Risk Distribution HistogramStatistical risk visualization and analysis tool for any ticker 📊
The Risk Distribution Histogram visualizes the statistical distribution of different risk metrics for any financial instrument. It converts risk data into histograms with quartile-based color coding, so that traders can understand their risk, tail-risks, exposure patterns and make data-driven decisions based on empirical evidence rather than assumptions.
The indicator supports multiple risk calculation methods, each designed for different aspects of market analysis, from general volatility assessment to tail risk analysis.
Risk Measurement Methods
Standard Deviation
Captures raw daily price volatility by measuring the dispersion of price movements. Ideal for understanding overall market conditions and timing volatility-based strategies.
Use case: Options trading and volatility analysis.
Average True Range (ATR)
Measures true range as a percentage of price, accounting for gaps and limit moves. Valuable for position sizing across different price levels.
Use case: Position sizing and stop-loss placement.
The chart above illustrates how ATR statistical distribution can be used by looking at the ATR % of price distribution. For example, 90% of the movements are below 5%.
Downside Deviation
Only considers negative price movements, making it ideal for checking downside risk and capital protection rather than capturing upside volatility.
Use case: Downside protection strategies and stop losses.
Drawdown Analysis
Tracks peak-to-trough declines, providing insight into maximum loss potential during different market conditions.
Use case: Risk management and capital preservation.
The chart above illustrates tale risk for the asset (TQQQ), showing that it is possible to have drawdowns higher than 20%.
Entropy-Based Risk (EVaR)
Uses information theory to quantify market uncertainty. Higher entropy values indicate more unpredictable price action, valuable for detecting regime changes.
Use case: Advanced risk modeling and tail-risk.
VIX Histogram
Incorporates the market's fear index directly into analysis, showing how current volatility expectations compare to historical patterns. The CAPITALCOM:VIX histogram is independent from the ticker on the chart.
Use case: Volatility trading and market timing.
Visual Features
The histogram uses quartile-based color coding that immediately shows where current risk levels stand relative to historical patterns:
Green (Q1): Low Risk (0-25th percentile)
Yellow (Q2): Medium-Low Risk (25-50th percentile)
Orange (Q3): Medium-High Risk (50-75th percentile)
Red (Q4): High Risk (75-100th percentile)
The data table provides detailed statistics, including:
Count Distribution: Historical observations in each bin
PMF: Percentage probability for each risk level
CDF: Cumulative probability up to each level
Current Risk Marker: Shows your current position in the distribution
Trading Applications
When current risk falls into upper quartiles (Q3 or Q4), it signals conditions are riskier than 50-75% of historical observations. This guides position sizing and portfolio adjustments.
Key applications:
Position sizing based on empirical risk distributions
Monitoring risk regime changes over time
Comparing risk patterns across timeframes
Risk distribution analysis improves trade timing by identifying when market conditions favor specific strategies.
Enter positions during low-risk periods (Q1)
Reduce exposure in high-risk periods (Q4)
Use percentile rankings for dynamic stop-loss placement
Time volatility strategies using distribution patterns
Detect regime shifts through distribution changes
Compare current conditions to historical benchmarks
Identify outlier events in tail regions
Validate quantitative models with empirical data
Configuration Options
Data Collection
Lookback Period: Control amount of historical data analyzed
Date Range Filtering: Focus on specific market periods
Sample Size Validation: Automatic reliability warnings
Histogram Customization
Bin Count: 10-50 bins for different detail levels
Auto/Manual Bin Width: Optimize for your data range
Visual Preferences: Custom colors and font sizes
Implementation Guide
Start with Standard Deviation on daily charts for the most intuitive introduction to distribution-based risk analysis.
Method Selection: Begin with Standard Deviation
Setup: Use daily charts with 20-30 bins
Interpretation: Focus on quartile transitions as signals
Monitoring: Track distribution changes for regime detection
The tool provides comprehensive statistics including mean, standard deviation, quartiles, and current position metrics like Z-score and percentile ranking.
Enjoy, and please let me know your feedback! 😊🥂
Probability

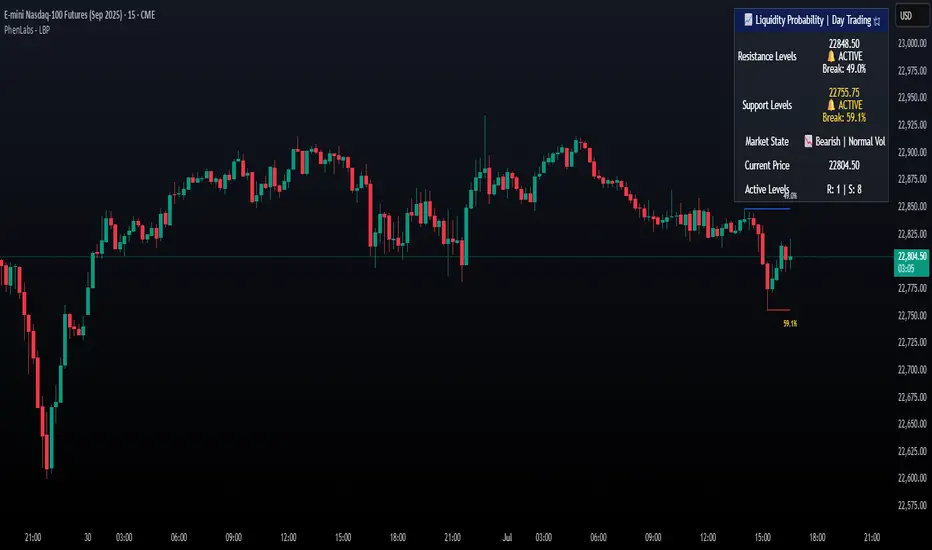
Liquidity Break Probability [PhenLabs]📊 Liquidity Break Probability
Version: PineScript™ v6
The Liquidity Break Probability indicator revolutionizes how traders approach liquidity levels by providing real-time probability calculations for level breaks. This advanced indicator combines sophisticated market analysis with machine learning inspired probability models to predict the likelihood of high/low breaks before they happen.
Unlike traditional liquidity indicators that simply draw lines, LBP analyzes market structure, volume profiles, momentum, volatility, and sentiment to generate dynamic break probabilities ranging from 5% to 95%. This gives traders unprecedented insight into which levels are most likely to hold or break, enabling more confident trading decisions.
🚀 Points of Innovation
Advanced 6-factor probability model weighing market structure, volatility, volume, momentum, patterns, and sentiment
Real-time probability updates that adjust as market conditions change
Intelligent trading style presets (Scalping, Day Trading, Swing Trading) with optimized parameters
Dynamic color-coded probability labels showing break likelihood percentages
Professional tiered input system - from quick setup to expert-level customization
Smart volume filtering that only highlights levels with significant institutional interest
🔧 Core Components
Market Structure Analysis: Evaluates trend alignment, level strength, and momentum buildup using EMA crossovers and price action
Volatility Engine: Incorporates ATR expansion, Bollinger Band positioning, and price distance calculations
Volume Profile System: Analyzes current volume strength, smart money proxies, and level creation volume ratios
Momentum Calculator: Combines RSI positioning, MACD strength, and momentum divergence detection
Pattern Recognition: Identifies reversal patterns (doji, hammer, engulfing) near key levels
Sentiment Analysis: Processes fear/greed indicators and market breadth measurements
🔥 Key Features
Dynamic Probability Labels: Real-time percentage displays showing break probability with color coding (red >70%, orange >50%, white <50%)
Trading Style Optimization: One-click presets automatically configure sensitivity and parameters for your trading timeframe
Professional Dashboard: Live market state monitoring with nearest level tracking and active level counts
Smart Alert System: Customizable proximity alerts and high-probability break notifications
Advanced Level Management: Intelligent line cleanup and historical analysis options
Volume-Validated Levels: Only displays levels backed by significant volume for institutional-grade analysis
🎨 Visualization
Recent Low Lines: Red lines marking validated support levels with probability percentages
Recent High Lines: Blue lines showing resistance zones with break likelihood indicators
Probability Labels: Color-coded percentage labels that update in real-time
Professional Dashboard: Customizable panel showing market state, active levels, and current price
Clean Display Modes: Toggle between active-only view for clean charts or historical view for analysis
📖 Usage Guidelines
Quick Setup
Trading Style Preset
Default: Day Trading
Options: Scalping, Day Trading, Swing Trading, Custom
Description: Automatically optimizes all parameters for your preferred trading timeframe and style
Show Break Probability %
Default: True
Description: Displays percentage labels next to each level showing break probability
Line Display
Default: Active Only
Options: Active Only, All Levels
Description: Choose between clean active-only view or comprehensive historical analysis
Level Detection Settings
Level Sensitivity
Default: 5
Range: 1-20
Description: Lower values show more levels (sensitive), higher values show fewer levels (selective)
Volume Filter Strength
Default: 2.0
Range: 0.5-5.0
Description: Controls minimum volume threshold for level validation
Advanced Probability Model
Market Trend Influence
Default: 25%
Range: 0-50%
Description: Weight given to overall market trend in probability calculations
Volume Influence
Default: 20%
Range: 0-50%
Description: Impact of volume analysis on break probability
✅ Best Use Cases
Identifying high-probability breakout setups before they occur
Determining optimal entry and exit points near key levels
Risk management through probability-based position sizing
Confluence trading when multiple high-probability levels align
Scalping opportunities at levels with low break probability
Swing trading setups using high-probability level breaks
⚠️ Limitations
Probability calculations are estimations based on historical patterns and current market conditions
High-probability setups do not guarantee successful trades - risk management is essential
Performance may vary significantly across different market conditions and asset classes
Requires understanding of support/resistance concepts and probability-based trading
Best used in conjunction with other analysis methods and proper risk management
💡 What Makes This Unique
Probability-Based Approach: First indicator to provide quantitative break probabilities rather than simple S/R lines
Multi-Factor Analysis: Combines 6 different market factors into a comprehensive probability model
Adaptive Intelligence: Probabilities update in real-time as market conditions change
Professional Interface: Tiered input system from beginner-friendly to expert-level customization
Institutional-Grade Filtering: Volume validation ensures only significant levels are displayed
🔬 How It Works
1. Level Detection:
Identifies pivot highs and lows using configurable sensitivity settings
Validates levels with volume analysis to ensure institutional significance
2. Probability Calculation:
Analyzes 6 key market factors: structure, volatility, volume, momentum, patterns, sentiment
Applies weighted scoring system based on user-defined factor importance
Generates probability score from 5% to 95% for each level
3. Real-Time Updates:
Continuously monitors price action and market conditions
Updates probability calculations as new data becomes available
Adjusts for level touches and changing market dynamics
💡 Note: This indicator works best on timeframes from 1-minute to 4-hour charts. For optimal results, combine with proper risk management and consider multiple timeframe analysis. The probability calculations are most accurate in trending markets with normal to high volatility conditions.
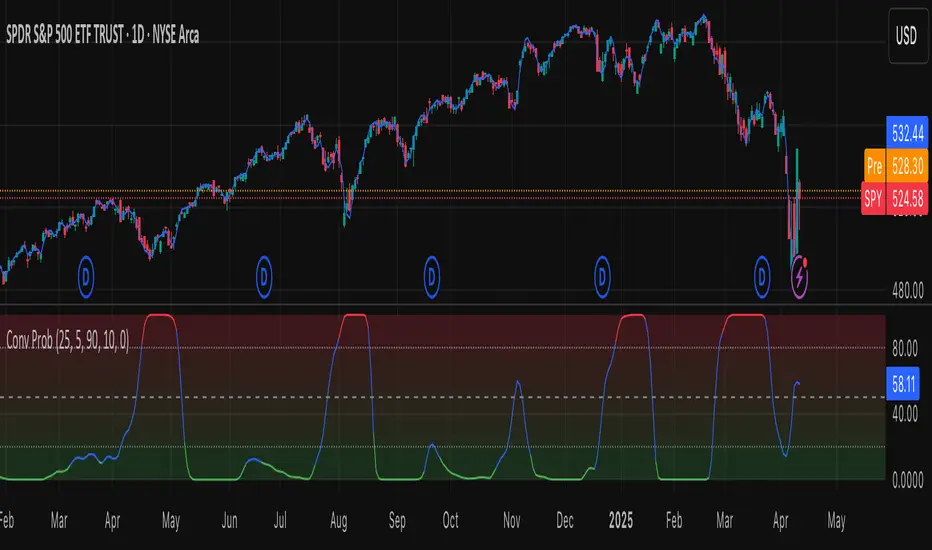
Leavitt Convolution ProbabilityTechnical Analysis of Markets with Leavitt Market Projections and Associated Convolution Probability
The aim of this study is to present an innovative approach to market analysis based on the research "Leavitt Market Projections." This technical tool combines one indicator and a probability function to enhance the accuracy and speed of market forecasts.
Key Features
Advanced Indicators : the script includes the Convolution line and a probability oscillator, designed to anticipate market changes. These indicators provide timely signals and offer a clear view of price dynamics.
Convolution Probability Function : The Convolution Probability (CP) is a key element of the script. A significant increase in this probability often precedes a market decline, while a decrease in probability can signal a bullish move. The Convolution Probability Function:
At each bar, i, the linear regression routine finds the two parameters for the straight line: y=mix+bi.
Standard deviations can be calculated from the sequence of slopes, {mi}, and intercepts, {bi}.
Each standard deviation has a corresponding probability.
Their adjusted product is the Convolution Probability, CP. The construction of the Convolution Probability is straightforward. The adjusted product is the probability of one times 1− the probability of the other.
Customizable Settings : Users can define oversold and overbought levels, as well as set an offset for the linear regression calculation. These options allow for tailoring the script to individual trading strategies and market conditions.
Statistical Analysis : Each analyzed bar generates regression parameters that allow for the calculation of standard deviations and associated probabilities, providing an in-depth view of market dynamics.
The results from applying this technical tool show increased accuracy and speed in market forecasts. The combination of Convolution indicator and the probability function enables the identification of turning points and the anticipation of market changes.
Additional information:
Leavitt, in his study, considers the SPY chart.
When the Convolution Probability (CP) is high, it indicates that the probability P1 (related to the slope) is high, and conversely, when CP is low, P1 is low and P2 is high.
For the calculation of probability, an approximate formula of the Cumulative Distribution Function (CDF) has been used, which is given by: CDF(x)=21(1+erf(σ2x−μ)) where μ is the mean and σ is the standard deviation.
For the calculation of probability, the formula used in this script is: 0.5 * (1 + (math.sign(zSlope) * math.sqrt(1 - math.exp(-0.5 * zSlope * zSlope))))
Conclusions
This study presents the approach to market analysis based on the research "Leavitt Market Projections." The script combines Convolution indicator and a Probability function to provide more precise trading signals. The results demonstrate greater accuracy and speed in market forecasts, making this technical tool a valuable asset for market participants.
Probability Grid [LuxAlgo]The Probability Grid tool allows traders to see the probability of where and when the next reversal would occur, it displays a 10x10 grid and/or dashboard with the probability of the next reversal occurring beyond each cell or within each cell.
🔶 USAGE
By default, the tool displays deciles (percentiles from 0 to 90), users can enable, disable and modify each percentile, but two of them must always be enabled or the tool will display an error message alerting of it.
The use of the tool is quite simple, as shown in the chart above, the further the price moves on the grid, the higher the probability of a reversal.
In this case, the reversal took place on the cell with a probability of 9%, which means that there is a probability of 91% within the square defined by the last reversal and this cell.
🔹 Grid vs Dashboard
The tool can display a grid starting from the last reversal and/or a dashboard at three predefined locations, as shown in the chart above.
🔶 DETAILS
🔹 Raw Data vs Normalized Data
By default the tool displays the normalized data, this means that instead of using the raw data (price delta between reversals) it uses the returns between each reversal, this is useful to make an apples to apples comparison of all the data in the dataset.
This can be seen in the left side of the chart above (BTCUSD Daily chart) where normalize data is disabled, the percentiles from 0 to 40 overlap and are indistinguishable from each other because the tool uses the raw price delta over the entire bitcoin history, with normalize data enabled as we can see in the right side of the chart we can have a fair comparison of the data over the entire history.
🔹 Probability Beyond or Within Each Cell
Two different probability modes are available, the default mode is Probability Beyond Each Cell, the number displayed in each cell is the probability of the next reversal to be located in the area beyond the cell, for example, if the cell displays 20%, it means that in the area formed by the square starting from the last reversal and ending at the cell, there is an 80% probability and outside that square there is a 20% probability for the location of the next reversal.
The second probability mode is the probability within each cell, this outlines the chance that the next reversal will be within the cell, as we can see on the right chart above, when using deciles as percentiles (default settings), each cell has the same 1% probability for the 10x10 grid.
🔶 SETTINGS
Swing Length: The maximum length in bars used to identify a swing
Maximum Reversals: Maximum number of reversals included in calculations
Normalize Data: Use returns between swings instead of raw price
Probability: Choose between two different probability modes: beyond and inside each cell
Percentiles: Enable/disable each of the ten percentiles and select the percentile number and line style
🔹 Dashboard
Show Dashboard: Enable or disable the dashboard
Position: Choose dashboard location
Size: Choose dashboard size
🔹 Style
Show Grid: Enable or disable the grid
Size: Choose grid text size
Colors: Choose grid background colors
Show Marks: Enable/disable reversal markers

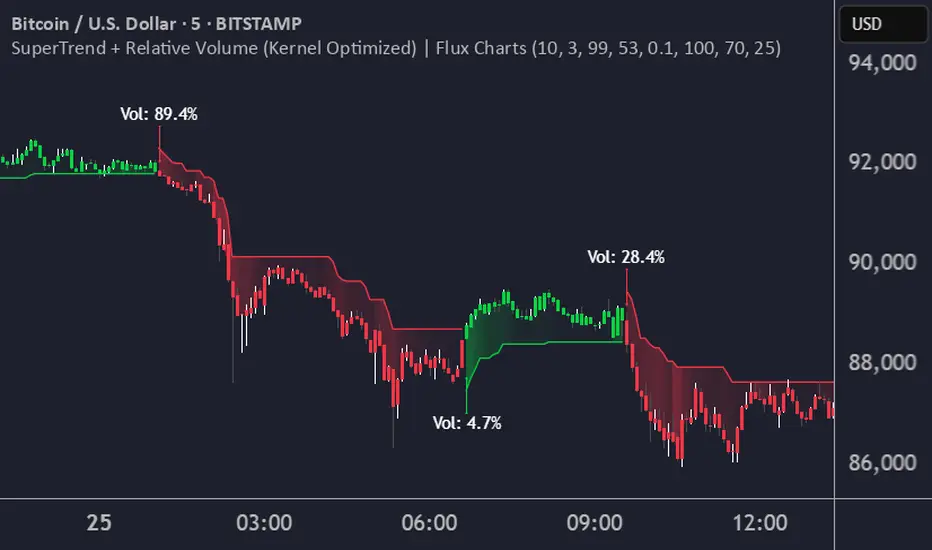
SuperTrend + Relative Volume (Kernel Optimized)Introducing our new KDE Optimized Supertrend + Relative Volume Indicator!
This innovative indicator combines the power of the Supertrend indicator along with Relative Volume. It utilizes the Kernel Density Estimation (KDE) to estimate the probability of a candlestick marking a significant trend break or reversal.
❓How to Interpret the KDE %:
The KDE % is a crucial metric that reflects the likelihood that the current candlestick represents a true break in the SuperTrend line, supported by an increase in relative volume. It estimates the probability of a trend shift or continuation based on historical SuperTrend breaks and volume patterns:
Low KDE %: A lower probability that the current break is significant. Price action is less likely to reverse, and the trend may continue.
Moderate KDE - High KDE %: An increased possibility that a trend reversal or consolidation could occur. Traders should start watching for confirmation signals.
📌How Does It Work?
The SuperTrend indicator uses the Average True Range (ATR) to determine the direction of the trend and identifies when the price crosses the SuperTrend line, signaling a potential trend reversal. Here's how the KDE Optimized SuperTrend Indicator works:
SuperTrend Calculation: The SuperTrend indicator is calculated, and when the price breaks above (bullish) or below (bearish) the SuperTrend line, it is logged as a significant event.
Relative Volume: For each break in the SuperTrend line, we calculate the relative volume (current volume vs. the average volume over a defined period). High relative volume can suggest stronger confirmation of the trend break.
KDE Array Calculation: KDE is applied to the break points and relative volume data:
Define the KDE options: Bandwidth, Number of Steps, and Array Range (Array Max - Array Min).
Create a density range array using the defined number of steps, corresponding to potential break points.
Apply a Gaussian kernel function to the break points and volume data to estimate the likelihood of the trend break being significant.
KDE Value and Signal Generation: The KDE array is updated as each break occurs. The KDE % is calculated for the breakout candlestick, representing the likelihood of the trend break being significant. If the KDE value exceeds the defined activation threshold, a darker bullish or bearish arrow is plotted after bar confirmation. If the KDE value falls below the threshold, a more transparent arrow is drawn, indicating a possible but lower probability break.
⚙️Settings:
SuperTrend Settings:
ATR Length: The period over which the Average True Range (ATR) is calculated.
Multiplier: The multiplier applied to the ATR to determine the SuperTrend threshold.
KDE Settings:
Bandwidth: Determines the smoothness of the KDE function and the width of the influence of each break point.
Number of Bins (Steps): Defines the precision of the KDE algorithm, with higher values offering more detailed calculations.
KDE Threshold %: The level at which relative volume is considered significant for confirming a break.
Relative Volume Length: The number of historic candles used in calculating KDE %
Reversal Probability Zone & Levels [LuxAlgo]The Reversal Probability Zone & Levels tool allows traders to identify a zone starting from the last detected reversal to highlight the probability of where the next reversal would be from a price and time perspective.
Price and time levels within the zone are displayed for up to 4 percentiles defined by the user.
🔶 USAGE
By default, the tool displays a zone with the 25th, 50th, 75th and 90th percentiles on both the price and time axis, indicating where, when and how many of the past reversals have occurred.
Traders can select the length for swing detection and the maximum number of reversals for probability calculations. The tool considers both bullish and bearish reversals separately, which means that if the last reversal was a swing high, the zone would show the probabilities for the last defined Maximum reversals
The Maximum reversals value has a direct impact on the probabilities, the more data traders use the more significant the result, probabilities over 10 occurrences are far weak compared to probabilities over 1000 occurrences.
🔹 Percentiles
Traders can fine-tune the percentile parameters in the settings panel.
A given percentile means that the number of occurrences in the data set is less than or equal to the percentile.
In English, this means
Percentile 20th: 20% of the occurrences are less than or equal to this value, so 80% of the occurrences are greater than this value.
Percentile 50th: 50% of the occurrences are below and 50% are above this value.
Percentile 80th: 80% of occurrences are lower than or equal to this value, so 20% of occurrences are greater than this value.
🔹 Normalize data
The Normalize Data feature allows traders to make an apples to apples comparison when we have a lot of historical data on high timeframe charts, using returns between swings instead of raw price.
🔹 Display Style
By default, the tool has the No overlapping feature enabled to display a clean chart, traders can turn it off, but this can fill the chart with too much information and barely see the price.
Traders can enable/disable settings to show only the last zone and the swing markers on the chart.
🔶 SETTINGS
Swing Length: The maximum length in bars used to identify a swing
Maximum Reversals: Maximum number of reversals included in calculations
Normalize Data: Use returns between swings instead of raw price
Percentiles: Enable/disable each of the four percentiles and select the percentile number, line style, colors, and size
🔹 Style
No Overlapping Zones: Enable or disable the No overlap between zones feature
Show Only Last Zone: Enable/disable display of last zone only
Show Marks: Enable/disable reversal markers

QT RSI [ W.ARITAS ]The QT RSI is an innovative technical analysis indicator designed to enhance precision in market trend identification and decision-making. Developed using advanced concepts in quantum mechanics, machine learning (LSTM), and signal processing, this indicator provides actionable insights for traders across multiple asset classes, including stocks, crypto, and forex.
Key Features:
Dynamic Color Gradient: Visualizes market conditions for intuitive interpretation:
Green: Strong buy signal indicating bullish momentum.
Blue: Neutral or observation zone, suggesting caution or lack of a clear trend.
Red: Strong sell signal indicating bearish momentum.
Quantum-Enhanced RSI: Integrates adaptive energy levels, dynamic smoothing, and quantum oscillators for precise trend detection.
Hybrid Machine Learning Model: Combines LSTM neural networks and wavelet transforms for accurate prediction and signal refinement.
Customizable Settings: Includes advanced parameters for dynamic thresholds, sensitivity adjustment, and noise reduction using Kalman and Jurik filters.
How to Use:
Interpret the Color Gradient:
Green Zone: Indicates bullish conditions and potential buy opportunities. Look for upward momentum in the RSI plot.
Blue Zone: Represents a neutral or consolidation phase. Monitor the market for trend confirmation.
Red Zone: Indicates bearish conditions and potential sell opportunities. Look for downward momentum in the RSI plot.
Follow Overbought/Oversold Boundaries:
Use the upper and lower RSI boundaries to identify overbought and oversold conditions.
Leverage Advanced Filtering:
The smoothed signals and quantum oscillator provide a robust framework for filtering false signals, making it suitable for volatile markets.
Application: Ideal for traders and analysts seeking high-precision tools for:
Identifying entry and exit points.
Detecting market reversals and momentum shifts.
Enhancing algorithmic trading strategies with cutting-edge analytics.
GaussianDistributionLibrary "GaussianDistribution"
This library defines a custom type `distr` representing a Gaussian (or other statistical) distribution.
It provides methods to calculate key statistical moments and scores, including mean, median, mode, standard deviation, variance, skewness, kurtosis, and Z-scores.
This library is useful for analyzing probability distributions in financial data.
Disclaimer:
I am not a mathematician, but I have implemented this library to the best of my understanding and capacity. Please be indulgent as I tried to translate statistical concepts into code as accurately as possible. Feedback, suggestions, and corrections are welcome to improve the reliability and robustness of this library.
mean(source, length)
Calculate the mean (average) of the distribution
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
Returns: Mean (μ)
stdev(source, length)
Calculate the standard deviation (σ) of the distribution
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
Returns: Standard deviation (σ)
skewness(source, length, mean, stdev)
Calculate the skewness (γ₁) of the distribution
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
mean (float) : the mean (average) of the distribution
stdev (float) : the standard deviation (σ) of the distribution
@return Skewness (γ₁)
skewness(source, length)
Overloaded skewness to calculate from source and length
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
@return Skewness (γ₁)
mode(mean, stdev, skewness)
Estimate mode - Most frequent value in the distribution (approximation based on skewness)
Parameters:
mean (float) : the mean (average) of the distribution
stdev (float) : the standard deviation (σ) of the distribution
skewness (float) : the skewness (γ₁) of the distribution
@return Mode
mode(source, length)
Overloaded mode to calculate from source and length
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
@return Mode
median(mean, stdev, skewness)
Estimate median - Middle value of the distribution (approximation)
Parameters:
mean (float) : the mean (average) of the distribution
stdev (float) : the standard deviation (σ) of the distribution
skewness (float) : the skewness (γ₁) of the distribution
@return Median
median(source, length)
Overloaded median to calculate from source and length
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
@return Median
variance(stdev)
Calculate variance (σ²) - Square of the standard deviation
Parameters:
stdev (float) : the standard deviation (σ) of the distribution
@return Variance (σ²)
variance(source, length)
Overloaded variance to calculate from source and length
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
@return Variance (σ²)
kurtosis(source, length, mean, stdev)
Calculate kurtosis (γ₂) - Degree of "tailedness" in the distribution
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
mean (float) : the mean (average) of the distribution
stdev (float) : the standard deviation (σ) of the distribution
@return Kurtosis (γ₂)
kurtosis(source, length)
Overloaded kurtosis to calculate from source and length
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
@return Kurtosis (γ₂)
normal_score(source, mean, stdev)
Calculate Z-score (standard score) assuming a normal distribution
Parameters:
source (float) : Distribution source (typically a price or indicator series)
mean (float) : the mean (average) of the distribution
stdev (float) : the standard deviation (σ) of the distribution
@return Z-Score
normal_score(source, length)
Overloaded normal_score to calculate from source and length
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
@return Z-Score
non_normal_score(source, mean, stdev, skewness, kurtosis)
Calculate adjusted Z-score considering skewness and kurtosis
Parameters:
source (float) : Distribution source (typically a price or indicator series)
mean (float) : the mean (average) of the distribution
stdev (float) : the standard deviation (σ) of the distribution
skewness (float) : the skewness (γ₁) of the distribution
kurtosis (float) : the "tailedness" in the distribution
@return Z-Score
non_normal_score(source, length)
Overloaded non_normal_score to calculate from source and length
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
@return Z-Score
method init(this)
Initialize all statistical fields of the `distr` type
Namespace types: distr
Parameters:
this (distr)
method init(this, source, length)
Overloaded initializer to set source and length
Namespace types: distr
Parameters:
this (distr)
source (float)
length (int)
distr
Custom type to represent a Gaussian distribution
Fields:
source (series float) : Distribution source (typically a price or indicator series)
length (series int) : Window length for the distribution (must be >= 30 for meaningful statistics)
mode (series float) : Most frequent value in the distribution
median (series float) : Middle value separating the greater and lesser halves of the distribution
mean (series float) : μ (1st central moment) - Average of the distribution
stdev (series float) : σ or standard deviation (square root of the variance) - Measure of dispersion
variance (series float) : σ² (2nd central moment) - Squared standard deviation
skewness (series float) : γ₁ (3rd central moment) - Asymmetry of the distribution
kurtosis (series float) : γ₂ (4th central moment) - Degree of "tailedness" relative to a normal distribution
normal_score (series float) : Z-score assuming normal distribution
non_normal_score (series float) : Adjusted Z-score considering skewness and kurtosis
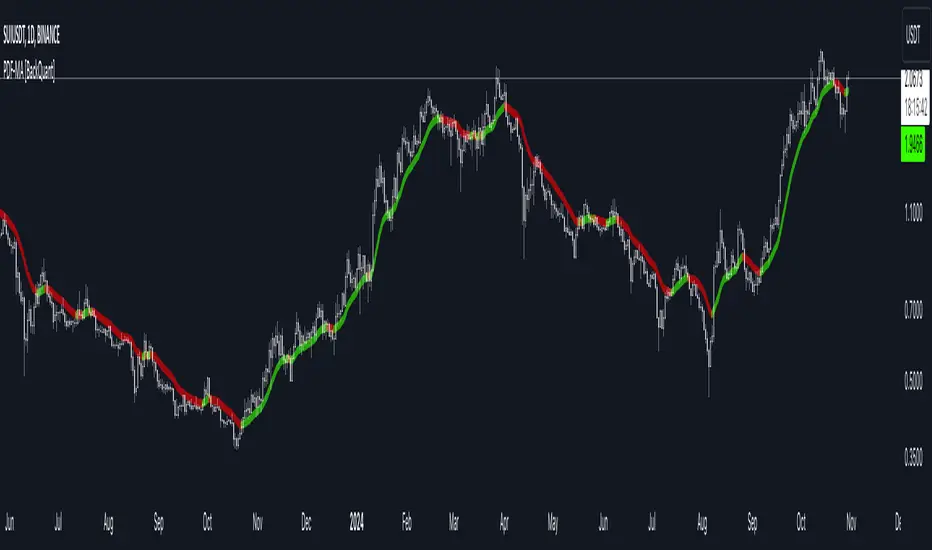
PDF Smoothed Moving Average [BackQuant]PDF Smoothed Moving Average
Introducing BackQuant’s PDF Smoothed Moving Average (PDF-MA) — an innovative trading indicator that applies Probability Density Function (PDF) weighting to moving averages, creating a unique, trend-following tool that offers adaptive smoothing to price movements. This advanced indicator gives traders an edge by blending PDF-weighted values with conventional moving averages, helping to capture trend shifts with enhanced clarity.
Core Concept: Probability Density Function (PDF) Smoothing
The Probability Density Function (PDF) provides a mathematical approach to applying adaptive weighting to data points based on a specified variance and mean. In the PDF-MA indicator, the PDF function is used to weight price data, adding a layer of probabilistic smoothing that enhances the detection of trend strength while reducing noise.
The PDF weights are controlled by two key parameters:
Variance: Determines the spread of the weights, where higher values spread out the weighting effect, providing broader smoothing.
Mean : Centers the weights around a particular price value, influencing the trend’s directionality and sensitivity.
These PDF weights are applied to each price point over the chosen period, creating an adaptive and smooth moving average that more closely reflects the underlying price trend.
Blending PDF with Standard Moving Averages
To further improve the PDF-MA, this indicator combines the PDF-weighted average with a traditional moving average, selected by the user as either an Exponential Moving Average (EMA) or Simple Moving Average (SMA). This blended approach leverages the strengths of each method: the responsiveness of PDF smoothing and the robustness of conventional moving averages.
Smoothing Method: Traders can choose between EMA and SMA for the additional moving average layer. The EMA is more responsive to recent prices, while the SMA provides a consistent average across the selected period.
Smoothing Period: Controls the length of the lookback period, affecting how sensitive the average is to price changes.
The result is a PDF-MA that provides a reliable trend line, reflecting both the PDF weighting and traditional moving average values, ideal for use in trend-following and momentum-based strategies.
Trend Detection and Candle Coloring
The PDF-MA includes a built-in trend detection feature that dynamically colors candles based on the direction of the smoothed moving average:
Uptrend: When the PDF-MA value is increasing, the trend is considered bullish, and candles are colored green, indicating potential buying conditions.
Downtrend: When the PDF-MA value is decreasing, the trend is considered bearish, and candles are colored red, signaling potential selling or shorting conditions.
These color-coded candles provide a quick visual reference for the trend direction, helping traders make real-time decisions based on the current market trend.
Customization and Visualization Options
This indicator offers a range of customization options, allowing traders to tailor it to their specific preferences and trading environment:
Price Source : Choose the price data for calculation, with options like close, open, high, low, or HLC3.
Variance and Mean : Fine-tune the PDF weighting parameters to control the indicator’s sensitivity and responsiveness to price data.
Smoothing Method : Select either EMA or SMA to customize the conventional moving average layer used in conjunction with the PDF.
Smoothing Period : Set the lookback period for the moving average, with a longer period providing more stability and a shorter period offering greater sensitivity.
Candle Coloring : Enable or disable candle coloring based on trend direction, providing additional clarity in identifying bullish and bearish phases.
Trading Applications
The PDF Smoothed Moving Average can be applied across various trading strategies and timeframes:
Trend Following : By smoothing price data with PDF weighting, this indicator helps traders identify long-term trends while filtering out short-term noise.
Reversal Trading : The PDF-MA’s trend coloring feature can help pinpoint potential reversal points by showing shifts in the trend direction, allowing traders to enter or exit positions at optimal moments.
Swing Trading : The PDF-MA provides a clear trend line that swing traders can use to capture intermediate price moves, following the trend direction until it shifts.
Final Thoughts
The PDF Smoothed Moving Average is a highly adaptable indicator that combines probabilistic smoothing with traditional moving averages, providing a nuanced view of market trends. By integrating PDF-based weighting with the flexibility of EMA or SMA smoothing, this indicator offers traders an advanced tool for trend analysis that adapts to changing market conditions with reduced lag and increased accuracy.
Whether you’re trading trends, reversals, or swings, the PDF-MA offers valuable insights into the direction and strength of price movements, making it a versatile addition to any trading strategy.
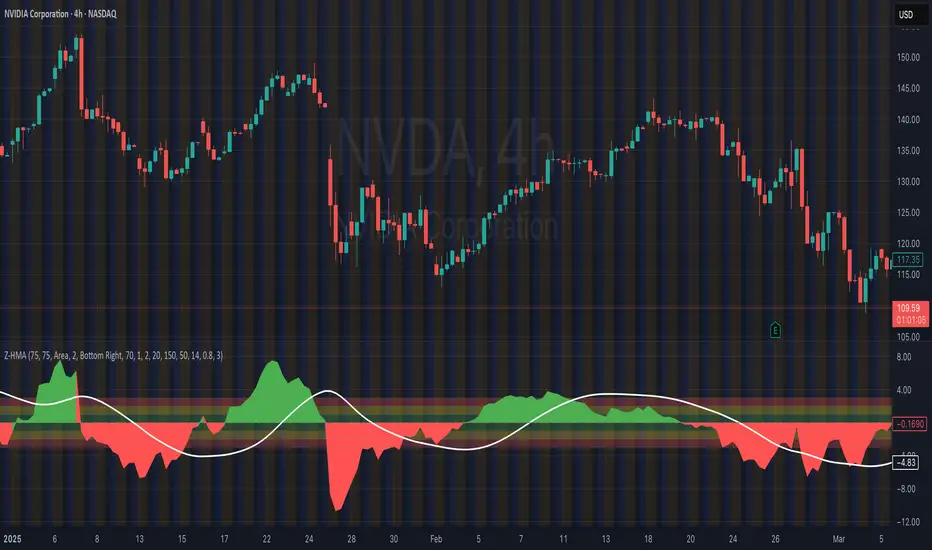
HMA Z-Score Probability Indicator by Erika BarkerThis indicator is a modified version of SteverSteves's original work, enhanced by Erika Barker. It visually represents asset price movements in terms of standard deviations from a Hull Moving Average (HMA), commonly known as a Z-Score.
Key Features:
Z-Score Calculation: Measures how many standard deviations the current price is from its HMA.
Hull Moving Average (HMA): This moving average provides a more responsive baseline for Z-Score calculations.
Flexible Display: Offers both area and candlestick visualization options for the Z-Score.
Probability Zones: Color-coded areas showing the statistical likelihood of prices based on their Z-Score.
Dynamic Price Level Labels: Displays actual price levels corresponding to Z-Score values.
Z-Table: An optional table showing the probability of occurrence for different Z-Score ranges.
Standard Deviation Lines: Horizontal lines at each standard deviation level for easy reference.
How It Works:
The indicator calculates the Z-Score by comparing the current price to its HMA and dividing by the standard deviation. This Z-Score is then plotted on a separate pane below the main chart.
Green areas/candles: Indicate prices above the HMA (positive Z-Score)
Red areas/candles: Indicate prices below the HMA (negative Z-Score)
Color-coded zones:
Green: Within 1 standard deviation (high probability)
Yellow: Between 1 and 2 standard deviations (medium probability)
Red: Beyond 2 standard deviations (low probability)
The HMA line (white) shows the trend of the Z-Score itself, offering insight into whether the asset is becoming more or less volatile over time.
Customization Options:
Adjust lookback periods for Z-Score and HMA calculations
Toggle between area and candlestick display
Show/hide probability fills, Z-Table, HMA line, and standard deviation bands
Customize text color and decimal rounding for price levels
Interpretation:
This indicator helps traders identify potential overbought or oversold conditions based on statistical probabilities. Extreme Z-Score values (beyond ±2 or ±3) often suggest a higher likelihood of mean reversion, while consistent Z-Scores in one direction may indicate a strong trend.
By combining the Z-Score with the HMA and probability zones, traders can gain a nuanced understanding of price movements relative to recent trends and their statistical significance.
Price Close ProbabilityThe Price Close Probability Indicator is designed to help traders estimate the likelihood of price closing above or below specified levels within a given bar. By placing two levels on your chart, you can quickly gauge the probability of the current price bar closing above or below these levels in real-time.
Key Features:
Dynamic Probability Calculation: The indicator continuously updates the probability of price closing above or below your set levels as the current bar progresses, providing you with timely insights as the bar approaches its close.
Customizable Standard Deviation : Adjust the length of the Standard Deviation used in the calculations to tailor the probability estimates to your preferred settings.
User-Friendly Probability Table : A clean, easy-to-read table displays the calculated probabilities, helping you make informed trading decisions at a glance.
Assumptions and Considerations:
While the indicator assumes that returns are normally distributed, which may not fully reflect reality, it still offers a valuable approximation of the probabilities for price movement within the current bar.
Future Enhancements (Coming Soon):
Multi-Bar Probability: Calculate probabilities across multiple bars to enhance your forecasting capabilities.
Additional Levels: Set more than two levels for a broader analysis of price movements.
Refined Distribution Modeling: Improve the accuracy of probability calculations by adjusting for more realistic return distributions.
Disclaimer
Please remember that past performance may not be indicative of future results.
Due to various factors, including changing market conditions, the strategy may no longer perform as well as in historical backtesting.
This post and the script don’t provide any financial advice.

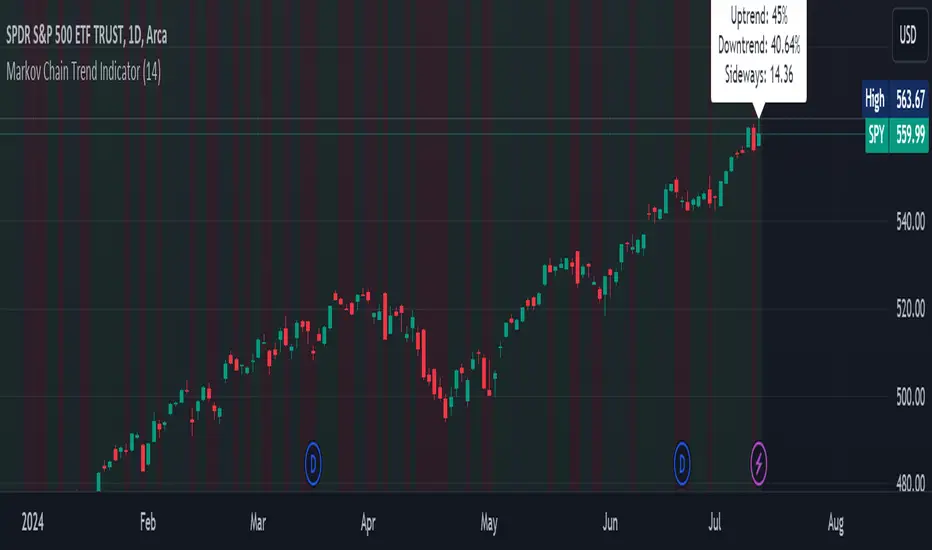
Markov Chain Trend IndicatorOverview
The Markov Chain Trend Indicator utilizes the principles of Markov Chain processes to analyze stock price movements and predict future trends. By calculating the probabilities of transitioning between different market states (Uptrend, Downtrend, and Sideways), this indicator provides traders with valuable insights into market dynamics.
Key Features
State Identification: Differentiates between Uptrend, Downtrend, and Sideways states based on price movements.
Transition Probability Calculation: Calculates the probability of transitioning from one state to another using historical data.
Real-time Dashboard: Displays the probabilities of each state on the chart, helping traders make informed decisions.
Background Color Coding: Visually represents the current market state with background colors for easy interpretation.
Concepts Underlying the Calculations
Markov Chains: A stochastic process where the probability of moving to the next state depends only on the current state, not on the sequence of events that preceded it.
Logarithmic Returns: Used to normalize price changes and identify states based on significant movements.
Transition Matrices: Utilized to store and calculate the probabilities of moving from one state to another.
How It Works
The indicator first calculates the logarithmic returns of the stock price to identify significant movements. Based on these returns, it determines the current state (Uptrend, Downtrend, or Sideways). It then updates the transition matrices to keep track of how often the price moves from one state to another. Using these matrices, the indicator calculates the probabilities of transitioning to each state and displays this information on the chart.
How Traders Can Use It
Traders can use the Markov Chain Trend Indicator to:
Identify Market Trends: Quickly determine if the market is in an uptrend, downtrend, or sideways state.
Predict Future Movements: Use the transition probabilities to forecast potential market movements and make informed trading decisions.
Enhance Trading Strategies: Combine with other technical indicators to refine entry and exit points based on predicted trends.
Example Usage Instructions
Add the Markov Chain Trend Indicator to your TradingView chart.
Observe the background color to quickly identify the current market state:
Green for Uptrend, Red for Downtrend, Gray for Sideways
Check the dashboard label to see the probabilities of transitioning to each state.
Use these probabilities to anticipate market movements and adjust your trading strategy accordingly.
Combine the indicator with other technical analysis tools for more robust decision-making.
Bayesian Trend Indicator [ChartPrime]Bayesian Trend Indicator
Overview:
In probability theory and statistics, Bayes' theorem (alternatively Bayes' law or Bayes' rule), named after Thomas Bayes, describes the probability of an event, based on prior knowledge of conditions that might be related to the event.
The "Bayesian Trend Indicator" is a sophisticated technical analysis tool designed to assess the direction of price trends in financial markets. It combines the principles of Bayesian probability theory with moving average analysis to provide traders with a comprehensive understanding of market sentiment and potential trend reversals.
At its core, the indicator utilizes multiple moving averages, including the Exponential Moving Average (EMA), Simple Moving Average (SMA), Double Exponential Moving Average (DEMA), and Volume Weighted Moving Average (VWMA) . These moving averages are calculated based on user-defined parameters such as length and gap length, allowing traders to customize the indicator to suit their trading strategies and preferences.
The indicator begins by calculating the trend for both fast and slow moving averages using a Smoothed Gradient Signal Function. This function assigns a numerical value to each data point based on its relationship with historical data, indicating the strength and direction of the trend.
// Smoothed Gradient Signal Function
sig(float src, gap)=>
ta.ema(source >= src ? 1 :
source >= src ? 0.9 :
source >= src ? 0.8 :
source >= src ? 0.7 :
source >= src ? 0.6 :
source >= src ? 0.5 :
source >= src ? 0.4 :
source >= src ? 0.3 :
source >= src ? 0.2 :
source >= src ? 0.1 :
0, 4)
Next, the indicator calculates prior probabilities using the trend information from the slow moving averages and likelihood probabilities using the trend information from the fast moving averages . These probabilities represent the likelihood of an uptrend or downtrend based on historical data.
// Define prior probabilities using moving averages
prior_up = (ema_trend + sma_trend + dema_trend + vwma_trend) / 4
prior_down = 1 - prior_up
// Define likelihoods using faster moving averages
likelihood_up = (ema_trend_fast + sma_trend_fast + dema_trend_fast + vwma_trend_fast) / 4
likelihood_down = 1 - likelihood_up
Using Bayes' theorem , the indicator then combines the prior and likelihood probabilities to calculate posterior probabilities, which reflect the updated probability of an uptrend or downtrend given the current market conditions. These posterior probabilities serve as a key signal for traders, informing them about the prevailing market sentiment and potential trend reversals.
// Calculate posterior probabilities using Bayes' theorem
posterior_up = prior_up * likelihood_up
/
(prior_up * likelihood_up + prior_down * likelihood_down)
Key Features:
◆ The trend direction:
To visually represent the trend direction , the indicator colors the bars on the chart based on the posterior probabilities. Bars are colored green to indicate an uptrend when the posterior probability is greater than 0.5 (>50%), while bars are colored red to indicate a downtrend when the posterior probability is less than 0.5 (<50%).
◆ Dashboard on the chart
Additionally, the indicator displays a dashboard on the chart , providing traders with detailed information about the probability of an uptrend , as well as the trends for each type of moving average. This dashboard serves as a valuable reference for traders to monitor trend strength and make informed trading decisions.
◆ Probability labels and signals:
Furthermore, the indicator includes probability labels and signals , which are displayed near the corresponding bars on the chart. These labels indicate the posterior probability of a trend, while small diamonds above or below bars indicate crossover or crossunder events when the posterior probability crosses the 0.5 threshold (50%).
The posterior probability of a trend
Crossover or Crossunder events
◆ User Inputs
Source:
Description: Defines the price source for the indicator's calculations. Users can select between different price values like close, open, high, low, etc.
MA's Length:
Description: Sets the length for the moving averages used in the trend calculations. A larger length will smooth out the moving averages, making the indicator less sensitive to short-term fluctuations.
Gap Length Between Fast and Slow MA's:
Description: Determines the difference in lengths between the slow and fast moving averages. A higher gap length will increase the difference, potentially identifying stronger trend signals.
Gap Signals:
Description: Defines the gap used for the smoothed gradient signal function. This parameter affects the sensitivity of the trend signals by setting the number of bars used in the signal calculations.
In summary, the "Bayesian Trend Indicator" is a powerful tool that leverages Bayesian probability theory and moving average analysis to help traders identify trend direction, assess market sentiment, and make informed trading decisions in various financial markets.

Bayesian Bias OscillatorWhat is a Bayes Estimator?
Bayesian estimation, or Bayesian inference, is a statistical method for estimating unknown parameters of a probability distribution based on observed data and prior knowledge about those parameters. At first , you will need a prior probability distribution, which is a prior belief about the distribution of the parameter that you are interested in estimating. This distribution represents your initial beliefs or knowledge about the parameter value before observing any data. Second , you need a likelihood function, which represents the probability of observing the data given different values of the parameter. This function quantifies how well different parameter values explain the observed data. Then , you will need a posterior probability distribution by combining the prior distribution and the likelihood function to obtain the posterior distribution of the parameter. The posterior distribution represents the updated belief about the parameter value after observing the data.
Bayesian Bias Oscillator
This tool calculates the Bayes bias of returns, which are directional probabilities that provide insight on the "trend" of the market or the directional bias of returns. It comes with two outputs: the default one, which is the Z-Score of the Bayes Bias, and the regular raw probability, which can be switched on in the settings of the indicator.
The Z-Score output value doesn't tell you the probability, but it does tell you how much of a standard deviation the value is from the mean. It uses both probabilities, the probability of a positive return and the probability of a negative return, which is just (1 - probability of a positive return).
The probability output value shows you the raw probability of a positive return vs. the probability of a negative return. The probability is the value of each line plotted (blue is the probability of a positive return, and purple is the probability of a negative return).
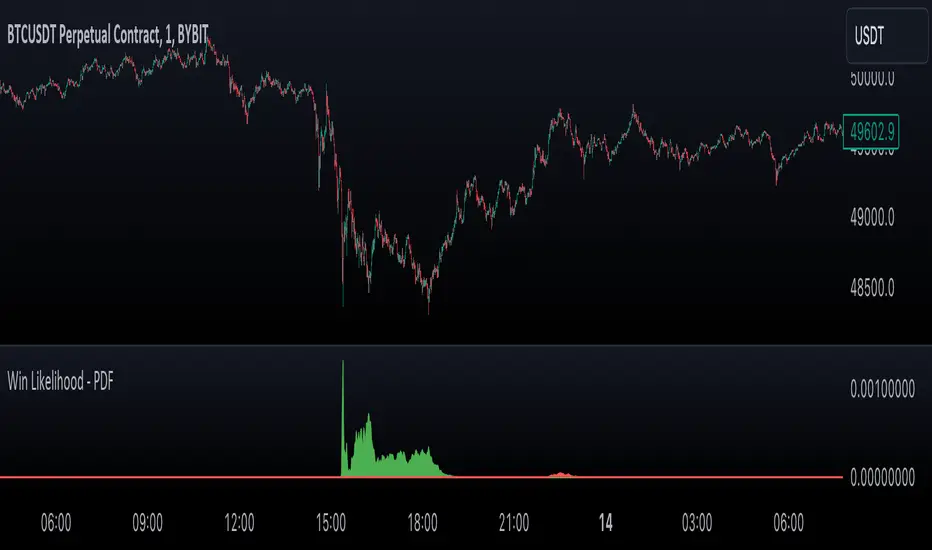
Likelihood of Winning - Probability Density FunctionIn developing the "Likelihood of Winning - Probability Density Function (PDF)" indicator, my aim was to offer traders a statistical tool to quantify the probability of reaching target prices. This indicator, grounded in risk assessment principles, enables users to analyze potential outcomes based on the normal distribution, providing insights into market dynamics.
The tool's flexibility allows for customization of the data series, lookback periods, and target settings for both long and short scenarios. It features a color-coded visualization to easily distinguish between probabilities of hitting specified targets, enhancing decision-making in trading strategies.
I'm excited to share this indicator with the trading community, hoping it will enhance data-driven decision-making and offer a deeper understanding of market risks and opportunities. My goal is to continuously improve this tool based on user feedback and market evolution, contributing to more informed trading practices.
This indicator leverages the "NormalDistributionFunctions" library, enabling easy integration into other indicators or strategies. Users can readily embed advanced statistical analysis into their trading tools, fostering innovation within the Pine Script community.
Breakout Probability Indicator (FinnoVent)The Breakout Probability Indicator is a cutting-edge tool designed for traders looking to gauge the likelihood of price breakouts above or below current levels. This indicator intelligently combines Average True Range (ATR) and recent price action to provide a probabilistic insight into potential future price movements, enhancing strategy formulation and risk management.
Core Features:
Volatility Assessment: Utilizes the Average True Range (ATR) to measure market volatility, a critical component in identifying potential breakout scenarios.
Dynamic Price Levels: Calculates and plots potential breakout levels based on recent highs and lows, adjusted for current market volatility.
Probability Estimation: Provides an estimation of the probability of reaching these breakout levels, using a responsive logarithmic scale for improved sensitivity.
Real-time Updates: Continuously updates probabilities and levels as new price information becomes available, ensuring traders have the most current data at their fingertips.
Usage:
Add this indicator to any chart in TradingView to see the upper and lower breakout levels, each accompanied by a dynamically calculated probability percentage. These probabilities help traders understand the potential for price movement in either direction, forming a basis for entry or exit decisions, stop-loss placement, and strategy adjustments.
Compliance and Guidelines:
This script is shared for educational purposes, offering a novel approach to understanding market dynamics. It does not constitute financial advice and should be used as part of a comprehensive trading strategy. Traders are encouraged to backtest and paper-trade any new tool before live implementation to ensure it aligns with their trading style and risk tolerance.

ATH Drawdown Indicator by Atilla YurtsevenThe ATH (All-Time High) Drawdown Indicator, developed by Atilla Yurtseven, is an essential tool for traders and investors who seek to understand the current price position in relation to historical peaks. This indicator is especially useful in volatile markets like cryptocurrencies and stocks, offering insights into potential buy or sell opportunities based on historical price action.
This indicator is suitable for long-term investors. It shows the average value loss of a price. However, it's important to remember that this indicator only displays statistics based on past price movements. The price of a stock can remain cheap for many years.
1. Utility of the Indicator:
The ATH Drawdown Indicator provides a clear view of how far the current price is from its all-time high. This is particularly beneficial in assessing the magnitude of a pullback or retracement from peak levels. By understanding these levels, traders can gauge market sentiment and make informed decisions about entry and exit points.
2. Risk Management:
This indicator aids in risk management by highlighting significant drawdowns from the ATH. Traders can use this information to adjust their position sizes or set stop-loss orders more effectively. For instance, entering trades when the price is significantly below the ATH could indicate a higher potential for recovery, while a minimal drawdown from the ATH may suggest caution due to potential overvaluation.
3. Indicator Functionality:
The indicator calculates the percentage drawdown from the ATH for each trading period. It can display this data either as a line graph or overlaid on candles, based on user preference. Horizontal lines at -25%, -50%, -75%, and -100% drawdown levels offer quick visual cues for significant price levels. The color-coding of candles further aids in visualizing bullish or bearish trends in the context of ATH drawdowns.
4. ATH Level Indicator (0 Level):
A unique feature of this indicator is the 0 level, which signifies that the price is currently at its all-time high. This level is a critical reference point for understanding the market's peak performance.
5. Mean Line Indicator:
Additionally, this indicator includes a 'Mean Line', representing the average percentage drawdown from the ATH. This average is calculated over more than a thousand past bars, leveraging the law of large numbers to provide a reliable mean value. This mean line is instrumental in understanding the typical market behavior in relation to the ATH.
Disclaimer:
Please note that this ATH Drawdown Indicator by Atilla Yurtseven is provided as an open-source tool for educational purposes only. It should not be construed as investment advice. Users should conduct their own research and consult a financial advisor before making any investment decisions. The creator of this indicator bears no responsibility for any trading losses incurred using this tool.
Please remember to follow and comment!
Trade smart, stay safe
Atilla Yurtseven

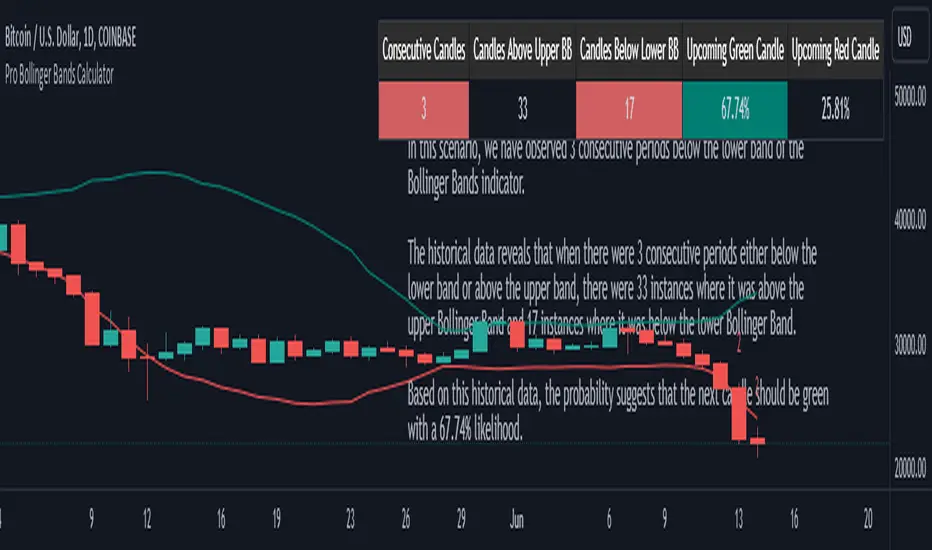
Pro Bollinger Bands CalculatorThe "Pro Bollinger Bands Calculator" indicator joins our suite of custom trading tools, which includes the "Pro Supertrend Calculator", the "Pro RSI Calculator" and the "Pro Momentum Calculator."
Expanding on this series, the "Pro Bollinger Bands Calculator" is tailored to offer traders deeper insights into market dynamics by harnessing the power of the Bollinger Bands indicator.
Its core mission remains unchanged: to scrutinize historical price data and provide informed predictions about future price movements, with a specific focus on detecting potential bullish (green) or bearish (red) candlestick patterns.
1. Bollinger Bands Calculation:
The indicator kicks off by computing the Bollinger Bands, a well-known volatility indicator. It calculates two pivotal Bollinger Bands parameters:
- Bollinger Bands Length: This parameter sets the lookback period for Bollinger Bands calculations.
- Bollinger Bands Deviation: It determines the deviation multiplier for the upper and lower bands, typically set at 2.0.
2. Visualizing Bollinger Bands:
The Bollinger Bands derived from the calculations are skillfully plotted on the price chart:
- Red Line: Represents the upper Bollinger Band during bearish trends, suggesting potential price declines.
- Teal Line: Represents the lower Bollinger Band in bullish market conditions, signaling the possibility of price increases.
3.Analyzing Consecutive Candlesticks:
The indicator's core functionality revolves around tracking consecutive candlestick patterns based on their relationship with the Bollinger Bands lines. To be considered for analysis, a candlestick must consistently close either above (green candles) or below (red candles) the Bollinger Bands lines for multiple consecutive periods.
4. Labeling and Enumeration:
To convey the count of consecutive candles displaying consistent trend behavior, the indicator meticulously assigns labels to the price chart. The position of these labels varies depending on the direction of the trend, appearing either below (for bullish patterns) or above (for bearish patterns) the candlesticks. The label colors match the candle colors: green labels for bullish candles and red labels for bearish ones.
5. Tabular Data Presentation:
The indicator complements its graphical analysis with a customizable table that prominently displays comprehensive statistical insights. Key data points within the table encompass:
- Consecutive Candles: The count of consecutive candles displaying consistent trend characteristics.
- Candles Above Upper BB: The number of candles closing above the upper Bollinger Band during the consecutive period.
- Candles Below Lower BB: The number of candles closing below the lower Bollinger Band during the consecutive period.
- Upcoming Green Candle: An estimated probability of the next candlestick being bullish, derived from historical data.
- Upcoming Red Candle: An estimated probability of the next candlestick being bearish, also based on historical data.
6. Custom Configuration:
To cater to diverse trading strategies and preferences, the indicator offers extensive customization options. Traders can fine-tune parameters such as Bollinger Bands length, upper and lower band deviations, label and table placement, and table size to align with their unique trading approaches.
SimilarityMeasuresLibrary "SimilarityMeasures"
Similarity measures are statistical methods used to quantify the distance between different data sets
or strings. There are various types of similarity measures, including those that compare:
- data points (SSD, Euclidean, Manhattan, Minkowski, Chebyshev, Correlation, Cosine, Camberra, MAE, MSE, Lorentzian, Intersection, Penrose Shape, Meehl),
- strings (Edit(Levenshtein), Lee, Hamming, Jaro),
- probability distributions (Mahalanobis, Fidelity, Bhattacharyya, Hellinger),
- sets (Kumar Hassebrook, Jaccard, Sorensen, Chi Square).
---
These measures are used in various fields such as data analysis, machine learning, and pattern recognition. They
help to compare and analyze similarities and differences between different data sets or strings, which
can be useful for making predictions, classifications, and decisions.
---
References:
en.wikipedia.org
cran.r-project.org
numerics.mathdotnet.com
github.com
github.com
github.com
Encyclopedia of Distances, doi.org
ssd(p, q)
Sum of squared difference for N dimensions.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Measure of distance that calculates the squared euclidean distance.
euclidean(p, q)
Euclidean distance for N dimensions.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Measure of distance that calculates the straight-line (or Euclidean).
manhattan(p, q)
Manhattan distance for N dimensions.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Measure of absolute differences between both points.
minkowski(p, q, p_value)
Minkowsky Distance for N dimensions.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
p_value (float) : `float` P value, default=1.0(1: manhatan, 2: euclidean), does not support chebychev.
Returns: Measure of similarity in the normed vector space.
chebyshev(p, q)
Chebyshev distance for N dimensions.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Measure of maximum absolute difference.
correlation(p, q)
Correlation distance for N dimensions.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Measure of maximum absolute difference.
cosine(p, q)
Cosine distance between provided vectors.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
Returns: The Cosine distance between vectors `p` and `q`.
---
angiogenesis.dkfz.de
camberra(p, q)
Camberra distance for N dimensions.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Weighted measure of absolute differences between both points.
mae(p, q)
Mean absolute error is a normalized version of the sum of absolute difference (manhattan).
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Mean absolute error of vectors `p` and `q`.
mse(p, q)
Mean squared error is a normalized version of the sum of squared difference.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Mean squared error of vectors `p` and `q`.
lorentzian(p, q)
Lorentzian distance between provided vectors.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Lorentzian distance of vectors `p` and `q`.
---
angiogenesis.dkfz.de
intersection(p, q)
Intersection distance between provided vectors.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Intersection distance of vectors `p` and `q`.
---
angiogenesis.dkfz.de
penrose(p, q)
Penrose Shape distance between provided vectors.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Penrose shape distance of vectors `p` and `q`.
---
angiogenesis.dkfz.de
meehl(p, q)
Meehl distance between provided vectors.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Meehl distance of vectors `p` and `q`.
---
angiogenesis.dkfz.de
edit(x, y)
Edit (aka Levenshtein) distance for indexed strings.
Parameters:
x (int ) : `array` Indexed array.
y (int ) : `array` Indexed array.
Returns: Number of deletions, insertions, or substitutions required to transform source string into target string.
---
generated description:
The Edit distance is a measure of similarity used to compare two strings. It is defined as the minimum number of
operations (insertions, deletions, or substitutions) required to transform one string into another. The operations
are performed on the characters of the strings, and the cost of each operation depends on the specific algorithm
used.
The Edit distance is widely used in various applications such as spell checking, text similarity, and machine
translation. It can also be used for other purposes like finding the closest match between two strings or
identifying the common prefixes or suffixes between them.
---
github.com
www.red-gate.com
planetcalc.com
lee(x, y, dsize)
Distance between two indexed strings of equal length.
Parameters:
x (int ) : `array` Indexed array.
y (int ) : `array` Indexed array.
dsize (int) : `int` Dictionary size.
Returns: Distance between two strings by accounting for dictionary size.
---
www.johndcook.com
hamming(x, y)
Distance between two indexed strings of equal length.
Parameters:
x (int ) : `array` Indexed array.
y (int ) : `array` Indexed array.
Returns: Length of different components on both sequences.
---
en.wikipedia.org
jaro(x, y)
Distance between two indexed strings.
Parameters:
x (int ) : `array` Indexed array.
y (int ) : `array` Indexed array.
Returns: Measure of two strings' similarity: the higher the value, the more similar the strings are.
The score is normalized such that `0` equates to no similarities and `1` is an exact match.
---
rosettacode.org
mahalanobis(p, q, VI)
Mahalanobis distance between two vectors with population inverse covariance matrix.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
VI (matrix) : `matrix` Inverse of the covariance matrix.
Returns: The mahalanobis distance between vectors `p` and `q`.
---
people.revoledu.com
stat.ethz.ch
docs.scipy.org
fidelity(p, q)
Fidelity distance between provided vectors.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
Returns: The Bhattacharyya Coefficient between vectors `p` and `q`.
---
en.wikipedia.org
bhattacharyya(p, q)
Bhattacharyya distance between provided vectors.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
Returns: The Bhattacharyya distance between vectors `p` and `q`.
---
en.wikipedia.org
hellinger(p, q)
Hellinger distance between provided vectors.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
Returns: The hellinger distance between vectors `p` and `q`.
---
en.wikipedia.org
jamesmccaffrey.wordpress.com
kumar_hassebrook(p, q)
Kumar Hassebrook distance between provided vectors.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
Returns: The Kumar Hassebrook distance between vectors `p` and `q`.
---
github.com
jaccard(p, q)
Jaccard distance between provided vectors.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
Returns: The Jaccard distance between vectors `p` and `q`.
---
github.com
sorensen(p, q)
Sorensen distance between provided vectors.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
Returns: The Sorensen distance between vectors `p` and `q`.
---
people.revoledu.com
chi_square(p, q, eps)
Chi Square distance between provided vectors.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
eps (float)
Returns: The Chi Square distance between vectors `p` and `q`.
---
uw.pressbooks.pub
stats.stackexchange.com
www.itl.nist.gov
kulczynsky(p, q, eps)
Kulczynsky distance between provided vectors.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
eps (float)
Returns: The Kulczynsky distance between vectors `p` and `q`.
---
github.com

FunctionMatrixCovarianceLibrary "FunctionMatrixCovariance"
In probability theory and statistics, a covariance matrix (also known as auto-covariance matrix, dispersion matrix, variance matrix, or variance–covariance matrix) is a square matrix giving the covariance between each pair of elements of a given random vector.
Intuitively, the covariance matrix generalizes the notion of variance to multiple dimensions. As an example, the variation in a collection of random points in two-dimensional space cannot be characterized fully by a single number, nor would the variances in the `x` and `y` directions contain all of the necessary information; a `2 × 2` matrix would be necessary to fully characterize the two-dimensional variation.
Any covariance matrix is symmetric and positive semi-definite and its main diagonal contains variances (i.e., the covariance of each element with itself).
The covariance matrix of a random vector `X` is typically denoted by `Kxx`, `Σ` or `S`.
~wikipedia.
method cov(M, bias)
Estimate Covariance matrix with provided data.
Namespace types: matrix
Parameters:
M (matrix) : `matrix` Matrix with vectors in column order.
bias (bool)
Returns: Covariance matrix of provided vectors.
---
en.wikipedia.org
numpy.org
Candles In Row (Expo)█ Overview
The Candles In Row (Expo) indicator is a powerful tool designed to track and visualize sequences of consecutive candlesticks in a price chart. Whether you're looking to gauge momentum or determine the prevailing trend, this indicator offers versatile functionality tailored to the needs of active traders. The Candles In Row indicator can be an integral part of a multi-timeframe trading strategy, allowing traders to understand market momentum, and set trading bias. By recognizing the patterns and likelihood of future price movements, traders can make more informed decisions and align their trades with the overall market direction.
█ How to use
The indicator enhances traders' understanding of the consecutive candle patterns, helping them to uncover trends and momentum. Consecutive candles in the same direction may indicate a strong trend. The Candles In Row indicator can be an essential tool for traders employing a multiple timeframes strategy.
Analyzing a Higher Timeframe:
Understanding Momentum: By analyzing consecutive green or red candles in a higher timeframe, traders can identify the prevailing momentum in the market. A series of green candles would suggest an upward trend, while a series of red candles would indicate a downward trend.
Predicting Next Candle: The indicator's predictive feature calculates the likelihood of the next candle being green or red based on historical patterns. This probability helps traders gauge the potential continuation of the trend.
Setting the Trading Bias: If the likelihood of the next candle being green is high, the trader may decide to focus on long (buy) opportunities. Conversely, if the likelihood of the next candle being red is high, the trader may look for short (sell) opportunities.
In this example, we are using the Heikin Ashi candles.
Moving to a Lower Timeframe:
Finding Entry Points: Once the trading bias is set based on the higher timeframe analysis, traders can switch to a lower timeframe to look for entry points in the direction of the bias. For example, if the higher timeframe suggests a high likelihood of a green candle, traders may look for buy opportunities in the lower timeframe.
Combining Timeframes for a Comprehensive Strategy:
Confirmation and Alignment: By analyzing the higher timeframe and confirming the direction in the lower timeframe, traders can ensure that they are trading in alignment with the broader trend.
Avoiding False Signals: By using a higher timeframe to set the trading bias and a lower timeframe to find entries, traders can avoid false signals and whipsaws that might be present in a single timeframe analysis.
█ Settings
Price Input Selection: Choose between regular open and close prices or Heikin Ashi candles as the basis for calculation.
Data Window Control: Decide between displaying the full data window or only the active data. You can also enable a counter that keeps track of the number of candles.
Alert Configuration: Set the desired number and color of consecutive candles that must occur in a row to trigger an alert.
Table Display Customization: Customize the location and size of the display table according to your preferences.
-----------------
Disclaimer
The information contained in my Scripts/Indicators/Ideas/Algos/Systems does not constitute financial advice or a solicitation to buy or sell any securities of any type. I will not accept liability for any loss or damage, including without limitation any loss of profit, which may arise directly or indirectly from the use of or reliance on such information.
All investments involve risk, and the past performance of a security, industry, sector, market, financial product, trading strategy, backtest, or individual's trading does not guarantee future results or returns. Investors are fully responsible for any investment decisions they make. Such decisions should be based solely on an evaluation of their financial circumstances, investment objectives, risk tolerance, and liquidity needs.
My Scripts/Indicators/Ideas/Algos/Systems are only for educational purposes!

Normal Distribution CurveThis Normal Distribution Curve is designed to overlay a simple normal distribution curve on top of any TradingView indicator. This curve represents a probability distribution for a given dataset and can be used to gain insights into the likelihood of various data levels occurring within a specified range, providing traders and investors with a clear visualization of the distribution of values within a specific dataset. With the only inputs being the variable source and plot colour, I think this is by far the simplest and most intuitive iteration of any statistical analysis based indicator I've seen here!
Traders can quickly assess how data clusters around the mean in a bell curve and easily see the percentile frequency of the data; or perhaps with both and upper and lower peaks identify likely periods of upcoming volatility or mean reversion. Facilitating the identification of outliers was my main purpose when creating this tool, I believed fixed values for upper/lower bounds within most indicators are too static and do not dynamically fit the vastly different movements of all assets and timeframes - and being able to easily understand the spread of information simplifies the process of identifying key regions to take action.
The curve's tails, representing the extreme percentiles, can help identify outliers and potential areas of price reversal or trend acceleration. For example using the RSI which typically has static levels of 70 and 30, which will be breached considerably more on a less liquid or more volatile asset and therefore reduce the actionable effectiveness of the indicator, likewise for an asset with little to no directional volatility failing to ever reach this overbought/oversold areas. It makes considerably more sense to look for the top/bottom 5% or 10% levels of outlying data which are automatically calculated with this indicator, and may be a noticeable distance from the 70 and 30 values, as regions to be observing for your investing.
This normal distribution curve employs percentile linear interpolation to calculate the distribution. This interpolation technique considers the nearest data points and calculates the price values between them. This process ensures a smooth curve that accurately represents the probability distribution, even for percentiles not directly present in the original dataset; and applicable to any asset regardless of timeframe. The lookback period is set to a value of 5000 which should ensure ample data is taken into calculation and consideration without surpassing any TradingView constraints and limitations, for datasets smaller than this the indicator will adjust the length to just include all data. The labels providing the percentile and average levels can also be removed in the style tab if preferred.
Additionally, as an unplanned benefit is its applicability to the underlying price data as well as any derived indicators. Turning it into something comparable to a volume profile indicator but based on the time an assets price was within a specific range as opposed to the volume. This can therefore be used as a tool for identifying potential support and resistance zones, as well as areas that mark market inefficiencies as price rapidly accelerated through. This may then give a cleaner outlook as it eliminates the potential drawbacks of volume based profiles that maybe don't collate all exchange data or are misrepresented due to large unforeseen increases/decreases underlying capital inflows/outflows.
Thanks to @ALifeToMake, @Bjorgum, vgladkov on stackoverflow (and possibly some chatGPT!) for all the assistance in bringing this indicator to life. I really hope every user can find some use from this and help bring a unique and data driven perspective to their decision making. And make sure to please share any original implementaions of this tool too! If you've managed to apply this to the average price change once you've entered your position to better manage your trade management, or maybe overlaying on an implied volatility indicator to identify potential options arbitrage opportunities; let me know! And of course if anyone has any issues, questions, queries or requests please feel free to reach out! Thanks and enjoy.

Probability Trend IndicatorUnderstanding the Indicator:
The indicator calculates the probabilities of upward and downward trends based on the percentage change in price over a specified lookback period.
It displays these probabilities in a table and plots a histogram to represent the difference between the probabilities.
The colors of the histogram bars indicate the trend direction and whether the trend is increasing or decreasing.
Setting the Lookback Period:
The indicator allows you to specify the lookback period, which determines the number of bars to consider for calculating the probabilities.
By default, the lookback period is set to 50 bars. However, you can adjust it based on your trading preferences and the timeframe you're analyzing.
Analyzing the Probabilities:
The indicator calculates the probabilities of upward and downward trends and displays them in a table on the chart.
The probabilities are presented as percentages, representing the likelihood of each type of trend occurring.
You can use these probabilities to gain insights into the potential market direction and assess the strength of the prevailing trend.
Interpreting the Histogram:
The histogram is plotted based on the difference between the probabilities of upward and downward trends, known as the oscillator value.
The histogram bars are colored to provide visual cues about the trend direction and whether the trend is gaining or losing strength.
Green bars indicate upward trends, and red bars indicate downward trends.
Lighter shades of green or red suggest increasing trends, while darker shades suggest decreasing trends.
Making Trading Decisions:
The indicator serves as a tool for assessing the probabilities of trends and can be used alongside other technical analysis methods.
You can consider the probabilities, the histogram pattern, and the overall market context to make informed trading decisions.
It's important to remember that no indicator or tool can guarantee future market movements, so prudent risk management and additional analysis are essential.
