FunctionNNPerceptronLibrary "FunctionNNPerceptron"
Perceptron Function for Neural networks.
function(inputs, weights, bias, activation_function, alpha, scale) generalized perceptron node for Neural Networks.
Parameters:
inputs : float array, the inputs of the perceptron.
weights : float array, the weights for inputs.
bias : float, default=1.0, the default bias of the perceptron.
activation_function : string, default='sigmoid', activation function applied to the output.
alpha : float, default=na, if required for activation.
scale : float, default=na, if required for activation.
@outputs float
Perceptron

Machine Learning: Perceptron-based strategyPerceptron-based strategy
Description:
The Learning Perceptron is the simplest possible artificial neural network (ANN), consisting of just a single neuron and capable of learning a certain class of binary classification problems. The idea behind ANNs is that by selecting good values for the weight parameters (and the bias), the ANN can model the relationships between the inputs and some target.
Generally, ANN neurons receive a number of inputs, weight each of those inputs, sum the weights, and then transform that sum using a special function called an activation function. The output of that activation function is then either used as the prediction (in a single neuron model) or is combined with the outputs of other neurons for further use in more complex models.
The purpose of the activation function is to take the input signal (that’s the weighted sum of the inputs and the bias) and turn it into an output signal. Think of this activation function as firing (activating) the neuron when it returns 1, and doing nothing when it returns 0. This sort of computation is accomplished with a function called step function: f(z) = {1 if z > 0 else 0}. This function then transforms any weighted sum of the inputs and converts it into a binary output (either 1 or 0). The trick to making this useful is finding (learning) a set of weights that lead to good predictions using this activation function.
Training our perceptron is simply a matter of initializing the weights to zero (or random value) and then implementing the perceptron learning rule, which just updates the weights based on the error of each observation with the current weights. This has the effect of moving the classifier’s decision boundary in the direction that would have helped it classify the last observation correctly. This is achieved via a for loop which iterates over each observation, making a prediction of each observation, calculating the error of that prediction and then updating the weights accordingly. In this way, weights are gradually updated until they converge. Each sweep through the training data is called an epoch.
In this script the perceptron is retrained on each new bar trying to classify this bar by drawing the moving average curve above or below the bar.
This script was tested with BTCUSD, USDJPY, and EURUSD.
Note: TradingViews's playback feature helps to see this strategy in action.
Warning: Signals ARE repainting.
Style tags: Trend Following, Trend Analysis
Asset class: Equities, Futures, ETFs, Currencies and Commodities
Dataset: FX Minutes/Hours+/Days
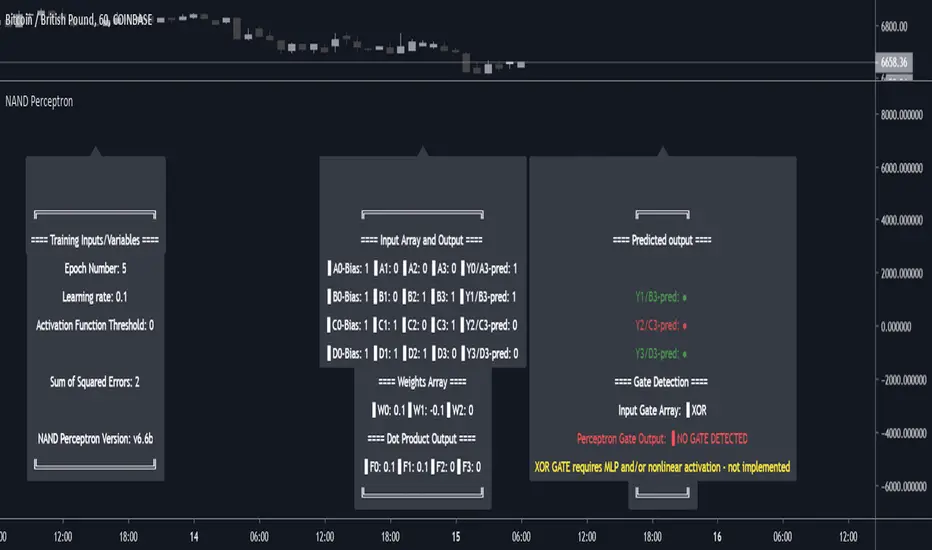
NAND PerceptronExperimental NAND Perceptron based upon Python template that aims to predict NAND Gate Outputs. A Perceptron is one of the foundational building blocks of nearly all advanced Neural Network layers and models for Algo trading and Machine Learning.
The goal behind this script was threefold:
To prove and demonstrate that an ACTUAL working neural net can be implemented in Pine, even if incomplete.
To pave the way for other traders and coders to iterate on this script and push the boundaries of Tradingview strategies and indicators.
To see if a self-contained neural network component for parameter optimization within Pinescript was hypothetically possible.
NOTE: This is a highly experimental proof of concept - this is NOT a ready-made template to include or integrate into existing strategies and indicators, yet (emphasis YET - neural networks have a lot of potential utility and potential when utilized and implemented properly).
Hardcoded NAND Gate outputs with Bias column (X0):
// NAND Gate + X0 Bias and Y-true
// X0 // X1 // X2 // Y
// 1 // 0 // 0 // 1
// 1 // 0 // 1 // 1
// 1 // 1 // 0 // 1
// 1 // 1 // 1 // 0
Column X0 is bias feature/input
Column X1 and X2 are the NAND Gate
Column Y is the y-true values for the NAND gate
yhat is the prediction at that timestep
F0,F1,F2,F3 are the Dot products of the Weights (W0,W1,W2) and the input features (X0,X1,X2)
Learning rate and activation function threshold are enabled by default as input parameters
Uncomment sections for more training iterations/epochs:
Loop optimizations would be amazing to have for a selectable length for training iterations/epochs but I'm not sure if it's possible in Pine with how this script is structured.
Error metrics and loss have not been implemented due to difficulty with script length and iterations vs epochs - I haven't been able to configure the input parameters to successfully predict the right values for all four y-true values for the NAND gate (only been able to get 3/4; If you're able to get all four predictions to be correct, let me know, please).
// //---- REFERENCE for final output
// A3 := 1, y0 true
// B3 := 1, y1 true
// C3 := 1, y2 true
// D3 := 0, y3 true
PLEASE READ: Source article/template and main code reference:
towardsdatascience.com
towardsdatascience.com
towardsdatascience.com