IIR Least-Squares EstimateIntroduction
Another lsma estimate, i don't think you are surprised, the lsma is my favorite low-lag filter and i derived it so many times that our relationship became quite intimate. So i already talked about the classical method, the line-rescaling method and many others, but we did not made to many IIR estimate, the only one was made using a general filter estimator and was pretty inaccurate, this is why i wanted to retry the challenge.
Before talking about the formula lets breakdown again what IIR mean, IIR = infinite impulse response, the impulse response of an IIR filter goes on forever, this is why its infinite, such filters use recursion, this mean they use output's as input's, they are extremely efficient.
The Calculation
The calculation is made with only 1 pole, this mean we only use 1 output value with the same index as input, more poles often means a transition band closer to the cutoff frequency.
Our filter is in the form of :
y = a*x+y - a*ema(y,length/2)
where y = x when t = 1 and y(1) when t > 2 and a = 4/(length+2)
This is also an alternate form of exponential moving average but smoothing the last output terms with another exponential moving average reduce the lag.
Comparison
Lets see the accuracy of our estimate.
Sometimes our estimate follow better the trend, there isn't a clear result about the overshoot/undershoot response, sometimes the estimate have less overshoot/undershoot and sometime its the one with the highest.
The estimate behave nicely with short length periods.
Conclusion
Some surprises, the estimate can at least act as a good low-lag filter, sometimes it also behave better than the lsma by smoothing more. IIR estimate are harder to make but this one look really correct.
If you are looking for something or just want to say thanks try to pm me :)
Thank for reading !
Least Squares Moving Average (LSMA)

Fisher Least Squares Moving AverageIntroduction
I already estimated the least-squares moving average numerous times, one of the most elegant ways was by rescaling a linear function to the price by using the z-score, today i will propose a new smoother (FLSMA) based on the line rescaling approach and the inverse fisher transform of a scaled moving average error with the goal to provide an alternative least-squares smoother, the indicator won't use the correlation coefficient and will try to adresses problems such as overshoots and lag reduction.
Line Rescaling Method
For those who did not see my least squares moving average estimation using the line rescaling method here is a resume, we want to fit a polynomial function of degree 1 to the price by reducing the sum of squares between the price and the filter, squares is a term meaning the squared difference between the price and its estimation. The line rescaling technique work as follow :
1 - get the z-score of a line.
2 - multiply this z-score with the correlation between the price and a line.
3 - multiply the precedent result with the standard deviation of the price, then sum that to a simple moving average.
This process is shorter than the classical least-squares moving average method.
Z-Score Derivation And The Inverse Fisher Transform
The FLSMA will use a similar approach to the line rescaling technique but instead of using the correlation during step 2 we will use an alternative calculated from the error between the estimate and the price.
In order to do so we must use the inverse fisher transform, the inverse fisher transform can take a z-score and scale it in a range of (1,-1), it is possible to estimate the correlation with it. First lets create our modified z-score in the form of : Z = ma((y - Y)/e) where y is the price, Y our output estimate and e the moving average absolute error between the price and Y and lets call it scaled smoothed error , then apply the inverse fisher transform : r = IFT(Z) = tanh(Z) , we then multiply the z-score of the line with it.
Performance
The FLSMA greatly reduce the overshoots, this mean that the maximas of abs(r) are lower than the maxima's of the absolute correlation, such case is not "bad" but we can see that the filter is not closer to the price than the LSMA during trending periods, we can assume the filter don't reduce least-squares as well as the LSMA.
The image above is the running mean of the absolute error of each the FLSMA (in red) and the LSMA (in blue), we could fix this problem by multiplying the smooth scaled error by p where p can be any number, for example :
z = sma(src - nz(b ,src),length)/e * p where p = 2
In red the FLSMA and in blue the FLSMA with p = 2 , the greater p is the less lag the FLSMA will have.
Conclusion
It could be possible to get better results than the LSMA with such design, the presented indicator use its own correlation replacement but it is possible to use anything in a range of (1,-1) to multiply the line z-score. Although the proposed filter only reduce overshoots without keeping the accuracy of the LSMA i believe the code can be useful for others.
Thanks for reading.

Many Moving AveragesThis script allows you to add two moving averages to a chart, where the type of moving average can be chosen from a collection of 15 different moving average algorithms. Each moving average can also have different lengths and crossovers/unders can be displayed and alerted on.
The supported moving average types are:
Simple Moving Average ( SMA )
Exponential Moving Average ( EMA )
Double Exponential Moving Average ( DEMA )
Triple Exponential Moving Average ( TEMA )
Weighted Moving Average ( WMA )
Volume Weighted Moving Average ( VWMA )
Smoothed Moving Average ( SMMA )
Hull Moving Average ( HMA )
Least Square Moving Average/Linear Regression ( LSMA )
Arnaud Legoux Moving Average ( ALMA )
Jurik Moving Average ( JMA )
Volatility Adjusted Moving Average ( VAMA )
Fractal Adaptive Moving Average ( FRAMA )
Zero-Lag Exponential Moving Average ( ZLEMA )
Kauman Adaptive Moving Average ( KAMA )
Many of the moving average algorithms were taken from other peoples' scripts. I'd like to thank the authors for making their code available.
JayRogers
Alex Orekhov (everget)
Alex Orekhov (everget)
Joris Duyck (JD)
nemozny
Shizaru
KobySK
Jurik Research and Consulting for inventing the JMA.

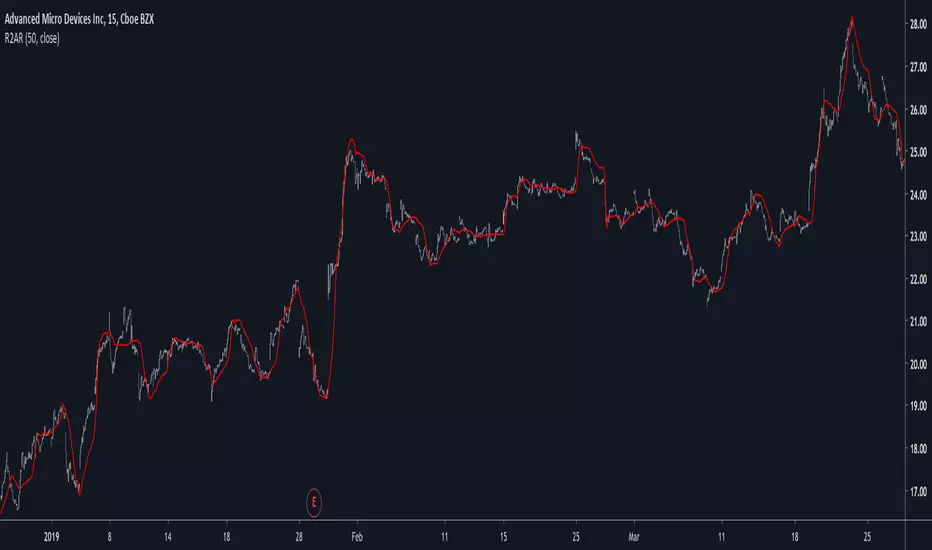
R2-Adaptive RegressionIntroduction
I already mentioned various problems associated with the lsma, one of them being overshoots, so here i propose to use an lsma using a developed and adaptive form of 1st order polynomial to provide several improvements to the lsma. This indicator will adapt to various coefficient of determinations while also using various recursions.
More In Depth
A 1st order polynomial is in the form : y = ax + b , our indicator however will use : y = a*x + a1*x1 + (1 - (a + a1))*y , where a is the coefficient of determination of a simple lsma and a1 the coefficient of determination of an lsma who try to best fit y to the price.
In some cases the coefficient of determination or r-squared is simply the squared correlation between the input and the lsma. The r-squared can tell you if something is trending or not because its the correlation between the rough price containing noise and an estimate of the trend (lsma) . Therefore the filter give more weight to x or x1 based on their respective r-squared, when both r-squared is low the filter give more weight to its precedent output value.
Comparison
lsma and R2 with both length = 100
The result of the R2 is rougher, faster, have less overshoot than the lsma and also adapt to market conditions.
Longer/Shorter terms period can increase the error compared to the lsma because of the R2 trying to adapt to the r-squared. The R2 can also provide good fits when there is an edge, this is due to the part where the lsma fit the filter output to the input (y2)
Conclusion
I presented a new kind of lsma that adapt itself to various coefficient of determination. The indicator can reduce the sum of squares because of its ability to reduce overshoot as well as remaining stationary when price is not trending. It can be interesting to apply exponential averaging with various smoothing constant as long as you use : (1- (alpha+alpha1)) at the end.
Thanks for reading
Inverse Fisher Fast Z-scoreIntroduction
The fast z-score is a modification of the classic z-score that allow for smoother and faster results by using two least squares moving averages, however oscillators of this kind can be hard to read and modifying its shape to allow a better interpretation can be an interesting thing to do.
The Indicator
I already talked about the fisher transform, this statistical transform is originally applied to the correlation coefficient, the normal transform allow to get a result similar to a smooth z-score if applied to the correlation coefficient, the inverse transform allow to take the z-score and rescale it in a range of (1,-1), therefore the inverse fisher transform of the fast z-score can rescale it in a range of (1,-1).
inverse = (exp(k*fz) - 1)/(exp(k*fz) + 1)
Here k will control the squareness of the output, an higher k will return heavy side step shapes while a lower k will preserve the smoothness of the output.
Conclusion
The fisher transform sure is useful to kinda filter visual information, it also allow to draw levels since the rescaling is in a specific range, i encourage you to use it.
Notes
During those almost 2 weeks i was even lazier and sadder than ever before, so i think its no use to leave, i also have papers to publish and i need tv for that.
Thanks for reading !

Trigonometric OscillatorIts a pretty old script and i have absolutely no idea how i did it, the code kinda look like the phase wrapping/unwrapping formula. This indicator is an oscillator, sometimes its reactivity is impressive so i think its a good idea to post it, feel free to experiment with it.

Well Rounded Moving AverageIntroduction
There are tons of filters, way to many, and some of them are redundant in the sense they produce the same results as others. The task to find an optimal filter is still a big challenge among technical analysis and engineering, a good filter is the Kalman filter who is one of the more precise filters out there. The optimal filter theorem state that : The optimal estimator has the form of a linear observer , this in short mean that an optimal filter must use measurements of the inputs and outputs, and this is what does the Kalman filter. I have tried myself to Kalman filters with more or less success as well as understanding optimality by studying Linear–quadratic–Gaussian control, i failed to get a complete understanding of those subjects but today i present a moving average filter (WRMA) constructed with all the knowledge i have in control theory and who aim to provide a very well response to market price, this mean low lag for fast decision timing and low overshoots for better precision.
Construction
An good filter must use information about its output, this is what exponential smoothing is about, simple exponential smoothing (EMA) is close to a simple moving average and can be defined as :
output = output(1) + α(input - output(1))
where α (alpha) is a smoothing constant, typically equal to 2/(Period+1) for the EMA.
This approach can be further developed by introducing more smoothing constants and output control (See double/triple exponential smoothing - alpha-beta filter) .
The moving average i propose will use only one smoothing constant, and is described as follow :
a = nz(a ) + alpha*nz(A )
b = nz(b ) + alpha*nz(B )
y = ema(a + b,p1)
A = src - y
B = src - ema(y,p2)
The filter is divided into two components a and b (more terms can add more control/effects if chosen well) , a adjust itself to the output error and is responsive while b is independent of the output and is mainly smoother, adding those components together create an output y , A is the output error and B is the error of an exponential moving average.
Comparison
There are a lot of low-lag filters out there, but the overshoots they induce in order to reduce lag is not a great effect. The first comparison is with a least square moving average, a moving average who fit a line in a price window of period length .
Lsma in blue and WRMA in red with both length = 100 . The lsma is a bit smoother but induce terrible overshoots
ZLMA in blue and WRMA in red with both length = 100 . The lag difference between each moving average is really low while VWRMA is way more precise.
Hull MA in blue and WRMA in red with both length = 100 . The Hull MA have similar overshoots than the LSMA.
Reduced overshoots moving average (ROMA) in blue and WRMA in red with both length = 100 . ROMA is an indicator i have made to reduce the overshoots of a LSMA, but at the end WRMA still reduce way more the overshoots while being smoother and having similar lag.
I have added a smoother version, just activate the extra smooth option in the indicator settings window. Here the result with length = 200 :
This result is a little bit similar to a 2 order Butterworth filter. Our filter have more overshoots which in this case could be useful to reduce the error with edges since other low pass filters tend to smooth their amplitude thus reducing edge estimation precision.
Conclusions
I have presented a well rounded filter in term of smoothness/stability and reactivity. Try to add more terms to have different results, you could maybe end up with interesting results, if its the case share them with the community :)
As for control theory i have seen neural networks integrated to Kalman flters which leaded to great accuracy, AI is everywhere and promise to be a game a changer in real time data smoothing. So i asked myself if it was possible for a neural networks to develop pinescript indicators, if yes then i could be replaced by AI ? Brrr how frightening.
Thanks for reading :)

Smoothed Delta's Ratio OscillatorIntroduction
Scaled and smoothed oscillators can provide easy to read/use information regarding price, therefore i will introduce a new oscillator who create smooth results and use a fast and practical scaling method. In order to allow for even more smoothness the option to smooth the input with a lsma has been added.
Scaling Using Changes
In this indicator scaling in a range of (1,-1) is achieved through the following calculations :
a = sma(abs(change(src,length)),length)
b = change(sma(src,length),length)
c = b/a
where src is our input. The two elements a and b are quite similar, a smooth the absolute change of the input over length period while b calculate the change of the smoothed input over length period, this make a > b and able us to perform scaling in a range of (1,-1).
The Indicator Parameters
Length control the differencing/smoothing period of the indicator, greater values create smoother and less volatile results, this mean that the oscillator will tend to be equal to 1 or -1 in a longer period of time if length is high. The smooth option allow for even smoother results by enabling the input to be smoothed by a lsma of length period.
Conclusions
I presented a smooth oscillator using a new rescaling technique. Parameters can be separated to provide different results, i believe the code is simple enough for everyone to modify it in order to provide interesting creations.

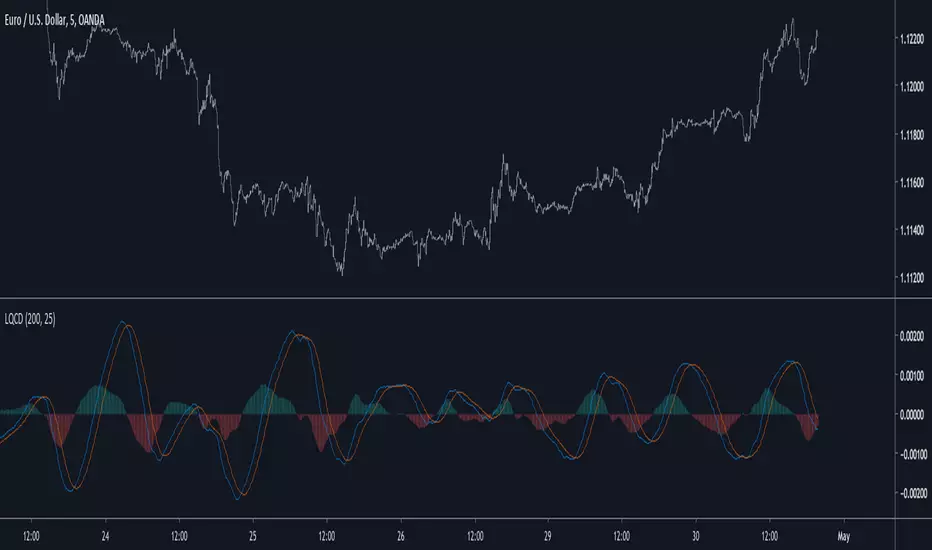
Linear Quadratic Convergence Divergence OscillatorIntroduction
I inspired myself from the MACD to present a different oscillator aiming to show more reactive/predictive information. The MACD originally show the relationship between two moving averages by subtracting one of fast period and another one of slow period. In my indicator i will use a similar concept, i will subtract a quadratic least squares moving average with a linear least squares moving average of same period, since the quadratic least squares moving average is faster than the linear one and both methods have low-lag this will result in a reactive oscillator.
LQCD In Details
A quadratic least squares moving average try to fit a quadratic function (parabola) to the price by using the method of least squares, the linear least squares moving average try to fit a line. Non-linear fit tend to minimize the sum of squares in non-linear data, this is why a quadratic method is more reactive. The difference of both filters give us an oscillator, then we apply a simple moving average to this oscillator to provide the signal line, subtracting the oscillator and its signal line give us the histogram, those two last steps are the same used in the MACD.
Length control the period of the quadratic/linear moving average. While the MACD use a signal line for plotting the histogram i also added the option to plot the momentum of the quadratic moving average instead, the result is smoother and reduce irregularities, in order to do so just check the differential option in the parameter box.
The period of the signal line and the momentum are both controlled by the signal parameter.
A predictive approach can be made by subtracting the histogram with the signal line, this process make the histogram way more predictive, in order to do so just check the predictive histogram option in the parameter box.
Predictive histogram with simple histogram option. The differential mode can also be used with the predictive parameter, this result in a smoother but less reactive prediction.
Information Interpretation
The amount of information the MACD can give us is high. We can use the histogram as signal generator, or the if the oscillator is over/under 0, combine the oscillator/signal line with histogram, combinations can provide various systems. Some traders use the histogram as signal generator and use the cross between the histogram and the signal line as a stop signal, this method can avoid some whipsaw trades. The study of divergences with the price is also another method.
Conclusion
This oscillator aim to show the same amount of information as the MACD with a similar calculation method but using different kind of filters as well as eliminating the need to use two separates periods for the moving averages calculation, its still possible to use different periods for the quadratic/linear moving average but the results can be less accurate. This indicator can be used like the MACD.
Least Squares Moving Average With Overshoot ReductionIntroduction
The ability to reduce lag while keeping a good level of stability has been a major challenge for smoothing filters in technical analysis. Stability involve many parameters, one of them being overshoots. Overshoots are a common effect induced by low-lagging filters, they are defined as the ability of a signal output to exceed a target input. This effect can lead to major drawbacks such as whipsaw and reduction of precision. I propose a modification of the least squares moving average "Reduced Overshoots Moving Average" (ROMA) to reduce overshoots induced by the lsma by using a scaled recursive dispersion coefficient with the purpose of reducing overshoots.
Overshoots - Causes and Effects
Control theory and electronic engineering use step response to measure overshoots, the target signal is defined as an heaviside step function which will be used as input signal for our filter.
In white an input signal, in blue a least squares moving average with the input signal as source, the circle show the overshoot induced by the lsma, the filter exceed drastically the target input. But why low lag filters often induce overshoots ? This is because in order to reduce lag those filter will increase certain frequencies of the input signal, this reduce lag but induce overshoots because the amplitude of those frequencies have been increased, so its normal for the filter to exceed the input target. The increase of frequencies is not a bad process but when those frequencies are already of large amplitudes (high volatility periods) the overshoots can be seen.
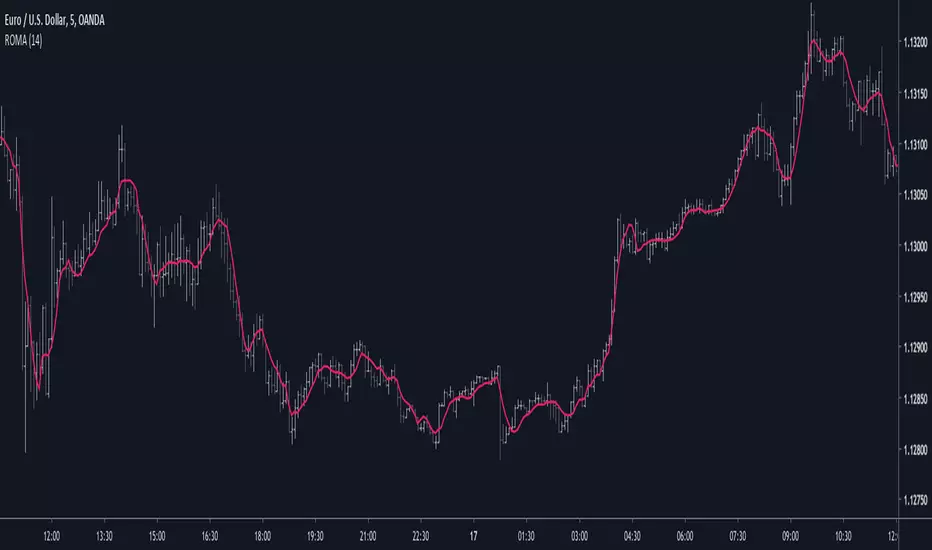
Comparison With ROMA
Our method will use the line rescaling technique to estimate the lsma for efficiency sake. This method involve calculating the z-score of a line and multiplying it by the correlation of the line and the target input (price). Then we rescale this result by adding this z-score multiplied by the dispersion coefficient to a simple moving average. Lets compare the step response of our filer and the lsma.
ROMA (in red) need more data to be computed but reduce the mean absolute error in comparison with the classic lsma, it is seen that instead of following increasing, ROMA decrease thus ending with an undershoot.
ROMA in (red) and an lsma (in blue) with both length = 14, ROMA decrease overshoots with the cost of less smoothing, both filter match when there are no overshoots situations.
Both filters with length = 200, large periods increase the amplitude of overshoots, ROMA stabilize early at the cost of some smoothness.
The running Mean Absolute Error of both filters with length = 100, ROMA (in red) is on average closer to the price than the lsma (in blue)
Conclusion
I presented a modification of the least squares moving average with the goal to provide both stability and rapidity, the statistics show that ROMA do a better job when it comes to reduce the mean absolute error. Alternatives methods can involve decreasing the period it take for the filter to be on a steady state (reducing filter period during high volatility periods) , various filters already exploit this method.
Side Project
I'am not that good when it come to make my post easy to read, this is why i'am currently making an article explaining the basis of digital signal processing. This post will help you to understand signals and things such as lag, frequency transform, cycles, overshoots, ringing, FIR/IIR filters, impulse response, convolution, filter topology and many more. I love to post indicators but also making more educational content as well, so stay tuned :)
Thanks for reading, let me know if you need help with something, i would be happy to assist you.
please be kind to notify me if you find errors about the indicator in order for me to update it as fast as possible.
Fast Z-ScoreIntroduction
The ability of the least squares moving average to provide a great low lag filter is something i always liked, however the least squares moving average can have other uses, one of them is using it with the z-score to provide a fast smoothing oscillator.
The Indicator
The indicator aim to provide fast and smooth results. length control the smoothness.
The calculation is inspired from my sample correlation coefficient estimation described here
Instead of using the difference between a moving average of period length/2 and a moving average of period length , we use the difference between a lsma of period length/2 and a lsma of period length , this difference is then divided by the standard deviation. All those calculations use the price smoothed by a moving average as source.
The yellow version don't divide the difference by a standard deviation, you can that it is less reactive. Both version have length = 200
Conclusion
I presented a smooth and responsive version of a z-score, the result could be used to estimate an even faster lsma by using the line rescaling technique and our indicator as correlation coefficient.
Hope you like it, feel free to modify it and share your results ! :)
Notes
I have been requested a lot of indicators lately, from mt4 translations to more complex time series analysis methods, this accumulation of work made that it is impossible for me to publish those within a short period of time, also some are really complex. I apologize in advance for the inconvenience, i will try to do my best !

Linear Regression Curve - AverageIdea is that the average of price has something to do with sudden changes in trend. Finding trend shifts in mundane.

General Filter Estimator-An Experiment on Estimating EverythingIntroduction
The last indicators i posted where about estimating the least squares moving average, the task of estimating a filter is a funny one because its always a challenge and it require to be really creative. After the last publication of the 1LC-LSMA , who estimate the lsma with 1 line of code and only 3 functions i felt like i could maybe make something more flexible and less complex with the ability to approximate any filter output. Its possible, but the methods to do so are not something that pinescript can do, we have to use another base for our estimation using coefficients, so i inspired myself from the alpha-beta filter and i started writing the code.
Calculation and The Estimation Coefficients
Simplicity is the key word, its also my signature style, if i want something good it should be simple enough, so my code look like that :
p = length/beta
a = close - nz(b ,close)
b = nz(b ,close) + a/p*gamma
3 line, 2 function, its a good start, we could put everything in one line of code but its easier to see it this way. length control the smoothing amount of the filter, for any filter f(Period) Period should be equal to length and f(Period) = p , it would be inconvenient to have to use a different length period than the one used in the filter we want to estimate (imagine our estimation with length = 50 estimating an ema with period = 100) , this is where the first coefficients beta will be useful, it will allow us to leave length as it is. In general beta will be greater than 1, the greater it will be the less lag the filter will have, this coefficient will be useful to estimate low lagging filters, gamma however is the coefficient who will estimate lagging filters, in general it will range around .
We can get loose easily with those coefficients estimation but i will leave a coefficients table in the code for estimating popular filters, and some comparison below.
Estimating a Simple Moving Average
Of course, the boxcar filter, the running mean, the simple moving average, its an easy filter to use and calculate.
For an SMA use the following coefficients :
beta = 2
gamma = 0.5
Our filter is in red and the moving average in white with both length at 50 (This goes for every comparison we will do)
Its a bit imprecise but its a simple moving average, not the most interesting thing to estimate.
Estimating an Exponential Moving Average
The ema is a great filter because its length times more computing efficient than a simple moving average. For the EMA use the following coefficients :
beta = 3
gamma = 0.4
N.B : The EMA is rougher than the SMA, so it filter less, this is why its faster and closer to the price
Estimating The Hull Moving Average
Its a good filter for technical analysis with tons of use, lets try to estimate it ! For the HMA use the following coefficients :
beta = 4
gamma = 0.85
Looks ok, of course if you find better coefficients i will test them and actualize the coefficient table, i will also put a thank message.
Estimating a LSMA
Of course i was gonna estimate it, but this time this estimation does not have anything a lsma have, no moving average, no standard deviation, no correlation coefficient, lets do it.
For the LSMA use the following coefficients :
beta = 3.5
gamma = 0.9
Its far from being the best estimation, but its more efficient than any other i previously made.
Estimating the Quadratic Least Square Moving Average
I doubted about this one but it can be approximated as well. For the QLSMA use the following coefficients :
beta = 5.25
gamma = 1
Another ok estimate, the estimate filter a bit more than needed but its ok.
Jurik Moving Average
Its far from being a filter that i like and its a bit old. For the comparison i will use the JMA provided by @everget described in this article : c.mql5.com
For the JMA use the following coefficients :
for phase = 0
beta = pow*2 (pow is a parameter in the Jma)
gamma = 0.5
Here length = 50, phase = 0, pow = 5 so beta = 10
Looks pretty good considering the fact that the Jma use an adaptive architecture.
Discussion
I let you the task to judge if the estimation is good or not, my motivation was to estimate such filters using the less amount of calculations as possible, in itself i think that the code is quite elegant like all the codes of IIR filters (IIR Filters = Infinite Impulse Response : Filters using recursion) .
It could be possible to have a better estimate of the coefficients using optimization methods like the gradient descent. This is not feasible in pinescript but i could think about it using python or R.
Coefficients should be dependant of length but this would lead to a massive work, the variation of the estimation using fixed coefficients when using different length periods is just ok if we can allow some errors of precision.
I dont think it should be possible to estimate adaptive filter relying a lot on their adaptive parameter/smoothing constant except by making our coefficients adaptive (gamma could be)
So at the end ? What make a filter truly unique ? From my point of sight the architecture of a filter and the problem he is trying to solve is what make him unique rather than its output result. If you become a signal, hide yourself into noise, then look at the filters trying to find you, what a challenging game, this is why we need filters.
Conclusion
I wanted to give a simple filter estimator relying on two coefficients in order to estimate both lagging and low-lagging filters. I will try to give more precise estimate and update the indicator with new coefficients.
Thanks for reading !

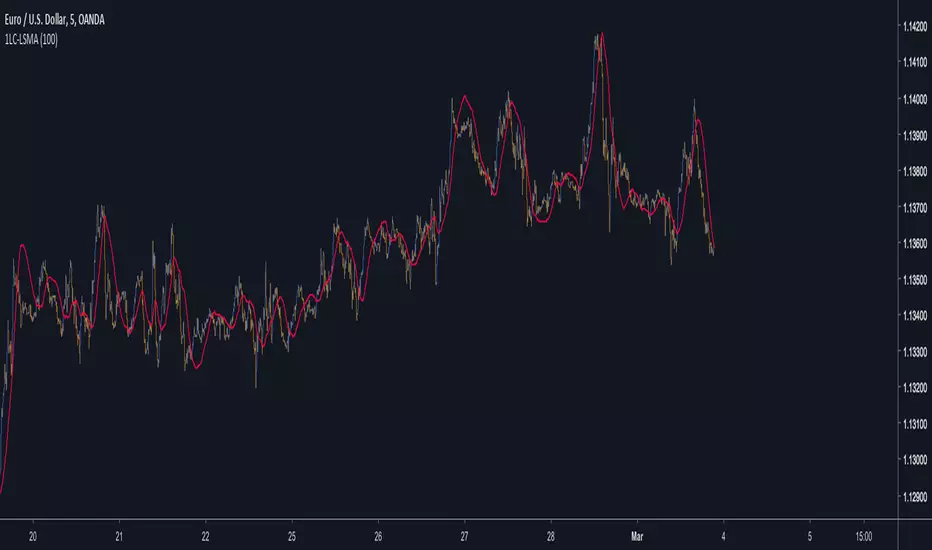
1LC-LSMA (1 line code lsma with 3 functions)Even Shorter Estimation
I know that i'am insistent with the lsma but i really like it and i'm happy to deconstruct it like a mad pinescript user. But if you have an idea about some kind of indicator then dont hesitate to contact me, i would be happy to help you if its feasible.
My motivation for such indicator was to use back the correlation function (that i had putted aside in the ligh-lsma code) and provide a shorter code than the estimation using the line rescaling method (see : Approximating A Least Square Moving Average In Pine) .
The Method
Fairly simple, lets name y our estimation, we calculate it as follow:
y = x̄ + r*o*1.7
where x̄ is the price moving average, r the correlation between the price and a line (or n) and o the standard deviation. If plotted against a classic lsma the difference would be meaningless at first glance so lets plot the absolute value between the difference of the lsma and our estimation of both period 100.
The difference is under 0.0000 on eurusd, its really low.
In general the longer the period of the estimation, the lower the difference between a normal lsma, but when using shorter period they can differ a little bit.
Why 1.7 ?
We need to multiply the standard deviation by a constant in order to match the overshoot and the rise-time of the original lsma. The constant 1.7 is one that work well but actually this constant should be dependant of the length period of the filter to make the estimation more accurate.
More About Step-Response
Most of the time when a filter have less lag, it mean that he induce overshoot in order to decrease the rise-time . Rise-time is the time the output take to match the target input, its related to the lag. Overshoot mean that the output exceed the target input, you can clearly see those concept in the image above.
Conclusion
I've showed that its possible to be even more concise about the code it take to estimate an lsma. I've also briefly explained the concept of rise-time and overshoot, concepts really important to signal processing and particularly in filter design. I'm sure that it can be even more simplified and i have some ideas for such estimate.
Thanks for reading !
Light LSMAEstimating the LSMA Without Classics Parameters
I already mentioned various methods in order to estimate the LSMA in the idea i published. The parameter who still appeared on both the previous estimation and the classic LSMA was the sample correlation coefficient. This indicator will use an estimate of the correlation coefficient using the standard score thus providing a totally different approach in the estimation of the LSMA. My motivation for such indicator was to provide a different way to estimate a LSMA.
Standardization
The standard score is a statistical tool used to measure at how many standard deviations o a data point is bellow or above its mean. It can also be used to rescale variables, this conversion process is called standardizing or normalizing and it will be the basis of our estimation.
Calculation : (x - x̄)/o where x̄ is the moving average of x and o the standard deviation.
Estimating the Correlation Coefficient
We will use standardization to estimate the correlation coefficient r . 1 > r > -1 so in (y - x̄)/o we want to find y such that y is always above or below 1 standard deviation of x̄ , i had for first idea to pass the price through a band-stop filter but i found it was better to just use a moving average of period/2 .
Estimating the LSMA
We finally rescale a line through the price like mentioned in my previous idea, for that we standardize a line and we multiply the result by our correlation estimation, next we multiply the previous calculation by the price standard deviation, then we sum this calculation to the price moving average.
Comparison of our estimate in white with a LSMA in red with both period 50 :
Working With Different Independents Variables
Here the independent variable is a line n (which represent the number of data point and thus create a straight line) but a classic LSMA can work with other independent variables, for exemple if a LSMA use the volume as independent variable we need to change our correlation estimate with (ȳ - x̄)/ô where ȳ is the moving average of period length/2 of y, y is equal to : change(close,length)*change(volume,length) , x̄ is the moving average of y of period length , and ô is the standard deviation of y. This is quite rudimentary and if our goal is to provide a easier way to calculate correlation then the product-moment correlation coefficient would be more adapted (but less reactive than the sample correlation) .
Conclusion
I showed a way to estimate the correlation coefficient, of course some tweaking could provide a better estimate but i find the result still quite close to the LSMA.

Function for Least Squares Moving AverageThank you to alexgrover for putting me wide to this, after putting up with long conversations and stupid questions. Follow him and behold: www.tradingview.com
What is this?
This is simply the function for a Least Squares Moving Average. You can render this on the chart by using the linreg() function in Pine.
Personally I like to use the slope of the LSMA to help determine what direction to take a trade in, but I'm sure there are other, more exotic ways of using it and, if you know how to get your fingers dirty with Pine, you can create more exotic versions of it by modifying the function provided.
Want to learn?
If you'd like the opportunity to learn Pine but you have difficulty finding resources to guide you, take a look at this rudimentary list: docs.google.com
The list will be updated in the future as more people share the resources that have helped, or continue to help, them. Follow me on Twitter to keep up-to-date with the growing list of resources.
Suggestions or Questions?
Don't even kinda hesitate to forward them to me. My (metaphorical) door is always open.
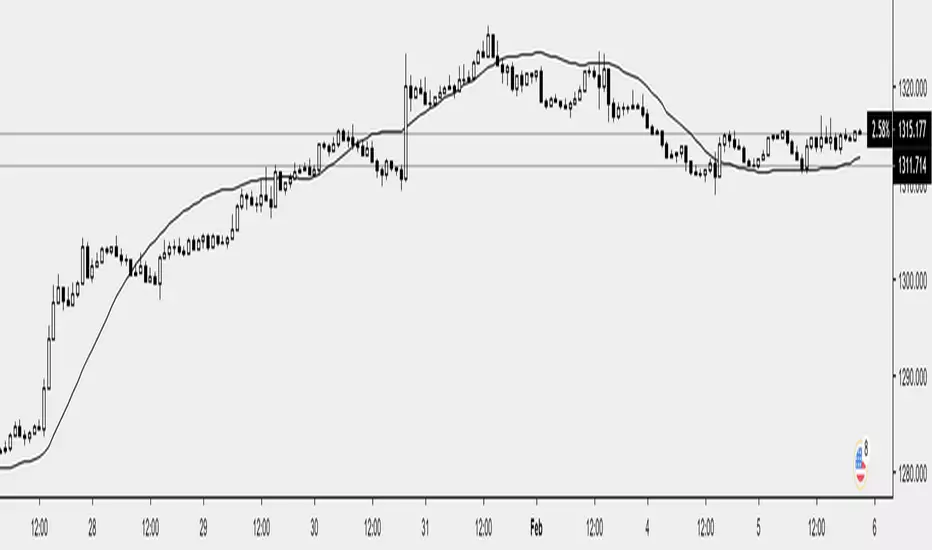
Adaptive Least SquaresAn adaptive filtering technique allowing permanent re-evaluation of the filter parameters according to price volatility. The construction of this filter is based on the formula of moving ordinary least squares or lsma , the period parameter is estimated by dividing the true range with its highest. The filter will react faster during high volatility periods and slower during low volatility ones.
High smooth parameter will create smoother results, values inferior to 3 are recommended.
You can easily replace the parameter estimation method as long as the one used fluctuate in a range of , for example you can use the efficiency ratio
ER = abs(change(close,length))/sum(abs(change(close)),length)
Or the Fractal Dimension Index , in fact any values will work as long as they are rescaled (stoch(value,value,value,length)/100)
For any suggestions/questions feel free to send me a message :)
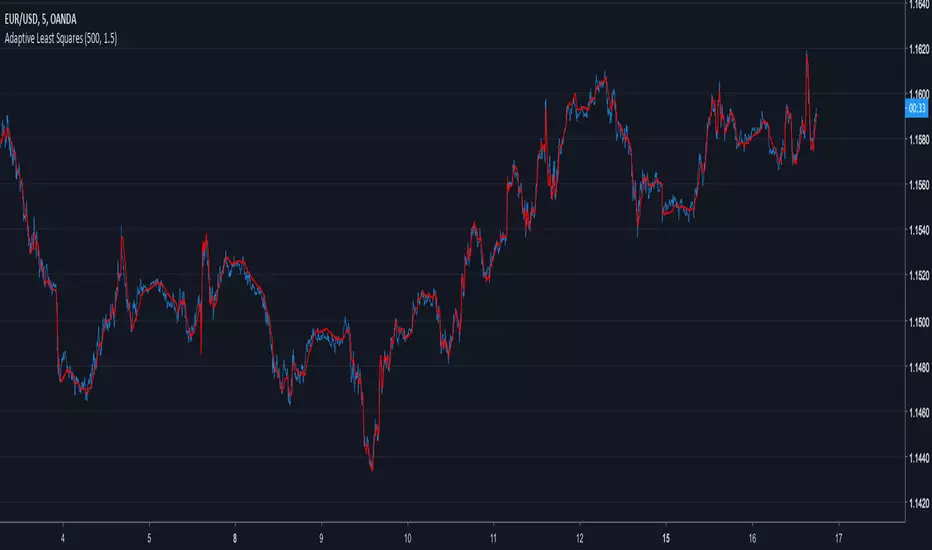
All Moving averagesI have added an option to turn on or off any Moving average by choice and if needed, Heikin-ashi used as source (instead of close)
List of Moving Averages which you can use
T3 - Tillson Moving Average
DEMA - Double Exponential Moving Average
ALMA - Arnaud Legoux moving average
LSMA - Least Squares Moving Average
MA - Simple Moving Average
EMA - Exponential Moving Average
WMA - Weighted Moving Average
SMMA -The Smoothed Moving Average
TEMA - triple exponential moving average
HMA - The Hull Moving Average
AMA - Adaptive Moving Average
FAMA - Fractal Adaptive Moving Average
VIDYA - Variable Index Dynamic Average
TRIMA - Triangular Moving Average
Consider a tip in ETH to
0xac290B4A721f5ef75b0971F1102e01E1942A4578
Thank you and have a nice day
CryptoJoncis

Major Moving AveragesThis script includes the 100 & 200 SMA, EMA, WMA, VWMA, RMA, HMA, LSMA. You can turn off the one's you don't want under Style.
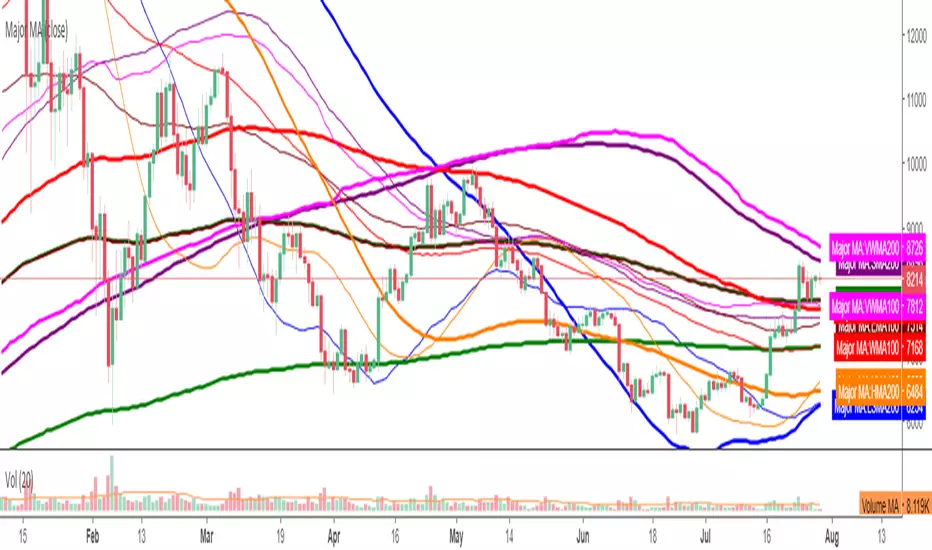
Major LSMAAdds the 25, 50, 100, 150, 200 LSMA in one indicator. Price shows incredible reactions to these on all timeframes.
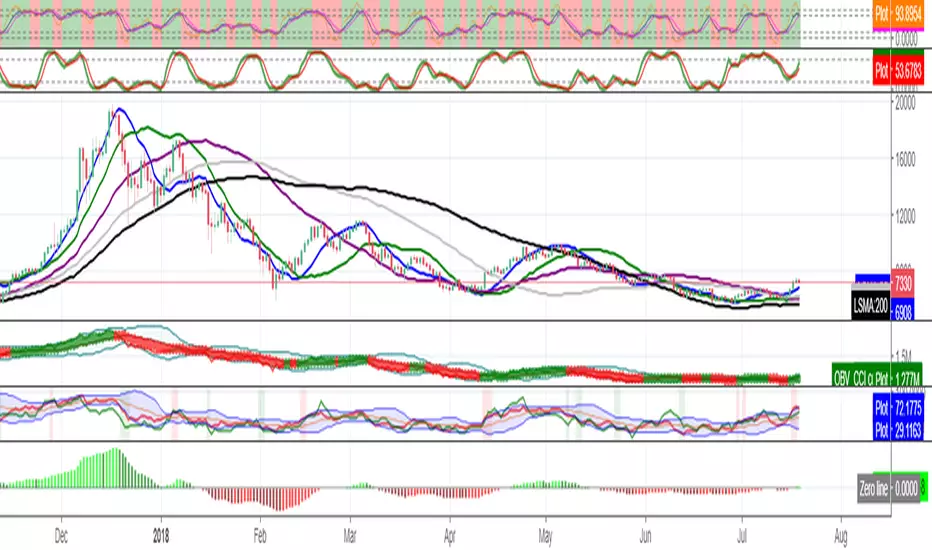

Godmode3.2+LSMAThis script has been based on ProwdClown's instructions of usage.
GM settings 9, 6, 3 should be used, LSMA 25, 0 has been implemented.
Original author for main script: LazyBear, xSilas and Ni6HTH4wK, modified By sco77m4r7in and oh92, later modified By scilentor.
Auto-FilterA least squares filter using the Auto line as source, practical for noise removal without higher phase shift.
Its possible to create another parameter for the auto-line length, just add a parameter Period or whatever you want.
r = round(close/round)*round
dev = stdev(close,Period)
Hope you enjoy :)
