SimilarityMeasuresLibrary "SimilarityMeasures"
Similarity measures are statistical methods used to quantify the distance between different data sets
or strings. There are various types of similarity measures, including those that compare:
- data points (SSD, Euclidean, Manhattan, Minkowski, Chebyshev, Correlation, Cosine, Camberra, MAE, MSE, Lorentzian, Intersection, Penrose Shape, Meehl),
- strings (Edit(Levenshtein), Lee, Hamming, Jaro),
- probability distributions (Mahalanobis, Fidelity, Bhattacharyya, Hellinger),
- sets (Kumar Hassebrook, Jaccard, Sorensen, Chi Square).
---
These measures are used in various fields such as data analysis, machine learning, and pattern recognition. They
help to compare and analyze similarities and differences between different data sets or strings, which
can be useful for making predictions, classifications, and decisions.
---
References:
en.wikipedia.org
cran.r-project.org
numerics.mathdotnet.com
github.com
github.com
github.com
Encyclopedia of Distances, doi.org
ssd(p, q)
Sum of squared difference for N dimensions.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Measure of distance that calculates the squared euclidean distance.
euclidean(p, q)
Euclidean distance for N dimensions.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Measure of distance that calculates the straight-line (or Euclidean).
manhattan(p, q)
Manhattan distance for N dimensions.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Measure of absolute differences between both points.
minkowski(p, q, p_value)
Minkowsky Distance for N dimensions.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
p_value (float) : `float` P value, default=1.0(1: manhatan, 2: euclidean), does not support chebychev.
Returns: Measure of similarity in the normed vector space.
chebyshev(p, q)
Chebyshev distance for N dimensions.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Measure of maximum absolute difference.
correlation(p, q)
Correlation distance for N dimensions.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Measure of maximum absolute difference.
cosine(p, q)
Cosine distance between provided vectors.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
Returns: The Cosine distance between vectors `p` and `q`.
---
angiogenesis.dkfz.de
camberra(p, q)
Camberra distance for N dimensions.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Weighted measure of absolute differences between both points.
mae(p, q)
Mean absolute error is a normalized version of the sum of absolute difference (manhattan).
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Mean absolute error of vectors `p` and `q`.
mse(p, q)
Mean squared error is a normalized version of the sum of squared difference.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Mean squared error of vectors `p` and `q`.
lorentzian(p, q)
Lorentzian distance between provided vectors.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Lorentzian distance of vectors `p` and `q`.
---
angiogenesis.dkfz.de
intersection(p, q)
Intersection distance between provided vectors.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Intersection distance of vectors `p` and `q`.
---
angiogenesis.dkfz.de
penrose(p, q)
Penrose Shape distance between provided vectors.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Penrose shape distance of vectors `p` and `q`.
---
angiogenesis.dkfz.de
meehl(p, q)
Meehl distance between provided vectors.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Meehl distance of vectors `p` and `q`.
---
angiogenesis.dkfz.de
edit(x, y)
Edit (aka Levenshtein) distance for indexed strings.
Parameters:
x (int ) : `array` Indexed array.
y (int ) : `array` Indexed array.
Returns: Number of deletions, insertions, or substitutions required to transform source string into target string.
---
generated description:
The Edit distance is a measure of similarity used to compare two strings. It is defined as the minimum number of
operations (insertions, deletions, or substitutions) required to transform one string into another. The operations
are performed on the characters of the strings, and the cost of each operation depends on the specific algorithm
used.
The Edit distance is widely used in various applications such as spell checking, text similarity, and machine
translation. It can also be used for other purposes like finding the closest match between two strings or
identifying the common prefixes or suffixes between them.
---
github.com
www.red-gate.com
planetcalc.com
lee(x, y, dsize)
Distance between two indexed strings of equal length.
Parameters:
x (int ) : `array` Indexed array.
y (int ) : `array` Indexed array.
dsize (int) : `int` Dictionary size.
Returns: Distance between two strings by accounting for dictionary size.
---
www.johndcook.com
hamming(x, y)
Distance between two indexed strings of equal length.
Parameters:
x (int ) : `array` Indexed array.
y (int ) : `array` Indexed array.
Returns: Length of different components on both sequences.
---
en.wikipedia.org
jaro(x, y)
Distance between two indexed strings.
Parameters:
x (int ) : `array` Indexed array.
y (int ) : `array` Indexed array.
Returns: Measure of two strings' similarity: the higher the value, the more similar the strings are.
The score is normalized such that `0` equates to no similarities and `1` is an exact match.
---
rosettacode.org
mahalanobis(p, q, VI)
Mahalanobis distance between two vectors with population inverse covariance matrix.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
VI (matrix) : `matrix` Inverse of the covariance matrix.
Returns: The mahalanobis distance between vectors `p` and `q`.
---
people.revoledu.com
stat.ethz.ch
docs.scipy.org
fidelity(p, q)
Fidelity distance between provided vectors.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
Returns: The Bhattacharyya Coefficient between vectors `p` and `q`.
---
en.wikipedia.org
bhattacharyya(p, q)
Bhattacharyya distance between provided vectors.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
Returns: The Bhattacharyya distance between vectors `p` and `q`.
---
en.wikipedia.org
hellinger(p, q)
Hellinger distance between provided vectors.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
Returns: The hellinger distance between vectors `p` and `q`.
---
en.wikipedia.org
jamesmccaffrey.wordpress.com
kumar_hassebrook(p, q)
Kumar Hassebrook distance between provided vectors.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
Returns: The Kumar Hassebrook distance between vectors `p` and `q`.
---
github.com
jaccard(p, q)
Jaccard distance between provided vectors.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
Returns: The Jaccard distance between vectors `p` and `q`.
---
github.com
sorensen(p, q)
Sorensen distance between provided vectors.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
Returns: The Sorensen distance between vectors `p` and `q`.
---
people.revoledu.com
chi_square(p, q, eps)
Chi Square distance between provided vectors.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
eps (float)
Returns: The Chi Square distance between vectors `p` and `q`.
---
uw.pressbooks.pub
stats.stackexchange.com
www.itl.nist.gov
kulczynsky(p, q, eps)
Kulczynsky distance between provided vectors.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
eps (float)
Returns: The Kulczynsky distance between vectors `p` and `q`.
---
github.com
Machinelearning

MLExtensionsLibrary "MLExtensions"
normalizeDeriv(src, quadraticMeanLength)
Returns the smoothed hyperbolic tangent of the input series.
Parameters:
src : The input series (i.e., the first-order derivative for price).
quadraticMeanLength : The length of the quadratic mean (RMS).
Returns: nDeriv The normalized derivative of the input series.
normalize(src, min, max)
Rescales a source value with an unbounded range to a target range.
Parameters:
src : The input series
min : The minimum value of the unbounded range
max : The maximum value of the unbounded range
Returns: The normalized series
rescale(src, oldMin, oldMax, newMin, newMax)
Rescales a source value with a bounded range to anther bounded range
Parameters:
src : The input series
oldMin : The minimum value of the range to rescale from
oldMax : The maximum value of the range to rescale from
newMin : The minimum value of the range to rescale to
newMax : The maximum value of the range to rescale to
Returns: The rescaled series
color_green(prediction)
Assigns varying shades of the color green based on the KNN classification
Parameters:
prediction : Value (int|float) of the prediction
Returns: color
color_red(prediction)
Assigns varying shades of the color red based on the KNN classification
Parameters:
prediction : Value of the prediction
Returns: color
tanh(src)
Returns the the hyperbolic tangent of the input series. The sigmoid-like hyperbolic tangent function is used to compress the input to a value between -1 and 1.
Parameters:
src : The input series (i.e., the normalized derivative).
Returns: tanh The hyperbolic tangent of the input series.
dualPoleFilter(src, lookback)
Returns the smoothed hyperbolic tangent of the input series.
Parameters:
src : The input series (i.e., the hyperbolic tangent).
lookback : The lookback window for the smoothing.
Returns: filter The smoothed hyperbolic tangent of the input series.
tanhTransform(src, smoothingFrequency, quadraticMeanLength)
Returns the tanh transform of the input series.
Parameters:
src : The input series (i.e., the result of the tanh calculation).
smoothingFrequency
quadraticMeanLength
Returns: signal The smoothed hyperbolic tangent transform of the input series.
n_rsi(src, n1, n2)
Returns the normalized RSI ideal for use in ML algorithms.
Parameters:
src : The input series (i.e., the result of the RSI calculation).
n1 : The length of the RSI.
n2 : The smoothing length of the RSI.
Returns: signal The normalized RSI.
n_cci(src, n1, n2)
Returns the normalized CCI ideal for use in ML algorithms.
Parameters:
src : The input series (i.e., the result of the CCI calculation).
n1 : The length of the CCI.
n2 : The smoothing length of the CCI.
Returns: signal The normalized CCI.
n_wt(src, n1, n2)
Returns the normalized WaveTrend Classic series ideal for use in ML algorithms.
Parameters:
src : The input series (i.e., the result of the WaveTrend Classic calculation).
n1
n2
Returns: signal The normalized WaveTrend Classic series.
n_adx(highSrc, lowSrc, closeSrc, n1)
Returns the normalized ADX ideal for use in ML algorithms.
Parameters:
highSrc : The input series for the high price.
lowSrc : The input series for the low price.
closeSrc : The input series for the close price.
n1 : The length of the ADX.
regime_filter(src, threshold, useRegimeFilter)
Parameters:
src
threshold
useRegimeFilter
filter_adx(src, length, adxThreshold, useAdxFilter)
filter_adx
Parameters:
src : The source series.
length : The length of the ADX.
adxThreshold : The ADX threshold.
useAdxFilter : Whether to use the ADX filter.
Returns: The ADX.
filter_volatility(minLength, maxLength, useVolatilityFilter)
filter_volatility
Parameters:
minLength : The minimum length of the ATR.
maxLength : The maximum length of the ATR.
useVolatilityFilter : Whether to use the volatility filter.
Returns: Boolean indicating whether or not to let the signal pass through the filter.
backtest(high, low, open, startLongTrade, endLongTrade, startShortTrade, endShortTrade, isStopLossHit, maxBarsBackIndex, thisBarIndex)
Performs a basic backtest using the specified parameters and conditions.
Parameters:
high : The input series for the high price.
low : The input series for the low price.
open : The input series for the open price.
startLongTrade : The series of conditions that indicate the start of a long trade.`
endLongTrade : The series of conditions that indicate the end of a long trade.
startShortTrade : The series of conditions that indicate the start of a short trade.
endShortTrade : The series of conditions that indicate the end of a short trade.
isStopLossHit : The stop loss hit indicator.
maxBarsBackIndex : The maximum number of bars to go back in the backtest.
thisBarIndex : The current bar index.
Returns: A tuple containing backtest values
init_table()
init_table()
Returns: tbl The backtest results.
update_table(tbl, tradeStatsHeader, totalTrades, totalWins, totalLosses, winLossRatio, winrate, stopLosses)
update_table(tbl, tradeStats)
Parameters:
tbl : The backtest results table.
tradeStatsHeader : The trade stats header.
totalTrades : The total number of trades.
totalWins : The total number of wins.
totalLosses : The total number of losses.
winLossRatio : The win loss ratio.
winrate : The winrate.
stopLosses : The total number of stop losses.
Returns: Updated backtest results table.

kNNLibrary "kNN"
Collection of experimental kNN functions. This is a work in progress, an improvement upon my original kNN script:
The script can be recreated with this library. Unlike the original script, that used multiple arrays, this has been reworked with the new Pine Script matrix features.
To make a kNN prediction, the following data should be supplied to the wrapper:
kNN : filter type. Right now either Binary or Percent . Binary works like in the original script: the system stores whether the price has increased (+1) or decreased (-1) since the previous knnStore event (called when either long or short condition is supplied). Percent works the same, but the values stored are the difference of prices in percents. That way larger differences in prices would give higher scores.
k : number k. This is how many nearest neighbors are to be selected (and summed up to get the result).
skew : kNN minimum difference. Normally, the prediction is done with a simple majority of the neighbor votes. If skew is given, then more than a simple majority is needed for a prediction. This also means that there are inputs for which no prediction would be given (if the majority votes are between -skew and +skew). Note that in Percent mode more profitable trades will have higher voting power.
depth : kNN matrix size limit. Originally, the whole available history of trades was used to make a prediction. This not only requires more computational power, but also neglects the fact that the market conditions are changing. This setting restricts the memory matrix to a finite number of past trades.
price : price series
long : long condition. True if the long conditions are met, but filters are not yet applied. For example, in my original script, trades are only made on crossings of fast and slow MAs. So, whenever it is possible to go long, this value is set true. False otherwise.
short : short condition. Same as long , but for short condition.
store : whether the inputs should be stored. Additional filters may be applied to prevent bad trades (for example, trend-based filters), so if you only need to consult kNN without storing the trade, this should be set to false.
feature1 : current value of feature 1. A feature in this case is some kind of data derived from the price. Different features may be used to analyse the price series. For example, oscillator values. Not all of them may be used for kNN prediction. As the current kNN implementation is 2-dimensional, only two features can be used.
feature2 : current value of feature 2.
The wrapper returns a tuple: [ longOK, shortOK ]. This is a pair of filters. When longOK is true, then kNN predicts a long trade may be taken. When shortOK is true, then kNN predicts a short trade may be taken. The kNN filters are returned whenever long or short conditions are met. The trade is supposed to happen when long or short conditions are met and when the kNN filter for the desired direction is true.
Exported functions :
knnStore(knn, p1, p2, src, maxrows)
Store the previous trade; buffer the current one until results are in. Results are binary: up/down
Parameters:
knn : knn matrix
p1 : feature 1 value
p2 : feature 2 value
src : current price
maxrows : limit the matrix size to this number of rows (0 of no limit)
Returns: modified knn matrix
knnStorePercent(knn, p1, p2, src, maxrows)
Store the previous trade; buffer the current one until results are in. Results are in percents
Parameters:
knn : knn matrix
p1 : feature 1 value
p2 : feature 2 value
src : current price
maxrows : limit the matrix size to this number of rows (0 of no limit)
Returns: modified knn matrix
knnGet(distance, result)
Get neighbours by getting k results with the smallest distances
Parameters:
distance : distance array
result : result array
Returns: array slice of k results
knnDistance(knn, p1, p2)
Create a distance array from the two given parameters
Parameters:
knn : knn matrix
p1 : feature 1 value
p2 : feature 2 value
Returns: distance array
knnSum(knn, p1, p2, k)
Make a prediction, finding k nearest neighbours and summing them up
Parameters:
knn : knn matrix
p1 : feature 1 value
p2 : feature 2 value
k : sum k nearest neighbors
Returns: sum of k nearest neighbors
doKNN(kNN, k, skew, depth, price, long, short, store, feature1, feature2)
execute kNN filter
Parameters:
kNN : filter type
k : number k
skew : kNN minimum difference
depth : kNN matrix size limit
price : series
long : long condition
short : short condition
store : store the supplied features (if false, only checks the results without storage)
feature1 : feature 1 value
feature2 : feature 2 value
Returns: filter output

WIPNNetworkLibrary "WIPNNetwork"
this is a work in progress (WIP) and prone to have some errors, so use at your own risk...
let me know if you find any issues..
Method for a generalized Neural Network.
network(x) Generalized Neural Network Method.
Parameters:
x : TODO: add parameter x description here
Returns: TODO: add what function returns

FunctionNNLayerLibrary "FunctionNNLayer"
Generalized Neural Network Layer method.
function(inputs, weights, n_nodes, activation_function, bias, alpha, scale) Generalized Layer.
Parameters:
inputs : float array, input values.
weights : float array, weight values.
n_nodes : int, number of nodes in layer.
activation_function : string, default='sigmoid', name of the activation function used.
bias : float, default=1.0, bias to pass into activation function.
alpha : float, default=na, if required to pass into activation function.
scale : float, default=na, if required to pass into activation function.
Returns: float
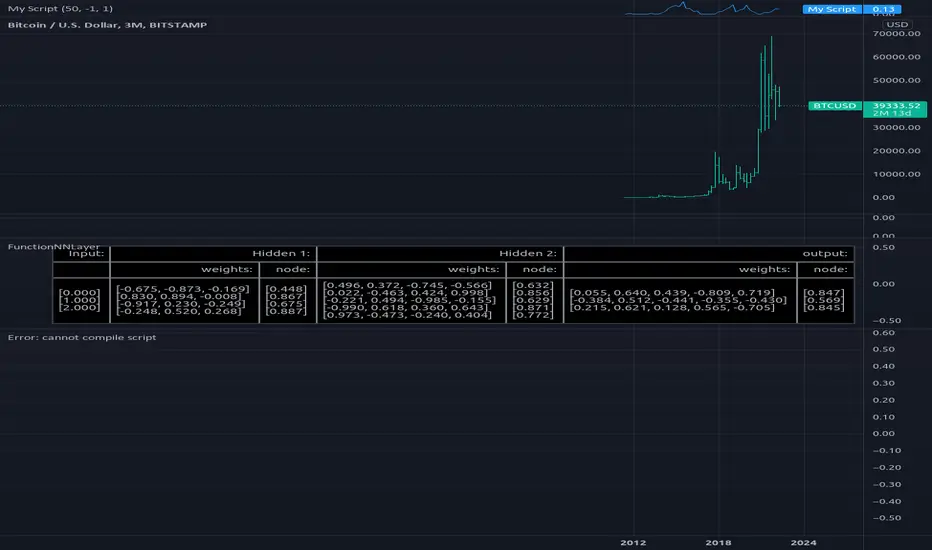
FunctionNNPerceptronLibrary "FunctionNNPerceptron"
Perceptron Function for Neural networks.
function(inputs, weights, bias, activation_function, alpha, scale) generalized perceptron node for Neural Networks.
Parameters:
inputs : float array, the inputs of the perceptron.
weights : float array, the weights for inputs.
bias : float, default=1.0, the default bias of the perceptron.
activation_function : string, default='sigmoid', activation function applied to the output.
alpha : float, default=na, if required for activation.
scale : float, default=na, if required for activation.
@outputs float

MLActivationFunctionsLibrary "MLActivationFunctions"
Activation functions for Neural networks.
binary_step(value) Basic threshold output classifier to activate/deactivate neuron.
Parameters:
value : float, value to process.
Returns: float
linear(value) Input is the same as output.
Parameters:
value : float, value to process.
Returns: float
sigmoid(value) Sigmoid or logistic function.
Parameters:
value : float, value to process.
Returns: float
sigmoid_derivative(value) Derivative of sigmoid function.
Parameters:
value : float, value to process.
Returns: float
tanh(value) Hyperbolic tangent function.
Parameters:
value : float, value to process.
Returns: float
tanh_derivative(value) Hyperbolic tangent function derivative.
Parameters:
value : float, value to process.
Returns: float
relu(value) Rectified linear unit (RELU) function.
Parameters:
value : float, value to process.
Returns: float
relu_derivative(value) RELU function derivative.
Parameters:
value : float, value to process.
Returns: float
leaky_relu(value) Leaky RELU function.
Parameters:
value : float, value to process.
Returns: float
leaky_relu_derivative(value) Leaky RELU function derivative.
Parameters:
value : float, value to process.
Returns: float
relu6(value) RELU-6 function.
Parameters:
value : float, value to process.
Returns: float
softmax(value) Softmax function.
Parameters:
value : float array, values to process.
Returns: float
softplus(value) Softplus function.
Parameters:
value : float, value to process.
Returns: float
softsign(value) Softsign function.
Parameters:
value : float, value to process.
Returns: float
elu(value, alpha) Exponential Linear Unit (ELU) function.
Parameters:
value : float, value to process.
alpha : float, default=1.0, predefined constant, controls the value to which an ELU saturates for negative net inputs. .
Returns: float
selu(value, alpha, scale) Scaled Exponential Linear Unit (SELU) function.
Parameters:
value : float, value to process.
alpha : float, default=1.67326324, predefined constant, controls the value to which an SELU saturates for negative net inputs. .
scale : float, default=1.05070098, predefined constant.
Returns: float
exponential(value) Pointer to math.exp() function.
Parameters:
value : float, value to process.
Returns: float
function(name, value, alpha, scale) Activation function.
Parameters:
name : string, name of activation function.
value : float, value to process.
alpha : float, default=na, if required.
scale : float, default=na, if required.
Returns: float
derivative(name, value, alpha, scale) Derivative Activation function.
Parameters:
name : string, name of activation function.
value : float, value to process.
alpha : float, default=na, if required.
scale : float, default=na, if required.
Returns: float
MLLossFunctionsLibrary "MLLossFunctions"
Methods for Loss functions.
mse(expects, predicts) Mean Squared Error (MSE) " MSE = 1/N * sum ((y - y')^2) ".
Parameters:
expects : float array, expected values.
predicts : float array, prediction values.
Returns: float
binary_cross_entropy(expects, predicts) Binary Cross-Entropy Loss (log).
Parameters:
expects : float array, expected values.
predicts : float array, prediction values.
Returns: float