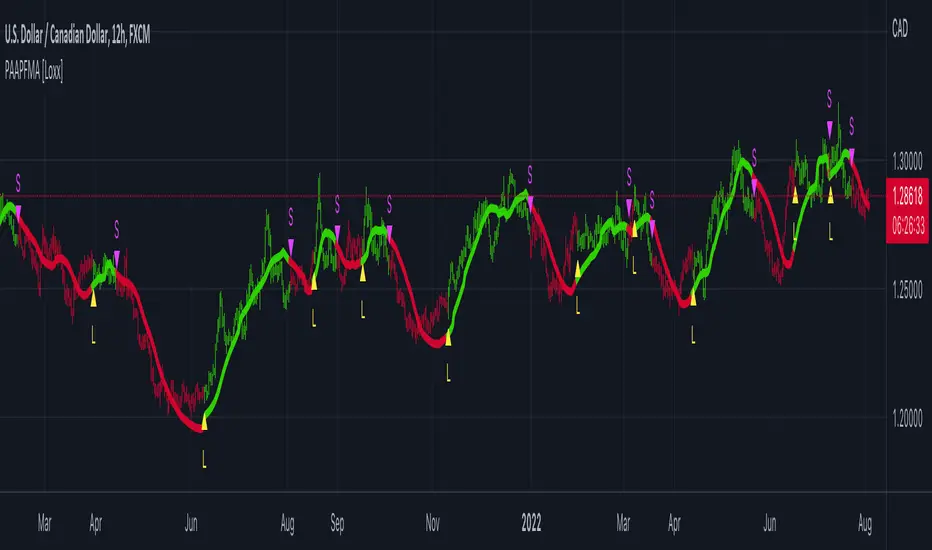
[Excalibur] Advanced Polynomial Regression Trend ChannelIt's been a long time coming... Regression channel enthusiasts, it's 'ultimately' here! Welcome to my Apophis page. But first, let me explain the origins of its attributed name blending both descriptive & engaging content with concise & technical topics...
EGYPTIAN ROOTED TALES:
Apophis (Greek) or Apep (Egyptian) was known by many cultures to be a mighty Egyptian archetype of chaos, darkness, and destruction. In ancient Egyptian mythology, Apophis was often depicted in the form of a fearsome menacing serpent, in those days, with an insatiable appetite for relentless malevolence. This dreaded entity was considered a formidable enemy and was also believed to appear as a giant serpent arising from the underworld.
Forever engaging in eternal battle, according to lore, Apophis' adversarial attributes represented the forces of disorder and anarchy clashing with the forces of order and harmony. This serpent's wickedly described figure was significantly symbolic of the disruptive, treacherous powers that Apophis embodied, those which threatened to plunge the perceivable archaic world into darkness. To the ancients, the legendary cyclical struggles against Apophis served as allegory reflecting on the macrocosm of the larger conflict between good and evil disparities that shaped early ancient civilization, much like the tree serpent.
One of Apophis’ mythological roots was immortally depicted on tomb stone. On one particular hieroglyphic wall tableau, in the second chamber of Inherkau’s tomb at Deir el-Medina, within the Theban Necropolis, portrays a mural of a serpent (Apep) under an edible fruit tree being slain in defeat. The species of snake depicted on various locations of tomb walls appears to me to bear a striking resemblance to the big eyed Echis pyramidum (Egyptian saw-scaled viper) native to regions of North Africa and the Middle East. It's a species of viper notoriously contributing to the most snake bite fatalities in the world still to this day; talk about a true harbinger of chaos incarnate. You do NOT want to cross paths with this asp in the dark of night, ever! Nor the other species of Echis found around Echid trees in the garden.
As we all know, fabled archaic storytelling can be misconstruing. Yet, these archaic serpent narratives still have echoes of significant notions and wisdom to learn from, especially in a modern technological society still rife with miscalculating deep snakes slithering about with intent to specifically plot disorder on national scales, and then profitably capitalize on it. Many deep black snakes are hiding in plain sight and under rocks. They do indeed speak and spell with forked tongues and malfeasance to the masses. I have great news. Tools now exist in the realms of AI combined with fractal programming circles to uncover these venomous viper mesh networks and investigatively monitor their subversive activities, so their days are surely numbered for... GAME OVER. Prepare to meet the doom you vain vipers have sought!
The arrival of the great and powerful international storm of the century has come, clothed in vindication. It's the only just way for the globe to clean house and move forward economically into the evolving herafter unobstructed by rampant evils and corruption. The foundations of future architectures are being established, and these nefarious obstacles MUST NOT hinder that path ahead.
With my former days of serpent wrangling being behind me, I now explore avenues of history, philosophy, programming, and mathematics, weaving them all into my daily routine. Now is the time to make some mathematical history unfold and get to the good and spicy stuff that you as the reader seek...
CALCULATING ON CHAOS:
Perhaps frightful characteristics of serpents (their maneuverability to adapt to any swervy situation) could be harnessed and channeled into a powerful tool for navigating the treacherous waters of data chaos. What if taming a monstrous beast of mayhem was not only possible, but fully achievable? Well, I think I have improved upon an approach to better tackle fractal chaos handling and observation within a modest PSv6 float environment without doubles. Finally, I've successfully turned my pet anaconda, Apophis, into a docile form of mathematical charting resilience beyond anything I have ever visually witnessed before. This novel work clearly deprecates ALL of my prior regression works by performing everything those delivered AND more, but it doesn't necessarily eliminate them into extinction.
INTRODUCTION:
Allow me to introduce Apophis! What you see showcased above is also referred to as 'Advanced Polynomial Regression Trend Channel' (APRTC) for technical minds. I would describe it as an avant-garde trend channel obtaining accurate polynomial approximations on market data with Pine v6.0. APRTC is a fractal following demystifier that I can only describe as being a signal trajectory tracking stalker manifesting as a data devouring demon. My full-fledged 'Excalibur' version of poly-regression swiftly captures undulating patterns present in market data with ease and at warp speed faster than you can blink. Now unchained, this is my rendering of polynomial wrath employing the "Immense Power of Pine".
By pushing techniques of regression to extremes, I am able to trace the serpentine trajectory of chaos up to a 50th order with 100s or 1000s of samples via "advanced polynomial regression" (APR), aka Apophis. This uniquely reactive trend channel method is designed to enhance the way we engage with the complex challenge of observably interpreting chaotic price behavior. While this is the end of the road for my revolutionary trend channel technology, that doesn't imply that future polynomial regression upgrades won't/might occur... There are a number of other supplementary concepts I have in my mind that could potentially prove useful eventually, who knows. However, for the moment, I feel it's wisest to monitor how accommodating APRTC is towards servers for the present time.
HISTORICAL ENDEAVORS:
Having wrangled countless wild serpents in my youth by the handfuls, tackling this was one multi-headed regression challenge temptation I couldn't resist. Besides, serpents in reality are more than often scared of us in the wild, so I assumed this shouldn't be too terribly hard. Wrong! It's been a complex struggle indeed. APRTC gave me many stinging bites for a LONG time. I had unknowingly opened Pandora's box of polynomials unprepared for what was to follow.
Long have I wrestled with Apophis throughout many nights for years with adversity, at last having arrived at a current grand solution and ultimately emerging victorious. Now, does the significance of the entitled name Apophis become more apparent at this point of reading? What you can now witness above is a very powerful blend of precision combined with maneuverability, concluding my dreamy expectations of a maximal experience with polynomial regression in TV charts. With all of my wizardry components finally assembled, Apophis genuinely is the most phenomenal indicator I ever devised in my life... as of yet.
How was this accomplished? By unlocking a deep understanding of the mathematical principles that govern regression, combined with an arsenal of mathemagical trickeries through sheer determination. I also spent an incredible amount of time flexing the unbendable 64bit float numerics to obtain a feasible order/degree of up to 50 polynomials or up to 4000 bars of regression (never simultaneously) on a labyrinth of samples. Lastly, what was needed was a pinch of mathematical pixie dust with a pleasant dose of Pine upgrades (lots of line re-drawings) that millions of other members can also utilize. Thank you so much, Pine developers, for once again turning meager proposed visions into materialized reality by leveraging the "Power of Pine" for the many!
DESCRIBING POLYNOMIAL REGRESSION:
APRTC is a visual guide for navigating noisy markets, providing both trajectory and structure through the power of mathematical modeling. Polynomial regression, especially at higher orders, exhibits obvious sidewinder/serpentine like characteristics. Even the channel extremities, on swift one second charts, resemble scales in motion with a pair of dashed exterior lines. This poly version presently yields the best quality of fit, providing an extreme "visual analysis" of your price action in high noise environments. The greater the order of the polynomial, the more pronounced the meandering regression characteristics become, as the algorithm strives to visually capture the fundamental fractal patterns most effectively.
Polynomial Regression in Action:
The medial line displays the core polynomial regression approximation in similarity to spinal backbones of serpents when following the movements of market data. Encasing the central structure, the channel's skin consists of enveloping lines having upper and lower extremes. To further enhance visualization, background fill colors distinguish the breadth between positive and negative territories of potential movement.
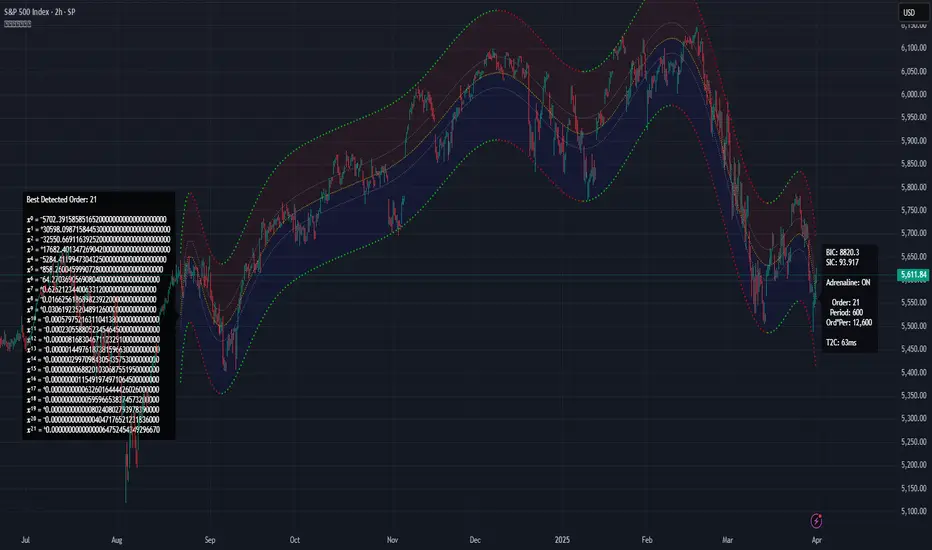
Additional internal dotted variability lines are available with multiple customizable settings to adjust dynamic dispersion, color, etc. One other exciting feature I added is the the ability to see the polynomial values with up to 50 (adjustable) decimal places if available. Witnessing Xⁿ values tapering near to 0.0 may indicate overfitting. Linear regression is available at order=1 and quadratic regression is invoked using order=2.
Information Criterion:
A toggleable label provides a multitude of information such as Bayesian Information Criterion (BIC), order, period, etc. BIC serves as an polynomial regression fit metric, with lesser values indicating a better balance between polynomial order adjustments, reflecting a more accurate fit in relation to the channel's girth. One downside of BIC values is their often large numerical values, making visual comparisons challenging, and then also their rare occurrence as negative values.
Furthermore, I formulated my own "EXPERIMENTAL" Simpler Information Criterion (SIC) fit metric, which seems to offer better visual interpretability when adjusting order settings on a selected regression period, especially on minuscule price numerics. Positive valued SIC numerics with lesser digits also reflect a preferred better fit during order adjustment, same as applying BIC principles of the minimum having a superior calulation tendency. I'll let members be the judge of deciding whether my SIC is actually a superior information criterion compared to BIC.
TECHNICAL INTERPRETATION and APPLICATION:
The Apophis indicator utilizes high-order polynomial regression, up to a maximum 50th order ability to deliver a nuanced, visual representation of complex market dynamics. I would caution against using upwards toward a 50th order, because opting for a 50th order polynomial is categorically speaking "wildly unsane" in real-world practice. As the polynomial degree increases from lesser orders, the regression line exhibits more pronounced curvature and undulations.
Visually analyzing the regression curve can provide insights into prevailing trends, as well as volatility regimes. For example, a gently sloping line may signal a steady directional trend, while a tightly curled oscillating curve may indicate heightened volatility and range-bound trading. Settings are rather straight forward, and comparable to my former "Quadratic Regression Trend Channel" efforts, although one torturous feature from QRTC is omitted due too computational complexity concerns.
Notice: Trial invite only access will not be granted for this indicator. Those who are familiar with recognizing what APRTC is, you will either want it or not, to add to your arsenal of trading approaches.
When available time provides itself, I will consider your inquiries, thoughts, and concepts presented below in the comments section, should you have any questions or comments regarding this indicator. When my indicators achieve more prevalent use by TV members , I may implement more ideas when they present themselves as worthy additions. Have a profitable future everyone!
RISK DISCLAIMER:
My scripts and indicators are specifically intended for informational and educational use only. This script uses historical data points to perform calculations to derive real-time calculations. They do not infer, indicate, or guarantee future results or performance.
By utilizing this script/indicator or any portion of it, you agree to accept 100% responsibly and liability for your investment or financial decisions, and I will not be held liable for your subjective analytic interpretations incurring sustained monetary losses. The opinions and information visual or otherwise provided by this script/indicator is not investment advice, nor does it constitute recommendation.
Polynomialregression
regressionsLibrary "regressions"
This library computes least square regression models for polynomials of any form for a given data set of x and y values.
fit(X, y, reg_type, degrees)
Takes a list of X and y values and the degrees of the polynomial and returns a least square regression for the given polynomial on the dataset.
Parameters:
X (array) : (float ) X inputs for regression fit.
y (array) : (float ) y outputs for regression fit.
reg_type (string) : (string) The type of regression. If passing value for degrees use reg.type_custom
degrees (array) : (int ) The degrees of the polynomial which will be fit to the data. ex: passing array.from(0, 3) would be a polynomial of form c1x^0 + c2x^3 where c2 and c1 will be coefficients of the best fitting polynomial.
Returns: (regression) returns a regression with the best fitting coefficients for the selecected polynomial
regress(reg, x)
Regress one x input.
Parameters:
reg (regression) : (regression) The fitted regression which the y_pred will be calulated with.
x (float) : (float) The input value cooresponding to the y_pred.
Returns: (float) The best fit y value for the given x input and regression.
predict(reg, X)
Predict a new set of X values with a fitted regression. -1 is one bar ahead of the realtime
Parameters:
reg (regression) : (regression) The fitted regression which the y_pred will be calulated with.
X (array)
Returns: (float ) The best fit y values for the given x input and regression.
generate_points(reg, x, y, left_index, right_index)
Takes a regression object and creates chart points which can be used for plotting visuals like lines and labels.
Parameters:
reg (regression) : (regression) Regression which has been fitted to a data set.
x (array) : (float ) x values which coorispond to passed y values
y (array) : (float ) y values which coorispond to passed x values
left_index (int) : (int) The offset of the bar farthest to the realtime bar should be larger than left_index value.
right_index (int) : (int) The offset of the bar closest to the realtime bar should be less than right_index value.
Returns: (chart.point ) Returns an array of chart points
plot_reg(reg, x, y, left_index, right_index, curved, close, line_color, line_width)
Simple plotting function for regression for more custom plotting use generate_points() to create points then create your own plotting function.
Parameters:
reg (regression) : (regression) Regression which has been fitted to a data set.
x (array)
y (array)
left_index (int) : (int) The offset of the bar farthest to the realtime bar should be larger than left_index value.
right_index (int) : (int) The offset of the bar closest to the realtime bar should be less than right_index value.
curved (bool) : (bool) If the polyline is curved or not.
close (bool) : (bool) If true the polyline will be closed.
line_color (color) : (color) The color of the line.
line_width (int) : (int) The width of the line.
Returns: (polyline) The polyline for the regression.
series_to_list(src, left_index, right_index)
Convert a series to a list. Creates a list of all the cooresponding source values
from left_index to right_index. This should be called at the highest scope for consistency.
Parameters:
src (float) : (float ) The source the list will be comprised of.
left_index (int) : (float ) The left most bar (farthest back historical bar) which the cooresponding source value will be taken for.
right_index (int) : (float ) The right most bar closest to the realtime bar which the cooresponding source value will be taken for.
Returns: (float ) An array of size left_index-right_index
range_list(start, stop, step)
Creates an from the start value to the stop value.
Parameters:
start (int) : (float ) The true y values.
stop (int) : (float ) The predicted y values.
step (int) : (int) Positive integer. The spacing between the values. ex: start=1, stop=6, step=2:
Returns: (float ) An array of size stop-start
regression
Fields:
coeffs (array__float)
degrees (array__float)
type_linear (series__string)
type_quadratic (series__string)
type_cubic (series__string)
type_custom (series__string)
_squared_error (series__float)
X (array__float)
GKD-C Polynomial-Regression-Fitted Filter [Loxx]Giga Kaleidoscope GKD-C Polynomial-Regression-Fitted Filter is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ GKD-C Polynomial-Regression-Fitted Filter
Polynomial regression is a powerful tool in the field of data analysis, used to model the relationship between a dependent variable and one or more independent variables. In the case of a moving average, the aim is to smooth out fluctuations in time series data and reveal underlying trends. The following provides a thorough analysis of a polynomial regression function that calculates a moving average, delving into the intricacies of the code and explaining the steps involved in the process.
Function Overview
The polynomialRegressionMA(src, deg, len) function takes three input parameters: src, deg, and len. The src parameter represents the source data or time series, deg is the degree of the polynomial regression, and len is the length of the moving average window. Throughout the following description, we will discuss the various components of this function, explaining the role of each part in the overall process.
polynomialRegressionMA(src, deg, len)=>
float sumout = src
AX = matrix.new(12, 12, 0.)
float BX = array.new(12, 0.)
float ZX = array.new(12, 0.)
float Pow = array.new(12, 0.)
int Row = array.new(12, 0)
float CX = array.new(12, 0.)
for k = 1 to len
float YK = nz(src )
int XK = k
int Prod = 1
for j = 1 to deg + 1
array.set(BX, j, array.get(BX, j) + YK * Prod)
Prod *= XK
array.set(Pow, 0, len)
for k = 1 to len
int XK = k
int Prod = k
for j = 1 to 2 * deg
array.set(Pow, j, array.get(Pow, j) + Prod)
Prod *= XK
for j = 1 to deg + 1
for l = 1 to deg + 1
matrix.set(AX, j, l, array.get(Pow, j + l - 2))
for j = 1 to deg + 1
array.set(Row, j, j)
for i = 1 to deg
for k = i + 1 to deg + 1
if math.abs(matrix.get(AX, array.get(Row, k), i)) >
math.abs(matrix.get(AX, array.get(Row, i), i))
temp = array.get(Row, i)
array.set(Row, i, array.get(Row, k))
array.set(Row, k, temp)
for k = i + 1 to deg + 1
if matrix.get(AX, array.get(Row, i), i) != 0
matrix.set(AX, array.get(Row, k), i,
matrix.get(AX, array.get(Row, k), i) /
matrix.get(AX, array.get(Row, i), i))
for l = i + 1 to deg + 1
matrix.set(AX, array.get(Row, k), l,
matrix.get(AX, array.get(Row, k), l) -
matrix.get(AX, array.get(Row, k), i) *
matrix.get(AX, array.get(Row, i), l))
array.set(ZX, 1, array.get(BX, array.get(Row, 1)))
for k = 2 to deg + 1
float sum = 0.
for l = 1 to k - 1
sum += matrix.get(AX, array.get(Row, k), l) * array.get(ZX, l)
array.set(ZX, k, array.get(BX, array.get(Row, k)) - sum)
if matrix.get(AX, array.get(Row, deg + 1), deg + 1) != 0.
array.set(CX, deg + 1, array.get(ZX, deg + 1) / matrix.get(AX, array.get(Row, deg + 1), deg + 1))
for k = deg to 1
float sum = 0.
for l = k + 1 to deg + 1
sum += matrix.get(AX, array.get(Row, k), l) * array.get(CX, l)
array.set(CX, k, (array.get(ZX, k) - sum) / matrix.get(AX, array.get(Row, k), k))
sumout := array.get(CX, deg + 1)
for k = deg to 1
sumout := array.get(CX, k) + sumout * len
sumout
Variable Initialization
At the beginning of the function, several arrays and matrices are initialized: sumout, AX, BX, ZX, Pow, Row, and CX. These variables are used to store intermediate results and perform the necessary calculations.
sumout: This variable will store the final moving average result.
AX: A matrix that stores the coefficients of the system of linear equations representing the polynomial regression.
BX: An array that holds the values required for calculating the moving average.
ZX: An array used for storing intermediate results during the Gaussian elimination process.
Pow: An array containing the powers of the independent variable.
Row: An array that keeps track of the row order in the AX matrix.
CX: An array that stores the calculated coefficients of the polynomial regression.
Calculating the BX Array
The function begins by iterating through the length of the moving average window and the degree of the polynomial regression. The purpose of these nested loops is to calculate the values for the BX array. The outer loop iterates from 1 to len, while the inner loop iterates from 1 to deg + 1.
During each iteration, the YK variable is assigned the non-zero value of the source data at the index (len - k), and the XK variable is assigned the current value of k. The Prod variable is initialized with the value 1, and the inner loop calculates the product of YK and Prod. The value of Prod is then updated by multiplying it with XK.
After completing the inner loop, the BX array is updated by adding the product of YK and Prod to its current value at index j. This process continues until both loops are completed, and the BX array contains the necessary values for further calculations.
Calculating the Pow Array
Next, the function initializes the Pow array by setting its 0th element to the length of the moving average window. The Pow array will store the powers of the independent variable. The function then iterates through the length of the moving average window (from 1 to len) and calculates the values of the Pow array based on the polynomial degree.
During each iteration, the XK variable is assigned the current value of k, and the Prod variable is assigned the value of k. The loop then iterates from 1 to 2 * deg, updating the Pow array by adding the current value of Prod to the array element at index j. The value of Prod is updated by multiplying it with XK. Once the loop is complete, the Pow array contains the necessary values for initializing the AX matrix.
Initializing the AX Matrix
Following the calculation of the Pow array, the function initializes the AX matrix using the values from the Pow array. The AX matrix is a square matrix with dimensions (deg + 1) x (deg + 1) and is used to store the coefficients of the polynomial regression.
The function iterates through two nested loops, with the outer loop iterating from 1 to deg + 1 and the inner loop iterating from 1 to deg + 1 as well. During each iteration, the AX matrix is updated by setting the element at position (j, l) to the corresponding value from the Pow array at index (j + l - 2). This process continues until both loops are completed, and the AX matrix is fully populated with the necessary values.
Initializing the Row Array
The next part of the function initializes the Row array, which will be used later to keep track of the row order in the AX matrix. The function iterates through a loop that assigns each element of the array to its index (1 to deg + 1).
Gaussian Elimination
The function employs Gaussian elimination to solve the system of linear equations represented by the AX matrix. Gaussian elimination is an algorithm used to solve linear systems by transforming the system into a triangular matrix using a series of row operations, such as swapping rows, multiplying rows by constants, and adding or subtracting rows.
The function iterates through the deg elements, performing several nested loops that compare, swap, divide, and subtract the matrix elements accordingly. The outer loop iterates from 1 to deg, and the first inner loop iterates from i + 1 to deg + 1. This loop compares the absolute values of the matrix elements and swaps the rows when necessary. The process of comparing and swapping rows ensures that the matrix is in the proper format for Gaussian elimination.
The second inner loop iterates from i + 1 to deg + 1 and is responsible for dividing the matrix elements. If the matrix element at the position (array.get(Row, i), i) is not equal to 0, the matrix element at the position (array.get(Row, k), i) is divided by the matrix element at the position (array.get(Row, i), i).
The third inner loop iterates from i + 1 to deg + 1 and subtracts the matrix elements accordingly. This subtraction process eliminates the coefficients below the main diagonal, effectively transforming the AX matrix into an upper triangular matrix.
Back-substitution and Calculating the CX Array
The function proceeds to perform back-substitution to find the solution to the linear system. The ZX array is filled with the results from the BX array and the Row array. Then, the back-substitution process begins, and the CX array is filled with the calculated coefficients for the polynomial regression.
The function iterates from 1 to deg + 1 to update the ZX array. During each iteration, a sum variable is initialized to 0, and an inner loop iterates from 1 to k - 1. Inside this loop, the sum variable is incremented by the product of the AX matrix element at the position (array.get(Row, k), l) and the ZX array element at index l. After the inner loop, the ZX array is updated by subtracting the sum from the BX array element at the index array.get(Row, k).
Once the ZX array is updated, the function checks if the AX matrix element at the position (array.get(Row, deg + 1), deg + 1) is not equal to 0. If this condition is met, the CX array element at the index (deg + 1) is updated by dividing the ZX array element at the index (deg + 1) by the AX matrix element at the position (array.get(Row, deg + 1), deg + 1).
The function then iterates from deg to 1 in reverse order to update the CX array. A sum variable is initialized to 0, and an inner loop iterates from k + 1 to deg + 1. Inside this loop, the sum variable is incremented by the product of the AX matrix element at the position (array.get(Row, k), l) and the CX array element at index l. After the inner loop, the CX array element at index k is updated by dividing the difference between the ZX array element at index k and the sum by the AX matrix element at the position (array.get(Row, k), k). Once this process is completed, the CX array contains the calculated coefficients of the polynomial regression.
Calculating the Moving Average
The final step of the function is to calculate the moving average using the coefficients stored in the CX array. To do this, the function iterates through the degree of the polynomial regression in reverse order, starting with the highest degree and ending with the lowest. The result is stored in the sumout variable.
The loop iterates from deg to 1. During each iteration, the sumout variable is updated by adding the CX array element at index k to the product of the sumout variable and the length of the moving average window (len). This process continues until the loop is complete, and the sumout variable contains the final moving average value.
Returning the Moving Average
The function concludes by returning the sumout variable, which represents the moving average value at the current data point. The polyout variable is assigned the result of the polynomialRegressionMA(src, dgr, flen) function, and the sig variable is assigned the first element of the polyout array, indicating that the moving average value at the current data point is stored in the sig variable.
Conclusion
The provided code is a comprehensive implementation of a polynomial regression function that calculates the moving average of a given time series data set (src) using a specified polynomial degree (deg) and a specified moving average window length (len). The function employs Gaussian elimination and back-substitution techniques to solve the system of linear equations and find the coefficients for the polynomial regression. These coefficients are then used to compute the moving average.
In conclusion, we dissected the code of a polynomial regression function that creates a moving average, explaining each component's role in the overall process. The function demonstrates the power of polynomial regression in smoothing out fluctuations in time series data and revealing underlying trends, making it a valuable tool in the field of data analysis.
█ Giga Kaleidoscope Modularized Trading System
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, the Average Directional Index (ADX), and the Chandelier Exit.
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: Polynomial-Regression-Fitted Filter as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Volatility/Volume Entry
1. GKD-V Volatility/Volume signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
1-Candle Rule Volatility/Volume Entry
1. GKD-V Volatility/Volume signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close)
2. GKD-B Volatility/Volume agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-B Baseline agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
2. GKD-C Confirmation 1 agrees
3. GKD-C Confirmation 2 agrees
4. GKD-V Volatility/Volume Agrees
]█ Setting up the GKD
The GKD system involves chaining indicators together. These are the steps to set this up.
Use a GKD-C indicator alone on a chart
1. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Simple"
Use a GKD-V indicator alone on a chart
**nothing, it's already useable on the chart without any settings changes
Use a GKD-B indicator alone on a chart
**nothing, it's already useable on the chart without any settings changes
Baseline (Baseline, Backtest)
1. Import the GKD-B Baseline into the GKD-BT Backtest: "Input into Volatility/Volume or Backtest (Baseline testing)"
2. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Baseline"
Volatility/Volume (Volatility/Volume, Backte st)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Solo"
2. Inside the GKD-V indicator, change the "Signal Type" setting to "Crossing" (neither traditional nor both can be backtested)
3. Import the GKD-V indicator into the GKD-BT Backtest: "Input into C1 or Backtest"
4. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Volatility/Volume"
5. Inside the GKD-BT Backtest, a) change the setting "Backtest Type" to "Trading" if using a directional GKD-V indicator; or, b) change the setting "Backtest Type" to "Full" if using a directional or non-directional GKD-V indicator (non-directional GKD-V can only test Longs and Shorts separately)
6. If "Backtest Type" is set to "Full": Inside the GKD-BT Backtest, change the setting "Backtest Side" to "Long" or "Short
7. If "Backtest Type" is set to "Full": To allow the system to open multiple orders at one time so you test all Longs or Shorts, open the GKD-BT Backtest, click the tab "Properties" and then insert a value of something like 10 orders into the "Pyramiding" settings. This will allow 10 orders to be opened at one time which should be enough to catch all possible Longs or Shorts.
Solo Confirmation Simple (Confirmation, Backtest)
1. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Simple"
1. Import the GKD-C indicator into the GKD-BT Backtest: "Input into Backtest"
2. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Solo Confirmation Simple"
Solo Confirmation Complex without Exits (Baseline, Volatility/Volume, Confirmation, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Complex"
4. Import the GKD-V indicator into the GKD-C indicator: "Input into C1 or Backtest"
5. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full wo/ Exits"
6. Import the GKD-C into the GKD-BT Backtest: "Input into Exit or Backtest"
Solo Confirmation Complex with Exits (Baseline, Volatility/Volume, Confirmation, Exit, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Complex"
4. Import the GKD-V indicator into the GKD-C indicator: "Input into C1 or Backtest"
5. Import the GKD-C indicator into the GKD-E indicator: "Input into Exit"
6. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full w/ Exits"
7. Import the GKD-E into the GKD-BT Backtest: "Input into Backtest"
Full GKD without Exits (Baseline, Volatility/Volume, Confirmation 1, Confirmation 2, Continuation, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C 1 indicator, change the "Confirmation Type" setting to "Confirmation 1"
4. Import the GKD-V indicator into the GKD-C 1 indicator: "Input into C1 or Backtest"
5. Inside the GKD-C 2 indicator, change the "Confirmation Type" setting to "Confirmation 2"
6. Import the GKD-C 1 indicator into the GKD-C 2 indicator: "Input into C2"
7. Inside the GKD-C Continuation indicator, change the "Confirmation Type" setting to "Continuation"
8. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full wo/ Exits"
9. Import the GKD-E into the GKD-BT Backtest: "Input into Exit or Backtest"
Full GKD with Exits (Baseline, Volatility/Volume, Confirmation 1, Confirmation 2, Continuation, Exit, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C 1 indicator, change the "Confirmation Type" setting to "Confirmation 1"
4. Import the GKD-V indicator into the GKD-C 1 indicator: "Input into C1 or Backtest"
5. Inside the GKD-C 2 indicator, change the "Confirmation Type" setting to "Confirmation 2"
6. Import the GKD-C 1 indicator into the GKD-C 2 indicator: "Input into C2"
7. Inside the GKD-C Continuation indicator, change the "Confirmation Type" setting to "Continuation"
8. Import the GKD-C Continuation indicator into the GKD-E indicator: "Input into Exit"
9. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full w/ Exits"
10. Import the GKD-E into the GKD-BT Backtest: "Input into Backtest"
Baseline + Volatility/Volume (Baseline, Volatility/Volume, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Baseline + Volatility/Volume"
2. Inside the GKD-V indicator, make sure the "Signal Type" setting is set to "Traditional"
3. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
4. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Baseline + Volatility/Volume"
5. Import the GKD-V into the GKD-BT Backtest: "Input into C1 or Backtest"
6. Inside the GKD-BT Backtest, change the setting "Backtest Type" to "Full". For this backtest, you must test Longs and Shorts separately
7. To allow the system to open multiple orders at one time so you can test all Longs or Shorts, open the GKD-BT Backtest, click the tab "Properties" and then insert a value of something like 10 orders into the "Pyramiding" settings. This will allow 10 orders to be opened at one time which should be enough to catch all possible Longs or Shorts.
Requirements
Inputs
Confirmation 1: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Continuation: GKD-C Confirmation indicator
Solo Confirmation Simple: GKD-B Baseline
Solo Confirmation Complex: GKD-V Volatility / Volume indicator
Solo Confirmation Super Complex: GKD-V Volatility / Volume indicator
Stacked 1: None
Stacked 2+: GKD-C, GKD-V, or GKD-B Stacked 1
Outputs
Confirmation 1: GKD-C Confirmation 2 indicator
Confirmation 2: GKD-C Continuation indicator
Continuation: GKD-E Exit indicator
Solo Confirmation Simple: GKD-BT Backtest
Solo Confirmation Complex: GKD-BT Backtest or GKD-E Exit indicator
Solo Confirmation Super Complex: GKD-C Continuation indicator
Stacked 1: GKD-C, GKD-V, or GKD-B Stacked 2+
Stacked 2+: GKD-C, GKD-V, or GKD-B Stacked 2+ or GKD-BT Backtest
Additional features will be added in future releases.

Polynomial Regression Derivatives [Loxx]Polynomial Regression Derivatives is an indicator that explores the different derivatives of polynomial position. This indicator also includes a signal line. In a later release, alerts with signal markings will be added.
Polynomial Derivatives are as follows
1rst Derivative - Velocity: Velocity is the directional speed of a object in motion as an indication of its rate of change in position as observed from a particular frame of reference and as measured by a particular standard of time (e.g. 60 km/h northbound). Velocity is a fundamental concept in kinematics, the branch of classical mechanics that describes the motion of bodies.
2nd Derivative - Acceleration: In mechanics, acceleration is the rate of change of the velocity of an object with respect to time. Accelerations are vector quantities (in that they have magnitude and direction). The orientation of an object's acceleration is given by the orientation of the net force acting on that object.
3rd Derivative - Jerk: In physics, jerk or jolt is the rate at which an object's acceleration changes with respect to time. It is a vector quantity (having both magnitude and direction). Jerk is most commonly denoted by the symbol j and expressed in m/s3 (SI units) or standard gravities per second (g0/s).
4th Derivative - Snap: Snap, or jounce, is the fourth derivative of the position vector with respect to time, or the rate of change of the jerk with respect to time. Equivalently, it is the second derivative of acceleration or the third derivative of velocity.
5th Derivative - Crackle: The fifth derivative of the position vector with respect to time is sometimes referred to as crackle. It is the rate of change of snap with respect to time.
6nd Derivative - Pop: The sixth derivative of the position vector with respect to time is sometimes referred to as pop. It is the rate of change of crackle with respect to time.
Included:
Loxx's Expanded Source Types
Loxx's Moving Averages

Polynomial Regression Bands w/ Extrapolation of Price [Loxx]Polynomial Regression Bands w/ Extrapolation of Price is a moving average built on Polynomial Regression. This indicator paints both a non-repainting moving average and also a projection forecast based on the Polynomial Regression. I've included 33 source types and 38 moving average types to smooth the price input before it's run through the Polynomial Regression algorithm. This indicator only paints X many bars back so as to increase on screen calculation speed. Make sure to read the tooltips to answer any questions you have.
What is Polynomial Regression?
In statistics, polynomial regression is a form of regression analysis in which the relationship between the independent variable x and the dependent variable y is modeled as an nth degree polynomial in x. Polynomial regression fits a nonlinear relationship between the value of x and the corresponding conditional mean of y, denoted E(y |x). Although polynomial regression fits a nonlinear model to the data, as a statistical estimation problem it is linear, in the sense that the regression function E(y | x) is linear in the unknown parameters that are estimated from the data. For this reason, polynomial regression is considered to be a special case of multiple linear regression .
Related indicators
Polynomial-Regression-Fitted Oscillator
Polynomial-Regression-Fitted RSI
PA-Adaptive Polynomial Regression Fitted Moving Average
Poly Cycle
Fourier Extrapolator of Price w/ Projection Forecast
PA-Adaptive Polynomial Regression Fitted Moving Average [Loxx]PA-Adaptive Polynomial Regression Fitted Moving Average is a moving average that is calculated using Polynomial Regression Analysis. The purpose of this indicator is to introduce polynomial fitting that is to be used in future indicators. This indicator also has Phase Accumulation adaptive period inputs. Even though this first indicator is for demonstration purposes only, its still one of the only viable implementations of Polynomial Regression Analysis on TradingView is suitable for trading, and while this same method can be used to project prices forward, I won't be doing that since forecasting is generally worthless and causes unavoidable repainting. This indicator only repaints on the current bar. Once the bar closes, any signal on that bar won't change.
For other similar Polynomial Regression Fitted methodologies, see here
Poly Cycle
What is the Phase Accumulation Cycle?
The phase accumulation method of computing the dominant cycle is perhaps the easiest to comprehend. In this technique, we measure the phase at each sample by taking the arctangent of the ratio of the quadrature component to the in-phase component. A delta phase is generated by taking the difference of the phase between successive samples. At each sample we can then look backwards, adding up the delta phases.When the sum of the delta phases reaches 360 degrees, we must have passed through one full cycle, on average.The process is repeated for each new sample.
The phase accumulation method of cycle measurement always uses one full cycle’s worth of historical data.This is both an advantage and a disadvantage.The advantage is the lag in obtaining the answer scales directly with the cycle period.That is, the measurement of a short cycle period has less lag than the measurement of a longer cycle period. However, the number of samples used in making the measurement means the averaging period is variable with cycle period. longer averaging reduces the noise level compared to the signal.Therefore, shorter cycle periods necessarily have a higher out- put signal-to-noise ratio.
What is Polynomial Regression?
In statistics, polynomial regression is a form of regression analysis in which the relationship between the independent variable x and the dependent variable y is modelled as an nth degree polynomial in x. Polynomial regression fits a nonlinear relationship between the value of x and the corresponding conditional mean of y, denoted E(y |x). Although polynomial regression fits a nonlinear model to the data, as a statistical estimation problem it is linear, in the sense that the regression function E(y | x) is linear in the unknown parameters that are estimated from the data. For this reason, polynomial regression is considered to be a special case of multiple linear regression.
Things to know
You can select from 33 source types
The source is smoothed before being injected into the Polynomial fitting algorithm, there are 35+ moving averages to choose from for smoothing
The output of the Polynomial fitting algorithm is then smoothed to create the signal, there are 35+ moving averages to choose from for smoothing
Included
Alerts
Signals
Bar coloring