to be quite useful for the design of more efficient indicators and more reliable predictions.
Turtle IndexThis Indicator is a combination of Super Smoother Filter and Bollinger Bands %B.
This Indicator is used in Trend-Momentum gauging. Use this indicator with Turtle Oscillator.

Ehler's Super Smoother 2 and 3 pole (properly initialized)John Ehlers' Super Smoother 2 and 3 pole - properly initialized
www.stockspotter.com
Failure to properly initialize early values of the super smoother will result in misleading values early in the output.
Because the SS is an IIR ( infinite impulse response) filter, this error can ring in the filter for a long time, but
is extremely evident in the first 2*len bars.
This is an implementation if the 2 and 3 pole SS filter, with special attention to initializing the early values.
It uses (src+scr)/2 per Ehlers but contains code to just use src if you prefer to calculate that outside
the function as everget does in his SS here:
there is code included to make that change.
Many thanks to everget for his terrific implementations of much of John Ehlers' work. It has been tremendously helpful to me.

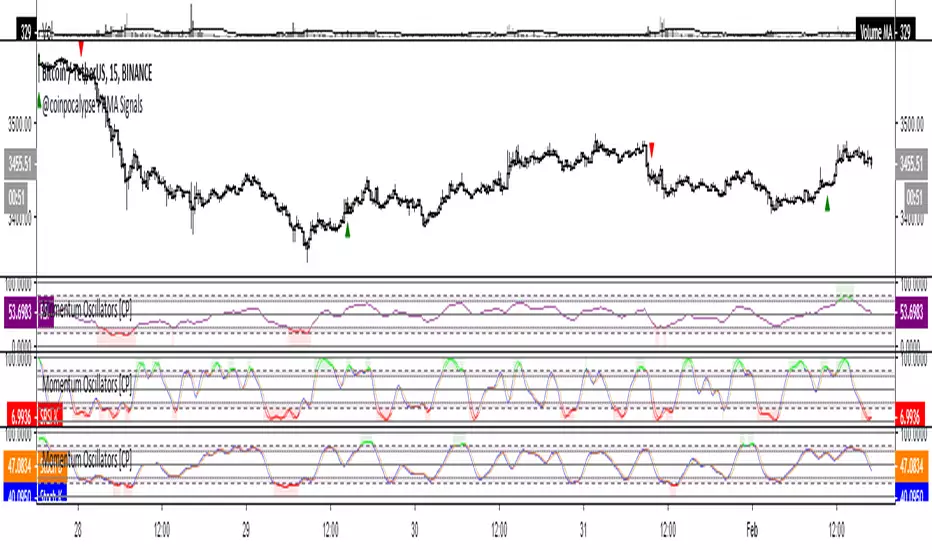
Momentum Oscillators [CP]This is collection of 3 Momentum Oscillators:
*RSI
*Stochastic
*SRSI
You can filter each one with the following options:
*SMA
*EMA
*Hull MA
*Linear Regression
*Laguerre
*SuperSmoother
*SuperSmoother
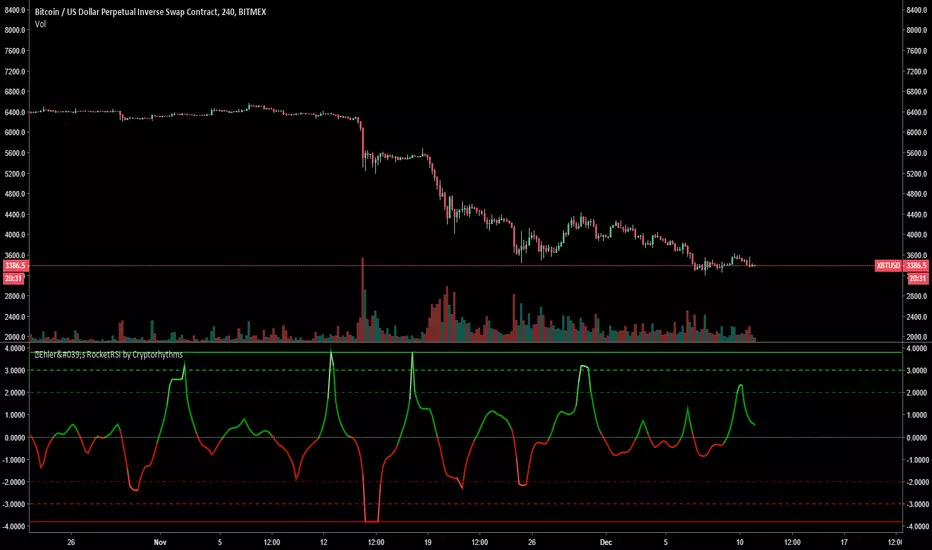
🚀Ehler's RocketRSI by Cryptorhythms🚀Ehler's RocketRSI by Cryptorhythms
This indicator does require some tinkering in cases to line up the waveforms. Here on the 4Hr I have used an RSI LB of 14 and SSF LB of 10.
Personally I find its better at picking short entries when the indicator is topping out. For bottoms it a bit less effective.
I do not use this indicator by itself, but rather as another tool when looking for short entries.
Description
The RocketRSI is an indicator that combines the approach used in the calculation of the Relative Strength Index (RSI) with some principles of signal processing and was developed by John Ehler. By smoothing out noisy price data and singling out a cyclic component within it, the indicator can be used for analysis of cyclic reversals, which could potentially signal trading
opportunities.
The calculation of the RocketRSI is as follows:
A close price change (momentum) from a past value is found for each bar. The offset between the current and the past price is constant.
The values found are run through Ehler
s 3-Pole SuperSmootherFilter to eliminate the noise.
The algebraic sum of one-bar changes in the filtered values is divided by the sum of absolute values of the same changes. The output of this step is limited to be in the range from -0.999 to +0.999.
The result is run through the Fisher transform to provide a easily interpreted wave-like output.
If there is a dominant cycle in the input data and the lengths are set correctly, the analysis of peaks and troughs of the output wave may provide valuable sell and buy signals.
👍Enjoying this indicator or find it useful? Please give me a like and follow! I post crypto analysis, price action strategies and free indicators regularly.
💬Questions? Comments? Want to get access to an entire suite of proven trading indicators? Come visit us on telegram and chat, or just soak up some knowledge. We make timely posts about the market, news, and strategy everyday. Our community isnt open only to subscribers - everyone is welcome to join.
Ehlers Smoothed Adaptive MomentumEhlers Smoothed Adaptive Momentum script.
This indicator was developed and described by John F. Ehlers in his book "Cybernetic Analysis for Stocks and Futures" (2004, Chapter 12: Adapting to the Trend).

Ehlers Fisherized Deviation-Scaled OscillatorEhlers Fisherized Deviation-Scaled Oscillator script.
This indicator was originally developed by John F. Ehlers (Stocks & Commodities V. 36:11: Probability - Probably A Good Thing To Know).

Ehlers StochasticEhlers Stochastic script.
This indicator was originally developed by John F. Ehlers (Stocks & Commodities V. 32:1: Predictive And Successful Indicators).

Ehlers Roofing FilterEhlers Roofing Filter script.
This indicator was originally developed by John F. Ehlers (Stocks & Commodities V. 32:1: Predictive And Successful Indicators).
Ehlers Super Smoother FilterEhlers Super Smoother Filter script.
This indicator was originally developed by John F. Ehlers (see his book `Cybernetic Analysis for Stocks and Futures`, Chapter 13: `Super Smoothers`).

Ehlers Deviation-Scaled Moving Average (DSMA)Ehlers Deviation-Scaled Moving Average indicator script.
This indicator was originally developed by John F. Ehlers (Stocks & Commodities V. 36:8: The Deviation-Scaled Moving Average).

Fisher Transform SuperSmoothed MACD // This is a modification of Supersmoothed MACD (created by KIVANC using EHLERS' SUPER SMOOTHER FILTER) and sharpenned with Ehler fisher transform
//all lengths and parameters are completely configurable, tune the length according to your instrument
//give me what you think

Rocket RSIRocket RSI indicator script.
This indicator was originally developed by John Ehlers (Stocks & Commodities V.36:6, RocketRSI - A Solid Propellant For Your Rocket Science Trading).

Ehler's Super Smoother strategyThis strategy is a mean-reversal strategy based on John F. Ehlers's Super Smoother filter. I tried it on 15m timeframe with 'Recalculate After Order Filled' option checked.
Moving Average Bundle3 Moving Average Lines. All parameters are configurable via user input.
Each of these moving average lines already exist as individual indicators in TradingView. This script just bundles them for one stop shopping. It's helpful if you're limited by the number of indicators per chart. And highly educational: quickly compare the different averaging methods!
sma: Simple Moving Average
rma: Recursive Moving Average
ema: Exponential Moving Average
wma: Weighted Moving Average
vma: Volume Weighted Moving Average
wma: Weighted Moving Average
alma: Arnaud Legoux Moving Average
Note: Only Pine built-in functions are included.
Super Smoothed MACD for STOCKS by KIVANÇ fr3762THIS INDICATOR IS DESIGNED USING EHLERS' SUPER SMOOTHER FILTER
DESIGNED FOR STOCKS
(another version available for CRYPTO TRADE: Super Smoothed MACD for CRYPTO by KIVANÇ fr3762)
Instead of EXPONENTIAL MOVING AVERAGES in traditional MACD calculation, Super Smoothed prices are used.
The default values of BAND EDGE's (periods) of these Super Smoothed Prices are 13,8, and 3 (Fibonacci numbers) which pretty work well for daily trade
users can change these values 13,8,5 or 21,13,5 or 21,13,8 and so on to have optimum trade productivity

Super Smoothed MACD for CRYPTO by KIVANÇ fr3762THIS INDICATOR IS DESIGNED USING EHLERS' SUPER SMOOTHER FILTER
DESIGNED FOR CRYPTO TRADE
(another version available for stocks also: Super Smoothed MACD for STOCKS by KIVANÇ fr3762)
Instead of EXPONENTIAL MOVING AVERAGES in traditional MACD calculation, Super Smoothed prices are used.
The default values of BAND EDGE's (periods) of these Super Smoothed Prices are 13,8, and 5 (Fibonacci numbers) which pretty work well for daily trade
users can change these values 13,8,3 or 21,13,5 or 21,13,8 and so on to have optimum trade productivity
