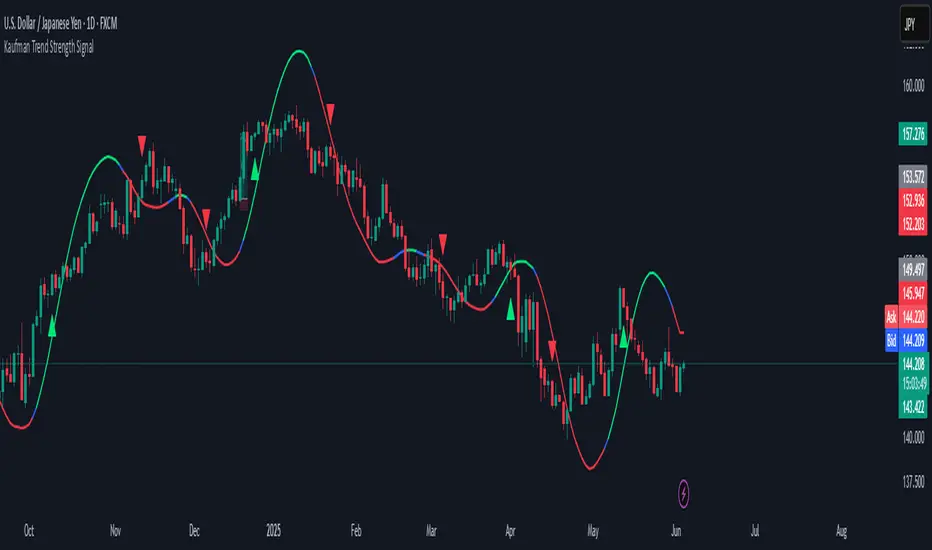
Kaufman Trend Strength Signal█ Overview
Kaufman Trend Strength Signal is an advanced trend detection tool that decomposes price action into its underlying directional trend and localized oscillation using a vector-based Kalman Filter.
By integrating adaptive smoothing and dynamic weighting via a weighted moving average (WMA), this indicator provides real-time insight into both trend direction and trend strength — something standard moving averages often fail to capture.
The core model assumes that observed price consists of two components:
(1) a directional trend, and
(2) localized noise or oscillation.
Using a two-step Predict & Update cycle, the filter continuously refines its trend estimate as new market data becomes available.
█ How It Works
This indicator employs a Kalman Filter model that separates the trend from short-term fluctuations in a price series.
Predict & Update Cycle : With each new bar, the filter predicts the price state and updates that prediction using the latest observed price, producing a smooth but adaptive trend line.
Trend Strength Normalization : Internally, the oscillator component is normalized against recent values (N periods) to calculate a trend strength score between -100 and +100.
(Note: The oscillator is not plotted on the chart but is used for signal generation.)
Filtered MA Line : The trend component is plotted as a smooth Kalman Filter-based moving average (MA) line on the main chart.
Threshold Cross Signals : When the internal trend strength crosses a user-defined threshold (default: ±60), visual entry arrows are displayed to signal momentum shifts.
█ Key Features
Adaptive Trend Estimation : Real-time filtering that adjusts dynamically to market changes.
Visual Buy/Sell Signals : Entry arrows appear when the trend strength crosses above or below the configured threshold.
Built-in Range Filter : The MA line turns blue when trend strength is weak (|value| < 10), helping you filter out choppy, sideways conditions.
█ How to Use
Trend Detection :
• Green MA = bullish trend
• Red MA = bearish trend
• Blue MA = no trend / ranging market
Entry Signals :
• Green triangle = trend strength crossed above +Threshold → potential bullish entry
• Red triangle = trend strength crossed below -Threshold → potential bearish entry
█ Settings
Entry Threshold : Level at which the trend strength triggers entry signals (default: 60)
Process Noise 1 & 2 : Control the filter’s responsiveness to recent price action. Higher = more reactive; lower = smoother.
Measurement Noise : Sets how much the filter "trusts" price data. High = smoother MA, low = faster response but more noise.
Trend Lookback (N2) : Number of bars used to normalize trend strength. Lower = more sensitive; higher = more stable.
Trend Smoothness (R2) : WMA smoothing applied to the trend strength calculation.
█ Visual Guide
Green MA Line → Bullish trend
Red MA Line → Bearish trend
Blue MA Line → Sideways/range
Green Triangle → Entry signal (trend strengthening)
Red Triangle → Entry signal (trend weakening)
█ Best Practices
In high-volatility conditions, increase Measurement Noise to reduce false signals.
Combine with other indicators (e.g., RSI, MACD, EMA) for confirmation and filtering.
Adjust "Entry Threshold" and noise settings depending on your timeframe and trading style.
❗ Disclaimer
This script is provided for educational purposes only and should not be considered financial advice or a recommendation to buy/sell any asset.
Trading involves risk. Past performance does not guarantee future results.
Always perform your own analysis and use proper risk management when trading.
Kalmanfilter
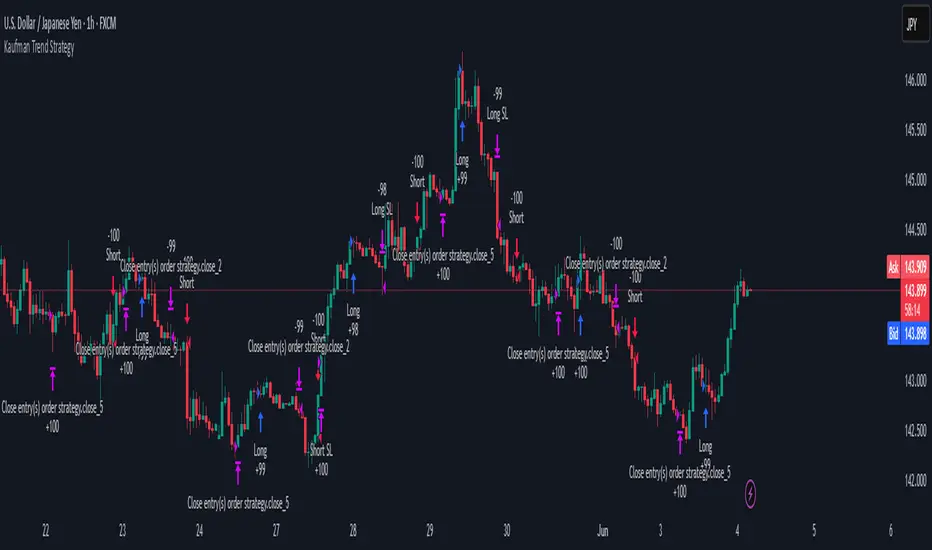
Kaufman Trend Strategy# ✅ Kaufman Trend Strategy – Full Description (Script Publishing Version)
**Kaufman Trend Strategy** is a dynamic trend-following strategy based on Kaufman Filter theory.
It detects real-time trend momentum, reduces noise, and aims to enhance entry accuracy while optimizing risk.
⚠️ _For educational and research purposes only. Past performance does not guarantee future results._
---
## 🎯 Strategy Objective
- Smooth price noise using Kaufman Filter smoothing
- Detect the strength and direction of trends with a normalized oscillator
- Manage profits using multi-stage take-profits and adaptive ATR stop-loss logic
---
## ✨ Key Features
- **Kaufman Filter Trend Detection**
Extracts directional signal using a state space model.
- **Multi-Stage Profit-Taking**
Automatically takes partial profits based on color changes and zero-cross events.
- **ATR-Based Volatility Stops**
Stops adjust based on swing highs/lows and current market volatility.
---
## 📊 Entry & Exit Logic
**Long Entry**
- `trend_strength ≥ 60`
- Green trend signal
- Price above the Kaufman average
**Short Entry**
- `trend_strength ≤ -60`
- Red trend signal
- Price below the Kaufman average
**Exit (Long/Short)**
- Blue trend color → TP1 (50%)
- Oscillator crosses 0 → TP2 (25%)
- Trend weakens → Final exit (25%)
- ATR + swing-based stop loss
---
## 💰 Risk Management
- Initial capital: `$3,000`
- Order size: `$100` per trade (realistic, low-risk sizing)
- Commission: `0.002%`
- Slippage: `2 ticks`
- Pyramiding: `1` max position
- Estimated risk/trade: `~0.1–0.5%` of equity
> ⚠️ _No trade risks more than 5% of equity. This strategy follows TradingView script publishing rules._
---
## ⚙️ Default Parameters
- **1st Take Profit**: 50%
- **2nd Take Profit**: 25%
- **Final Exit**: 25%
- **ATR Period**: 14
- **Swing Lookback**: 10
- **Entry Threshold**: ±60
- **Exit Threshold**: ±40
---
## 📅 Backtest Summary
- **Symbol**: USD/JPY
- **Timeframe**: 1H
- **Date Range**: Jan 3, 2022 – Jun 4, 2025
- **Trades**: 924
- **Win Rate**: 41.67%
- **Profit Factor**: 1.108
- **Net Profit**: +$1,659.29 (+54.56%)
- **Max Drawdown**: -$1,419.73 (-31.87%)
---
## ✅ Summary
This strategy uses Kaufman filtering to detect market direction with reduced lag and increased smoothness.
It’s built with visual clarity and strong trade management, making it practical for both beginners and advanced users.
---
## 📌 Disclaimer
This script is for educational and informational purposes only and should not be considered financial advice.
Use with proper risk controls and always test in a demo environment before live trading.
Kalman Filtered RSI | [DeV]The Kalman Filtered RSI indicator is an advanced tool designed for traders who want precise, noise-free market insights. By enhancing the classic Relative Strength Index (RSI) with a Kalman filter, this indicator delivers a smoother, more reliable view of market momentum, helping you identify trends, reversals, and overbought/oversold conditions with greater accuracy. It’s an ideal choice for traders seeking clear signals amidst market volatility, giving you a competitive edge across any trading environment.
The RSI measures momentum by analyzing price movements over a set period, typically 14 bars. It calculates the average of price gains on up days and the average of price losses on down days, then compares these to produce a value between 0 and 100. An RSI above 70 often indicates an overbought market that may reverse downward, while below 30 suggests an oversold market that could reverse upward. RSI is great for spotting momentum shifts, potential reversals, and trend strength, but it can be noisy in choppy markets, leading to misleading signals.
That's where the Kalman filter comes in; it enhances the RSI by applying a sophisticated smoothing process that predicts the RSI’s next value based on its historical trend, then updates this prediction with the actual RSI reading. It operates in two phases: prediction and correction. In the prediction phase, it uses the previous filtered RSI and adds uncertainty from process noise (Q), which is derived from the historical variance of RSI changes, reflecting how much the RSI might unexpectedly shift. In the correction phase, it calculates a Kalman gain based on the ratio of prediction uncertainty to measurement noise (R), which is determined from the variance between raw RSI and a smoothed version, indicating the raw data’s noisiness. This gain weights how much the filter trusts the new RSI versus the prediction, blending them to produce a smoothed RSI that reduces noise while staying responsive to real trends, outperforming simpler methods like moving averages that often lag or oversmooth.
With the Kalman Filtered RSI, you get a refined view of momentum, making it easier to spot trends and reversals with clarity. This indicator’s ability to dynamically adapt to market changes delivers timely, reliable signals, making it a powerful addition to your trading strategy for any market or timeframe.

KalmanfilterLibrary "Kalmanfilter"
A sophisticated Kalman Filter implementation for financial time series analysis
@author Rocky-Studio
@version 1.0
initialize(initial_value, process_noise, measurement_noise)
Initializes Kalman Filter parameters
Parameters:
initial_value (float) : (float) The initial state estimate
process_noise (float) : (float) The process noise coefficient (Q)
measurement_noise (float) : (float) The measurement noise coefficient (R)
Returns: A tuple containing
update(prev_state, prev_covariance, measurement, process_noise, measurement_noise)
Update Kalman Filter state
Parameters:
prev_state (float)
prev_covariance (float)
measurement (float)
process_noise (float)
measurement_noise (float)
calculate_measurement_noise(price_series, length)
Adaptive measurement noise calculation
Parameters:
price_series (array)
length (int)
calculate_measurement_noise_simple(price_series)
Parameters:
price_series (array)
update_trading(prev_state, prev_velocity, prev_covariance, measurement, volatility_window)
Enhanced trading update with velocity
Parameters:
prev_state (float)
prev_velocity (float)
prev_covariance (float)
measurement (float)
volatility_window (int)
model4_update(prev_mean, prev_speed, prev_covariance, price, process_noise, measurement_noise)
Kalman Filter Model 4 implementation (Benhamou 2018)
Parameters:
prev_mean (float)
prev_speed (float)
prev_covariance (array)
price (float)
process_noise (array)
measurement_noise (float)
model4_initialize(initial_price)
Initialize Model 4 parameters
Parameters:
initial_price (float)
model4_default_process_noise()
Create default process noise matrix for Model 4
model4_calculate_measurement_noise(price_series, length)
Adaptive measurement noise calculation for Model 4
Parameters:
price_series (array)
length (int)

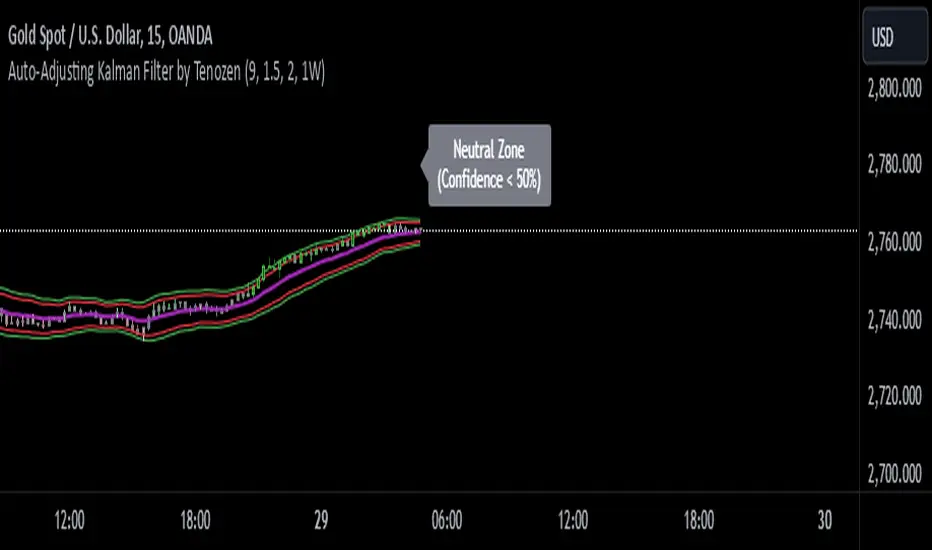
Auto-Adjusting Kalman Filter by TenozenNew year, new indicator! Auto-Adjusting Kalman Filter is an indicator designed to provide an adaptive approach to trend analysis. Using the Kalman Filter (a recursive algorithm used in signal processing), this algo dynamically adjusts to market conditions, offering traders a reliable way to identify trends and manage risk! In other words, it's a remaster of my previous indicator, Kalman Filter by Tenozen.
What's the difference with the previous indicator (Kalman Filter by Tenozen)?
The indicator adjusts its parameters (Q and R) in real-time using the Average True Range (ATR) as a measure of market volatility. This ensures the filter remains responsive during high-volatility periods and smooth during low-volatility conditions, optimizing its performance across different market environments.
The filter resets on a user-defined timeframe, aligning its calculations with dominant trends and reducing sensitivity to short-term noise. This helps maintain consistency with the broader market structure.
A confidence metric, derived from the deviation of price from the Kalman filter line (measured in ATR multiples), is visualized as a heatmap:
Green : Bullish confidence (higher values indicate stronger trends).
Red : Bearish confidence (higher values indicate stronger trends).
Gray : Neutral zone (low confidence, suggesting caution).
This provides a clear, objective measure of trend strength.
How it works?
The Kalman Filter estimates the "true" price by filtering out market noise. It operates in two steps, that is, prediction and update. Prediction is about projection the current state (price) forward. Update is about adjusting the prediction based on the latest price data. The filter's parameters (Q and R) are scaled using normalized ATR, ensuring adaptibility to changing market conditions. So it means that, Q (Process Noise) increases during high volatility, making the filter more responsive to price changes and R (Measurement Noise) increases during low volatility, smoothing out the filter to avoid overreacting to minor fluctuations. Also, the trend confidence is calculated based on the deviation of price from the Kalman filter line, measured in ATR multiples, this provides a quantifiable measure of trend strength, helping traders assess market conditions objectively.
How to use?
Use the Kalman Filter line to identify the prevailing trend direction. Trade in alignment with the filter's slope for higher-probability setups.
Look for pullbacks toward the Kalman Filter line during strong trends (high confidence zones)
Utilize the dynamic stop-loss and take-profit levels to manage risk and lock in profits
Confidence Heatmap provides an objective measure of market sentiment, helping traders avoid low-confidence (neutral) zones and focus on high-probability opportunities
Guess that's it! I hope this indicator helps! Let me know if you guys got some feedback! Ciao!
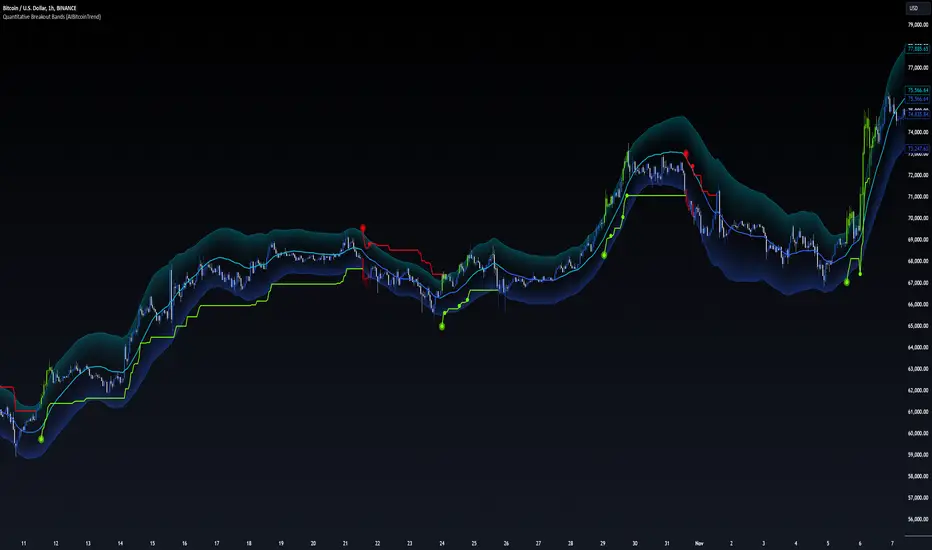
Quantitative Breakout Bands (AIBitcoinTrend)Quantitative Breakout Bands (AIBitcoinTrend) is an advanced indicator designed to adapt to dynamic market conditions by utilizing a Kalman filter for real-time data analysis and trend detection. This innovative tool empowers traders to identify price breakouts, evaluate trends, and refine their trading strategies with precision.
👽 What Are Quantitative Breakout Bands, and Why Are They Unique?
Quantitative Breakout Bands combine advanced filtering techniques (Kalman Filters) with statistical measures such as mean absolute error (MAE) to create adaptive price bands. These bands adjust to market conditions dynamically, providing insights into volatility, trend strength, and breakout opportunities.
What sets this indicator apart is its ability to incorporate both position (price) and velocity (rate of price change) into its calculations, making it highly responsive yet smooth. This dual consideration ensures traders get reliable signals without excessive lag or noise.
👽 The Math Behind the Indicator
👾 Kalman Filter Estimation:
At the core of the indicator is the Kalman Filter, a recursive algorithm used to predict the next state of a system based on past observations. It incorporates two primary elements:
State Prediction: The indicator predicts future price (position) and velocity based on previous values.
Error Covariance Adjustment: The process and measurement noise parameters refine the prediction's accuracy by balancing smoothness and responsiveness.
👾 Breakout Bands Calculation:
The breakout bands are derived from the mean absolute error (MAE) of price deviations relative to the filtered trendline:
float upperBand = kalmanPrice + bandMultiplier * mae
float lowerBand = kalmanPrice - bandMultiplier * mae
The multiplier allows traders to adjust the sensitivity of the bands to market volatility.
👾 Slope-Based Trend Detection:
A weighted slope calculation measures the gradient of the filtered price over a configurable window. This slope determines whether the market is trending bullish, bearish, or neutral.
👾 Trailing Stop Mechanism:
The trailing stop employs the Average True Range (ATR) to calculate dynamic stop levels. This ensures positions are protected during volatile moves while minimizing premature exits.
👽 How It Adapts to Price Movements
Dynamic Noise Calibration: By adjusting process and measurement noise inputs, the indicator balances smoothness (to reduce noise) with responsiveness (to adapt to sharp price changes).
Trend Responsiveness: The Kalman Filter ensures that trend changes are quickly identified, while the slope calculation adds confirmation.
Volatility Sensitivity: The MAE-based bands expand and contract in response to changes in market volatility, making them ideal for breakout detection.
👽 How Traders Can Use the Indicator
👾 Breakout Detection:
Bullish Breakouts: When the price moves above the upper band, it signals a potential upward breakout.
Bearish Breakouts: When the price moves below the lower band, it signals a potential downward breakout.
The trailing stop feature offers a dynamic way to lock in profits or minimize losses during trending moves.
👾 Trend Confirmation:
The color-coded Kalman line and slope provide visual cues:
Bullish Trend: Positive slope, green line.
Bearish Trend: Negative slope, red line.
👽 Why It’s Useful for Traders
Dynamic and Adaptive: The indicator adjusts to changing market conditions, ensuring relevance across timeframes and asset classes.
Noise Reduction: The Kalman Filter smooths price data, eliminating false signals caused by short-term noise.
Comprehensive Insights: By combining breakout detection, trend analysis, and risk management, it offers a holistic trading tool.
👽 Indicator Settings
Process Noise (Position & Velocity): Adjusts filter responsiveness to price changes.
Measurement Noise: Defines expected price noise for smoother trend detection.
Slope Window: Configures the lookback for slope calculation.
Lookback Period for MAE: Defines the sensitivity of the bands to volatility.
Band Multiplier: Controls the band width.
ATR Multiplier: Adjusts the sensitivity of the trailing stop.
Line Width: Customizes the appearance of the trailing stop line.
Disclaimer: This indicator is designed for educational purposes and does not constitute financial advice. Please consult a qualified financial advisor before making investment decisions.
Kalman Filter Oscillator v4The Kalman Filter Oscillator v4 is an advanced tool designed to help traders and investors identify trends more effectively while reducing the impact of market noise. As the latest iteration in its development, this version integrates improvements that make it more adaptive and precise, catering to the challenges of today’s financial markets.
This indicator operates on the principle of the Kalman filter, a well-regarded mathematical approach used for estimating the state of a dynamic system. By filtering out random fluctuations, it smooths price data to provide clearer insights into underlying trends. Unlike traditional methods such as moving averages, which often lag and can miss rapid shifts, the Kalman Filter Oscillator is reactive in real time, making it particularly suited for dynamic markets.
Version v4 builds on earlier versions by offering a refined combination of short-term and long-term trend analysis. Through adjustable parameters, traders can balance sensitivity to immediate price changes with a broader perspective of the market direction. Additionally, the oscillator incorporates a unique feature that tracks a price’s position relative to its recent highs and lows, which enhances its ability to pinpoint potential turning points or key market conditions.
The indicator’s value lies in its adaptability and practicality. Traders can use it to confirm trends, identify overbought or oversold conditions, or smooth out erratic price movements, reducing the likelihood of false signals. By presenting information in a clear and actionable format, it allows users to make better-informed decisions with greater confidence.
As of late 2024, the Kalman Filter Oscillator v4 represents a sophisticated yet user-friendly advancement in trend analysis. While not a one-size-fits-all solution, it serves as a valuable component in a trader’s toolkit, complementing other strategies and enhancing overall market understanding.

Kalman PredictorThe **Kalman Predictor** indicator is a powerful tool designed for traders looking to enhance their market analysis by smoothing price data and projecting future price movements. This script implements a Kalman filter, a statistical method for noise reduction, to dynamically estimate price trends and velocity. Combined with ATR-based confidence bands, it provides actionable insights into potential price movement, while offering clear trend and momentum visualization.
---
#### **Key Features**:
1. **Kalman Filter Smoothing**:
- Dynamically estimates the current price state and velocity to filter out market noise.
- Projects three future price levels (`Next Bar`, `Next +2`, `Next +3`) based on velocity.
2. **Dynamic Confidence Bands**:
- Confidence bands are calculated using ATR (Average True Range) to reflect market volatility.
- Visualizes potential price deviation from projected levels.
3. **Trend Visualization**:
- Color-coded prediction dots:
- **Green**: Indicates an upward trend (positive velocity).
- **Red**: Indicates a downward trend (negative velocity).
- Dynamically updated label displaying the current trend and velocity value.
4. **User Customization**:
- Inputs to adjust the process and measurement noise for the Kalman filter (`q` and `r`).
- Configurable ATR multiplier for confidence bands.
- Toggleable trend label with adjustable positioning.
---
#### **How It Works**:
1. **Kalman Filter Core**:
- The Kalman filter continuously updates the estimated price state and velocity based on real-time price changes.
- Projections are based on the current price trend (velocity) and extend into the future (Next Bar, +2, +3).
2. **Confidence Bands**:
- Calculated using ATR to provide a dynamic range around the projected future prices.
- Indicates potential volatility and helps traders assess risk-reward scenarios.
3. **Trend Label**:
- Updates dynamically on the last bar to show:
- Current trend direction (Up/Down).
- Velocity value, providing insight into the expected magnitude of the price movement.
---
#### **How to Use**:
- **Trend Analysis**:
- Observe the direction and spacing of the prediction dots relative to current candles.
- Larger spacing indicates a potential strong move, while clustering suggests consolidation.
- **Risk Management**:
- Use the confidence bands to gauge potential price volatility and set stop-loss or take-profit levels accordingly.
- **Pullback Detection**:
- Look for flattening or clustering of dots during trends as a signal of potential pullbacks or reversals.
---
#### **Customizable Inputs**:
- **Kalman Filter Parameters**:
- `lookback`: Adjusts the smoothing window.
- `q`: Process noise (higher values make the filter more reactive to changes).
- `r`: Measurement noise (controls sensitivity to price deviations).
- **Confidence Bands**:
- `band_multiplier`: Multiplies ATR to define the range of confidence bands.
- **Visualization**:
- `show_label`: Option to toggle the trend label.
- `label_offset`: Adjusts the label’s distance from the price for better visibility.
---
#### **Examples of Use**:
- **Scalping**: Use on lower timeframes (e.g., 1-minute, 5-minute) to detect short-term price trends and reversals.
- **Swing Trading**: Identify pullbacks or continuations on higher timeframes (e.g., 4-hour, daily) by observing the prediction dots and confidence bands.
- **Risk Assessment**: Confidence bands help visualize potential price volatility, aiding in the placement of stops and targets.
---
#### **Notes for Traders**:
- The **Kalman Predictor** does not predict the future with certainty but provides a statistically informed estimate of price movement.
- Confidence bands are based on historical volatility and should be used as guidelines, not guarantees.
- Always combine this tool with other analysis techniques for optimal results.
---
This script is open-source, and the Kalman filter logic has been implemented uniquely to integrate noise reduction with dynamic confidence band visualization. If you find this indicator useful, feel free to share your feedback and experiences!
---
#### **Credits**:
This script was developed leveraging the statistical principles of Kalman filtering and is entirely original. It incorporates ATR for dynamic confidence band calculations to enhance trader usability and market adaptability.

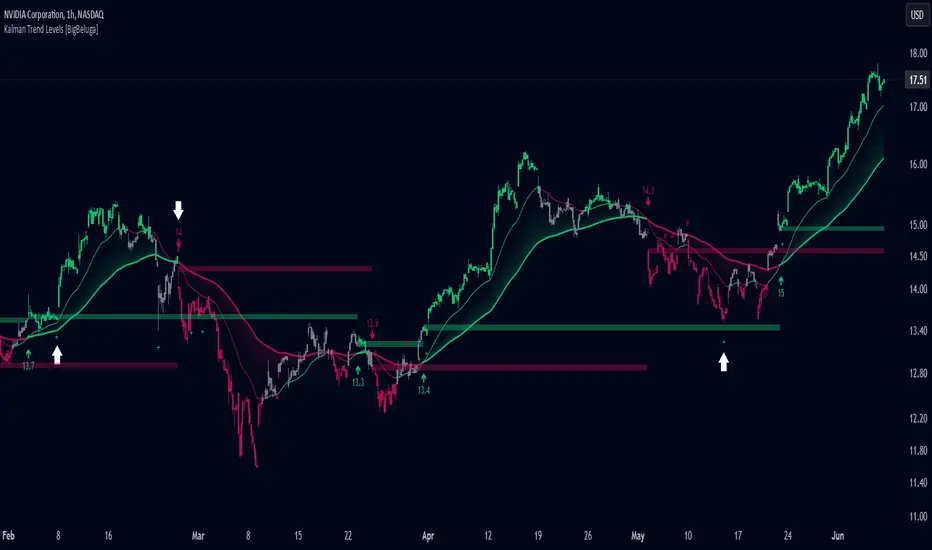
Kalman Trend Levels [BigBeluga]Kalman Trend Levels is an advanced trend-following indicator designed to highlight key support and resistance zones based on Kalman filter crossovers. With dynamic trend analysis and actionable signals, it helps traders interpret market direction and momentum shifts effectively.
🔵 Key Features:
Trend Levels with Crossover Boxes: Identifies trend shifts by tracking crossovers between fast and slow Kalman filters. When the fast line crosses above the slow line, a green box level appears, indicating a potential support zone. When it crosses below, a red box level forms, acting as a resistance zone.
Retest Signals for Support and Resistance Levels: Enable retest signals to capture price rejections at the established levels, providing possible re-entry points where the price confirms a support or resistance area.
Adaptive Candle Coloring by Trend Momentum: Candle colors adjust based on the trend's strength:
> During a downtrend, if the fast Kalman line shows upward movement, indicating reduced bearish momentum, candles turn gray to signal the weakening trend.
> In an uptrend, when the fast Kalman line declines, showing lower bullish momentum, candles become gray, signaling a potential slowdown in upward movement.
Crossover Signals with Price Labels: Displays arrows with price values at crossover points for quick reference, marking where the fast line overtakes or dips below the slow line. These labels provide a precise price snapshot of significant trend changes.
🔵 When to Use:
The Kalman Trend Levels indicator is ideal for traders looking to identify and act upon trend changes and significant price zones. By visualizing key levels and momentum shifts, this tool allows you to:
Define support and resistance zones that align with trend direction.
Identify and react to trend weakening or strengthening via candle color changes.
Use retest signals for potential re-entries at critical levels.
See crossover points and price values to gain a clearer view of trend changes in real time.
With its focus on trend direction, support/resistance, and momentum clarity, Kalman Trend Levels is an essential tool for navigating trending markets, providing actionable insights with every crossover and trend shift.
Adaptive Kalman filter - Trend Strength Oscillator (Zeiierman)█ Overview
The Adaptive Kalman Filter - Trend Strength Oscillator by Zeiierman is a sophisticated trend-following indicator that uses advanced mathematical techniques, including vector and matrix operations, to decompose price movements into trend and oscillatory components. Unlike standard indicators, this model assumes that price is driven by two latent (unobservable) factors: a long-term trend and localized oscillations around that trend. Through a dynamic "predict and update" process, the Kalman Filter leverages vectors to adaptively separate these components, extracting a clearer view of market direction and strength.
█ How It Works
This indicator operates on a trend + local change Kalman Filter model. It assumes that price movements consist of two underlying components: a core trend and an oscillatory term, representing smaller price fluctuations around that trend. The Kalman Filter adaptively separates these components by observing the price series over time and performing real-time updates as new data arrives.
Predict and Update Procedure: The Kalman Filter uses an adaptive predict-update cycle to estimate both components. This cycle allows the filter to adjust dynamically as the market evolves, providing a smooth yet responsive signal. The trend component extracted from this process is plotted directly, giving a clear view of the prevailing direction. The oscillatory component indicates the tendency or strength of the trend, reflected in the green/red coloration of the oscillator line.
Trend Strength Calculation: Trend strength is calculated by comparing the current oscillatory value against a configurable number of past values.
█ Three Kalman filter Models
This indicator offers three distinct Kalman filter models, each designed to handle different market conditions:
Standard Model: This is a conventional Kalman Filter, balancing responsiveness and smoothness. It works well across general market conditions.
Volume-Adjusted Model: In this model, the filter’s measurement noise automatically adjusts based on trading volume. Higher volumes indicate more informative price movements, which the filter treats with higher confidence. Conversely, low-volume movements are treated as less informative, adding robustness during low-activity periods.
Parkinson-Adjusted Model: This model adjusts measurement noise based on price volatility. It uses the price range (high-low) to determine the filter’s sensitivity, making it ideal for handling markets with frequent gaps or spikes. The model responds with higher confidence in low-volatility periods and adapts to high-volatility scenarios by treating them with more caution.
█ How to Use
Trend Detection: The oscillator oscillates around zero, with positive values indicating a bullish trend and negative values indicating a bearish trend. The further the oscillator moves from zero, the stronger the trend. The Kalman filter trend line on the chart can be used in conjunction with the oscillator to determine the market's trend direction.
Trend Reversals: The blue areas in the oscillator suggest potential trend reversals, helping traders identify emerging market shifts. These areas can also indicate a potential pullback within the prevailing trend.
Overbought/Oversold: The thresholds, such as 70 and -70, help identify extreme conditions. When the oscillator reaches these levels, it suggests that the trend may be overextended, possibly signaling an upcoming reversal.
█ Settings
Process Noise 1: Controls the primary level of uncertainty in the Kalman filter model. Higher values make the filter more responsive to recent price changes, but may also increase susceptibility to random noise.
Process Noise 2: This secondary noise setting works with Process Noise 1 to adjust the model's adaptability. Together, these settings manage the uncertainty in the filter's internal model, allowing for finely-tuned adjustments to smoothness versus responsiveness.
Measurement Noise: Sets the uncertainty in the observed price data. Increasing this value makes the filter rely more on historical data, resulting in smoother but less reactive filtering. Lower values make the filter more responsive but potentially more prone to noise.
O sc Smoothness: Controls the level of smoothing applied to the trend strength oscillator. Higher values result in a smoother oscillator, which may cause slight delays in response. Lower values make the oscillator more reactive to trend changes, useful for capturing quick reversals or volatility within the trend.
Kalman Filter Model: Choose between Standard, Volume-Adjusted, and Parkinson-Adjusted models. Each model adapts the Kalman filter for specific conditions, whether balancing general market data, adjusting based on volume, or refining based on volatility.
Trend Lookback: Defines how far back to look when calculating the trend strength, which impacts the indicator's sensitivity to changes in trend strength. Shorter values make the oscillator more reactive to recent trends, while longer values provide a smoother reading.
Strength Smoothness: Adjusts the level of smoothing applied to the trend strength oscillator. Higher values create a more gradual response, while lower values make the oscillator more sensitive to recent changes.
-----------------
Disclaimer
The information contained in my Scripts/Indicators/Ideas/Algos/Systems does not constitute financial advice or a solicitation to buy or sell any securities of any type. I will not accept liability for any loss or damage, including without limitation any loss of profit, which may arise directly or indirectly from the use of or reliance on such information.
All investments involve risk, and the past performance of a security, industry, sector, market, financial product, trading strategy, backtest, or individual's trading does not guarantee future results or returns. Investors are fully responsible for any investment decisions they make. Such decisions should be based solely on an evaluation of their financial circumstances, investment objectives, risk tolerance, and liquidity needs.
My Scripts/Indicators/Ideas/Algos/Systems are only for educational purposes!

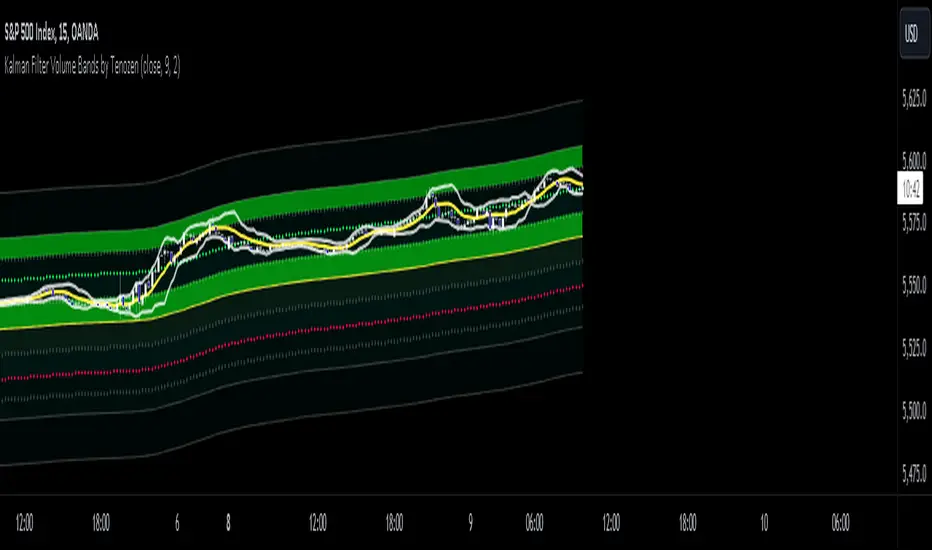
Kalman Based VWAP [EdgeTerminal]Kalman VWAP is a different take on volume-weighted average price (VWAP) indicator where we enhance the results with Kalman filtering and dynamic wave visualization for a more smooth and improved trend identification and volatility analysis.
A little bit about Kalman Filter:
Kalman filtering (also known as linear quadratic estimation) is an algorithm that uses a series of measurements observed over time, including statistical noise and other inaccuracies, to produce estimates of unknown variables that tend to be more accurate than those based on a single measurement, by estimating a joint probability distribution over the variables for each time-step. The filter is constructed as a mean squared error minimiser, but an alternative derivation of the filter is also provided showing how the filter relates to maximum likelihood statistics
This indicator combines:
Volume-Weighted Average Price (VWAP) for institutional price levels
Kalman filtering for noise reduction and trend smoothing
Dynamic wave visualization for volatility zones
This creates a robust indicator that helps traders identify trends, support/resistance zones, and potential reversal points with high precision.
What makes this even more special is the fact that we use open price as a data source instead of usual close price. This allows you to tune the indicator more accurately when back testing it and generally get results that are closer to real time market data.
The math:
In case if you're interested in the math of this indicator, the indicator employs a state-space Kalman filter model:
State Equation: x_t = x_{t-1} + w_t
Measurement Equation: z_t = x_t + v_t
x_t is the filtered VWAP state
w_t is process noise ~ N(0, Q)
v_t is measurement noise ~ N(0, R)
z_t is the traditional VWAP measurement
The Kalman filter recursively updates through:
Prediction: x̂_t|t-1 = x̂_{t-1}
Update: x̂_t = x̂_t|t-1 + K_t(z_t - x̂_t|t-1)
Where K_t is the Kalman gain, optimally balancing between prediction and measurement.
Input Parameters
Measurement Noise: Controls signal smoothing (0.0001 to 1.0)
Process Noise: Adjusts trend responsiveness (0.0001 to 1.0)
Wave Size: Multiplier for volatility bands (0.1 to 5.0)
Trend Lookback: Period for trend determination (1 to 100)
Bull/Bear Colors: Customizable color schemes
Application:
I recommend using this along other indicators. This is best used for assets that don't have a close time, such as BTC but can be used with anything as long as the data is there.
With default settings, this works better for swing trades but you can adjust it for day trading as well, by adjusting the lookback and also process noise.

Kalman Hull RSI [BackQuant]Kalman Hull RSI
At its core, this indicator uses a Kalman filter of price, put inside of a hull moving average function (replacing the weighted moving averages) and then using that as a price source for the the RSI, very similar to the Kalman Hull Supertrend just processing price for a different indicator.
This also allows it to make it more adaptive to price and also sensitive to recent price action. This indicator is also mainly built for trend-following systems
PLEASE Read the following, knowing what an indicator does at its core before adding it into a system is pivotal. The core concepts can allow you to include it in a logical and sound manner.
1. What is a Kalman Filter
The Kalman Filter is an algorithm renowned for its efficiency in estimating the states of a linear dynamic system amidst noisy data. It excels in real-time data processing, making it indispensable in fields requiring precise and adaptive filtering, such as aerospace, robotics, and financial market analysis. By leveraging its predictive capabilities, traders can significantly enhance their market analysis, particularly in estimating price movements more accurately.
If you would like this on its own, with a more in-depth description please see our Kalman Price Filter.
OR our Kalman Hull Supertrend
2. Hull Moving Average (HMA) and Its Core Calculation
The Hull Moving Average (HMA) improves on traditional moving averages by combining the Weighted Moving Average's (WMA) smoothness and reduced lag. Its core calculation involves taking the WMA of the data set and doubling it, then subtracting the WMA of the full period, followed by applying another WMA on the result over the square root of the period's length. This methodology yields a smoother and more responsive moving average, particularly useful for identifying market trends more rapidly.
3. Combining Kalman Filter with HMA
The innovative combination of the Kalman Filter with the Hull Moving Average (KHMA) offers a unique approach to smoothing price data. By applying the Kalman Filter to the price source before its incorporation into the HMA formula, we enhance the adaptiveness and responsiveness of the moving average. This adaptive smoothing method reduces noise more effectively and adjusts more swiftly to price changes, providing traders with clearer signals for market entries or exits.
The calculation is like so:
KHMA(_src, _length) =>
f_kalman(2 * f_kalman(_src, _length / 2) - f_kalman(_src, _length), math.round(math.sqrt(_length)))
Use Case
The Kalman Hull RSI is particularly suited for traders who require a highly adaptive indicator that can respond to rapid market changes without the excessive noise associated with typical RSI calculations. It can be effectively used in markets with high volatility where traditional indicators might lag or produce misleading signals.
Application in a Trading System
The Kalman Hull RSI is versatile in application, suitable for:
Trend Identification: Quickly identify potential reversals or confirmations of existing trends.
Overbought/Oversold Conditions: Utilize the dynamic RSI thresholds to pinpoint potential entry and exit points, adapting to current market conditions.
Risk Management: Enhance trading strategies by integrating a more reliable measure of momentum, which can lead to improved stop-loss placements and exit strategies.
Core Calculations and Benefits
Dynamic State Estimation: By applying the Kalman Filter, the indicator continually adjusts its calculations based on incoming price data, providing a real-time, smoothed response to price movements.
Reduced Lag: The integration with HMA significantly reduces lag, offering quicker responses to price changes than traditional moving averages or RSI alone.
Increased Accuracy: The dual filtering effect minimizes the impact of price spikes and noise, leading to more accurate signaling for trades.
Thus following all of the key points here are some sample backtests on the 1D Chart
Disclaimer: Backtests are based off past results, and are not indicative of the future.
INDEX:BTCUSD
INDEX:ETHUSD
BINANCE:SOLUSD
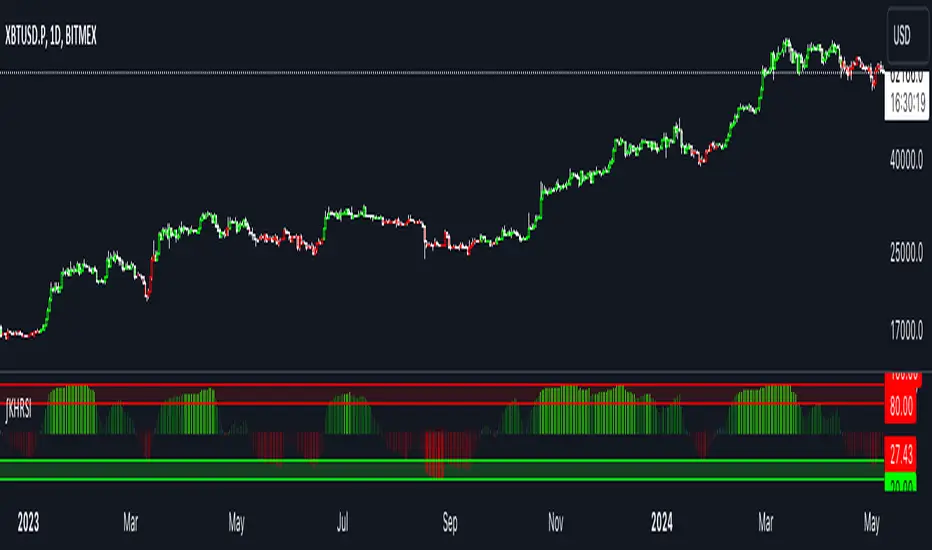
Kalman Filter Volume Bands by TenozenHello there! I am excited to introduce a new original indicator, the Kalman Filter Volume Bands. This indicator is calculated using the Kalman Filter, which is an adaptive-based smoothing quantitative tool. The Kalman Filter Volume Bands have two components that support the calculation, namely VWAP and VaR.
VWAP is used to determine the weight of the Kalman Filter Returns, but it doesn't have a significant impact on the calculation. On the other hand, VaR or Value at risk is calculated using the 99th percentile, which means that there is a 1% chance for the returns to exceed the 99th percentile level. After getting the VaR value, I manually adjust the bands based on the current market I'm trading on. I take the highest point (VaR*2) and the lowest point (-(VaR*2)) from the Kalman Filter, and then divide them into segments manually based on my preference.
This process results in 8 segments, where 2 segments near the Kalman Filter are further divided, making a total of 12 segments. These segments classify the current state of the price based on code-based coloring. The five states are very bullish, bullish, very bearish, bearish, and neutral.
I created this indicator to have an adaptive band that is not biased toward the volatility of the market. Most band-based indicators don't capture reversals that well, but the Kalman Filter Volume Bands can capture both trends and reversals. This makes it suitable for both trend-following and reversal trading approaches.
That's all for the explanation! Ciao!
Additional Reminder:
- Please use hourly timeframes or higher as lower timeframes are too noisy for reliable readings of this indicator.
Kalman Price Filter [BackQuant]Kalman Price Filter
The Kalman Filter, named after Rudolf E. Kálmán, is a algorithm used for estimating the state of a linear dynamic system from a series of noisy measurements. Originally developed for aerospace applications in the early 1960s, such as guiding Apollo spacecraft to the moon, it has since been applied across numerous fields including robotics, economics, and, notably, financial markets. Its ability to efficiently process noisy data in real-time and adapt to new measurements has made it a valuable tool in these areas.
Use Cases in Financial Markets
1. Trend Identification:
The Kalman Filter can smooth out market price data, helping to identify the underlying trend amidst the noise. This is particularly useful in algorithmic trading, where identifying the direction and strength of a trend can inform trade entry and exit decisions.
2. Market Prediction:
While no filter can predict the future with certainty, the Kalman Filter can be used to forecast short-term market movements based on current and historical data. It does this by estimating the current state of the market (e.g., the "true" price) and projecting it forward under certain model assumptions.
3. Risk Management:
The Kalman Filter's ability to estimate the volatility (or noise) of the market can be used for risk management. By dynamically adjusting to changes in market conditions, it can help traders adjust their position sizes and stop-loss orders to better manage risk.
4. Pair Trading and Arbitrage:
In pair trading, where the goal is to capitalize on the price difference between two correlated securities, the Kalman Filter can be used to estimate the spread between the pair and identify when the spread deviates significantly from its historical average, indicating a trading opportunity.
5. Optimal Asset Allocation:
The filter can also be applied in portfolio management to dynamically adjust the weights of different assets in a portfolio based on their estimated risks and returns, optimizing the portfolio's performance over time.
Advantages in Financial Applications
Adaptability: The Kalman Filter continuously updates its estimates with each new data point, making it well-suited to markets that are constantly changing.
Efficiency: It processes data and updates estimates in real-time, which is crucial for high-frequency trading strategies.
Handling Noise: Its ability to distinguish between the signal (e.g., the true price trend) and noise (e.g., random fluctuations) is particularly valuable in financial markets, where price data can be highly volatile.
Challenges and Considerations
Model Assumptions: The effectiveness of the Kalman Filter in financial applications depends on the accuracy of the model used to describe market dynamics. Financial markets are complex and influenced by numerous factors, making model selection critical.
Parameter Sensitivity: The filter's performance can be sensitive to the choice of parameters, such as the process and measurement noise values. These need to be carefully selected and potentially adjusted over time.
Despite these challenges, the Kalman Filter remains a potent tool in the quantitative trader's arsenal, offering a sophisticated method to extract useful information from noisy financial data. Its use in trading strategies should, however, be complemented with sound risk management practices and an awareness of the limitations inherent in any model-based approach to trading.

Kalman Filter by TenozenAnother useful indicator is here! Kalman Filter is a quantitative tool created by Rudolf E. Kalman. In the case of trading, it can help smooth out the price data that traders observe, making it easier to identify underlying trends. The Kalman Filter is particularly useful for handling price data that is noisy and unpredictable. As an adaptive-based algorithm, it can easily adjust to new data, which makes it a handy tool for traders operating in markets that are prone to change quickly.
Many people may assume that the Kalman Filter is the same as a Moving Average, but that is not the case. While both tools aim to smooth data and find trends, they serve different purposes and have their own sets of advantages and disadvantages. The Kalman Filter provides a more dynamic and adaptive approach, making it suitable for real-time analysis and predictive capabilities, but it is also more complex. On the other hand, Moving Averages offer a simpler and more intuitive way to visualize trends, which makes them a popular choice among traders for technical analysis. However, the Moving Average is a lagging indicator and less adaptive to market change, if it's adjusted it may result in overfitting. In this case, the Kalman Filter would be a better choice for smoothing the price up.
I hope you find this indicator useful! It's been an exciting and extensive journey since I began diving into the world of finance and trading. I'll keep you all updated on any new indicators I discover that could benefit the community in the future. Until then, take care, and happy trading! Ciao.
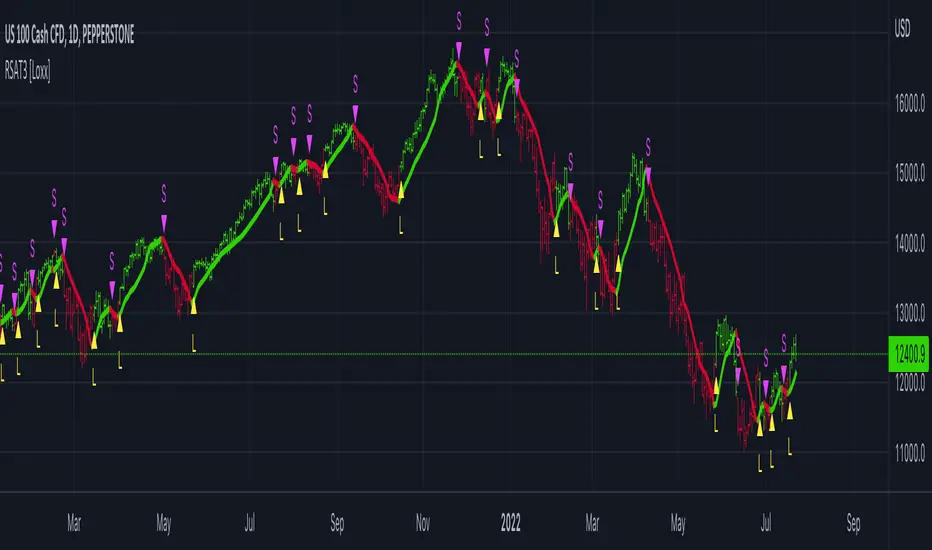
Kalman Filtered ROC & Stochastic with MA SmoothingThe "Smooth ROC & Stochastic with Kalman Filter" indicator is a trend following tool designed to identify trends in the price movement. It combines the Rate of Change (ROC) and Stochastic indicators into a single oscillator, the combination of ROC and Stochastic indicators aims to offer complementary information: ROC measures the speed of price change, while Stochastic identifies overbought and oversold conditions, allowing for a more robust assessment of market trends and potential reversals. The indicator plots green "B" labels to indicate buy signals and blue "S" labels to represent sell signals. Additionally, it displays a white line that reflects the overall trend for buy signals and a blue line for sell signals. The aim of the indicator is to incorporate Kalman and Moving Average (MA) smoothing techniques to reduce noise and enhance the clarity of the signals.
Rationale for using Kalman Filter:
The Kalman Filter is chosen as a smoothing tool in the indicator because it effectively reduces noise and fluctuations. The Kalman Filter is a mathematical algorithm used for estimating and predicting the state of a system based on noisy and incomplete measurements. It combines information from previous states and current measurements to generate an optimal estimate of the true state, while simultaneously minimizing the effects of noise and uncertainty. In the context of the indicator, the Kalman Filter is applied to smooth the input data, which is the source for the Rate of Change (ROC) calculation. By considering the previous smoothed state and the difference between the current measurement and the predicted value, the Kalman Filter dynamically adjusts its estimation to reduce the impact of outliers.
Calculation:
The indicator utilizes a combination of the ROC and the Stochastic indicator. The ROC is smoothed using a Kalman Filter (credit to © Loxx: ), which helps eliminate unwanted fluctuations and improve the signal quality. The Stochastic indicator is calculated with customizable parameters for %K length, %K smoothing, and %D smoothing. The smoothed ROC and Stochastic values are then averaged using the formula ((roc + d) / 2) to create the blended oscillator. MA smoothing is applied to the combined oscillator aiming to further reduce fluctuations and enhance trend visibility. Traders are free to choose their own preferred MA type from 'EMA', 'DEMA', 'TEMA', 'WMA', 'VWMA', 'SMA', 'SMMA', 'HMA', 'LSMA', and 'PEMA' (credit to: © traderharikrishna for this code: ).
Application:
The indicator's buy signals (represented by green "B" labels) indicate potential entry points for buying assets, suggesting a bullish trend. The white line visually represents the trend, helping traders identify and follow the upward momentum. Conversely, the sell signals (blue "S" labels) highlight possible exit points or opportunities for short selling, indicating a bearish trend. The blue line illustrates the bearish movement, aiding in the identification of downward momentum.
The "Smoothed ROC & Stochastic" indicator offers traders a comprehensive view of market trends by combining two powerful oscillators. By incorporating the ROC and Stochastic indicators into a single oscillator, it provides a more holistic perspective on the market's momentum. The use of a Kalman Filter for smoothing helps reduce noise and enhance the accuracy of the signals. Additionally, the indicator allows customization of the smoothing technique through various moving average types. Traders can also utilize the overbought and oversold zones for additional analysis, providing insights into potential market reversals or extreme price conditions. Please note that future performance of any trading strategy is fundamentally unknowable, and past results do not guarantee future performance.

Local Model Kalman Market ModeIntroduction
Heyo guys, I made a new (repainting) indicator called Local Model Kalman Market Mode.
I created it, because I wanted a reliable market mode filter for a potential mean-reversion strategy (e. g. BB Scalping).
On the screenshot you can see an example of how to use it in a BB strategy.
E.g. you would enter long when you have bullish divergence, price is under lower BB, price is under PoC and this indicator here shows range-bound market phase.
You would exit long on cross of the middle band.
Description
The indicator attempts to model the underlying market using different local models (i.e., trending, range-bound, and choppy) and combines them using the T3 Six Pole Kalman Filter to generate an overall estimate of the market.
The Fisher Transform is applied on the price to reach a Gaussian distribution, which increases the accuracy of the indicator itself.
The script first defines state variables for each local model, which include trend direction, trend strength, upper and lower bounds of the range, volatility of the range, level of choppiness, and strength of noise.
Then, likelihood functions are defined for each local model based on the state variables.
Next, the script calculates weights for each local model based on their likelihoods and uses them to calculate state variables for the overall estimate.
Finally, the script combines the state variables using the T3 Six Pole Kalman Filter to generate the overall estimate of the market, which is plotted in blue.
Fundamental Knowledge
To understand the explanation of the indicator and the script, there are a few fundamental concepts that you need to know:
Market: A market is a place where buyers and sellers come together to exchange goods or services.
In the context of trading, the market refers to the exchange where financial instruments such as stocks, currencies, and commodities are bought and sold.
Local models: Local models are statistical models that attempt to capture the characteristics of a particular market regime.
For example, a trending market may have different characteristics than a range-bound market or a choppy market.
The indicator uses different local models to capture the different market regimes.
Trend direction and strength: The trend direction refers to the direction in which the market is moving, either up or down.
The trend strength refers to the magnitude of the trend and how likely it is to continue.
Range-bound market: A range-bound market is a market where prices are trading within a specific range, with a clear upper and lower bound.
Choppiness: Choppiness refers to the degree of irregularity in price movements, often seen in sideways or range-bound markets.
Volatility: Volatility refers to the degree of variation in the price of an asset over time. High volatility implies larger price swings, while low volatility implies smaller price swings.
Kalman filter: A Kalman filter is a mathematical algorithm used to estimate an unknown variable from a series of noisy measurements.
In the context of the indicator, the Kalman filter is used to generate an overall estimate of the market by combining the local models.
T3 Six Pole Kalman Filter: The T3 Six Pole Kalman Filter is a specific type of Kalman filter that is used to smooth and filter time-series data, such as the price data of a financial instrument.
Fisher Transform: The Fisher Transform is a mathematical formula used to transform any probability distribution into a Gaussian normal distribution. It is commonly used in technical analysis to transform non-Gaussian indicators into ones that are more suitable for statistical analysis.
By understanding these fundamental concepts, you should have a basic understanding of how the indicator works and how it generates an overall estimate of the market.
Usage
You can use this indicator on every timeframe.
Users can customize the parameters of the T3 Six Pole Kalman Filter (T3 length, alpha, beta, gamma, and delta) using input functions.
Try out different parameter combinations and use the one you like most.
Thank you for checking this out. Leave me a comment or boost the script, when you wanna support me! 👌
--
Credits to:
▪@HPotter - Fisher Transform
▪@loxx - T3
▪ChatGPT - Helped me to make the research for this indicator and helped to build the core algorithm.

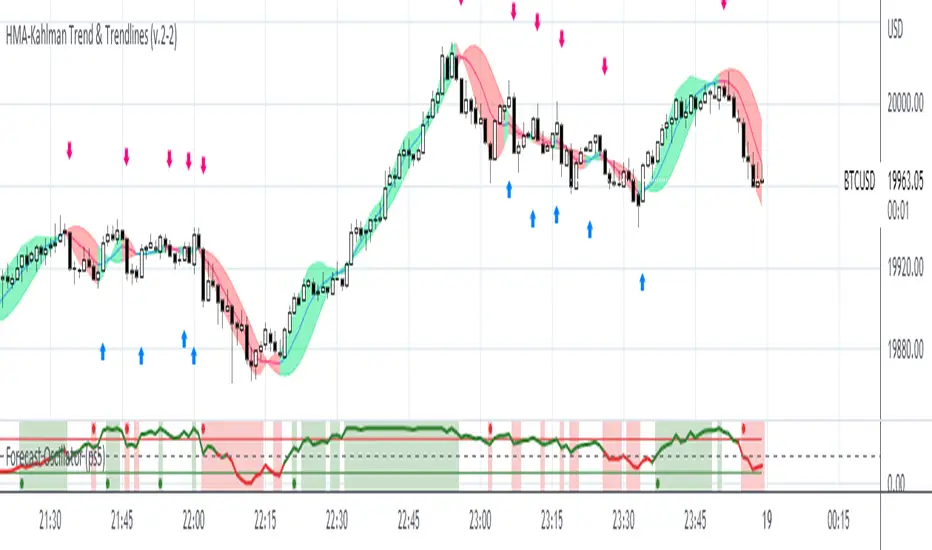
HMA-Kahlman Trend & Trendlines (v.2)This is an upgrade to the HMA-Kahlman Trend & Trendlines script ().
This version gives more flexibility because you can play around with 2 parameters to Kalman function (Sharpness and K (aka. step size)).
R-squared Adaptive T3 [Loxx]R-squared Adaptive T3 is an R-squared adaptive version of Tilson's T3 moving average. This adaptivity was originally proposed by mladen on various forex forums. This is considered experimental but shows how to use r-squared adapting methods to moving averages. In theory, the T3 is a six-pole non-linear Kalman filter.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis. Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD, Momentum, Relative Strength Index) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA (simple moving average) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA(n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA.
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE/2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE/2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE/2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA, popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE/2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA(3) has lag 1, and EMA(11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA(3) through itself 5 times than if I just take EMA(11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA(3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA(7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA(n) = EMA(n) + EMA(time series - EMA(n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA. The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA(n) + EMA(time series - EMA(n))*.7;
This is algebraically the same as:
EMA(n)*1.7-EMA(EMA(n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD(n,v) = EMA(n)*(1+v)-EMA(EMA(n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA, and when v=1, GD is DEMA. In between, GD is a cooler DEMA. By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD(GD(GD(n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA(n)) to correct themselves. In Technical Analysis, these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
Included:
Bar coloring
Signals
Alerts
Loxx's Expanded Source Types