Support and Resistance Polynomial Regressions | Flux ChartsOverview
This script is a dynamic form of support and resistance. Support and resistance plots areas where price commonly reverses its direction or “pivots”. A resistance line for instance is typically found by locating a price point where multiple high pivots occur. A high pivot is where a price increases for a number of bars then decreases for a number of bars creating a local maximum. This script takes the high pivots points but rather than using a horizontal line a polynomial regressed line is used.
It is common to see consecutive higher highs or lower lows or a mixed pattern of both so a classical support or resistance line can be insufficient. This script lets users find a polynomial of best fit for high pivots and low pivots creating a resistance and support line respectively.
Here are the same two sets of high and low pivots the first using linear regressed support and resistance lines the second using quadratic.
Here are the predicted results:
The Quadratic regression gives a much more accurate prediction of future pivot areas and the increase in variance of the data.
Quick Start
Add the script to the chart. Then select a left point and right point on the chart. This will be the data the script uses to calculate a best fit resistance line. Then select another left and right point that will be for the support line.
Now you can confirm your basic settings like the type of regression: Linear Regression, Quadratic Regression, Cubic Regression or Custom Regression.
After confirming the lines will be plotted on the graph.
Custom Polynomial Regression Setting
Polynomials follow the form:
The degree of a polynomial is the highest exponent in the equation. For example the polynomial ax^2 + bx + c has a degree of 2.
Here are the default polynomial options and their equivalent custom polynomial entry:
This allows us to create regressions with a custom number of inflection points. An inflection point is a point where the graph changes from concave up to concave down or vice versa. The maximum number of inflection points a polynomial can have is the degree - 2. Having multiple inflection points in our regression allows for having a closer fit minimizing error.
It should be noted that having a closer fit is not inherently better; this can cause overfitting. Overfitting is when a model is too closely fit to the training data and not generalizable to the population data.
Regressions

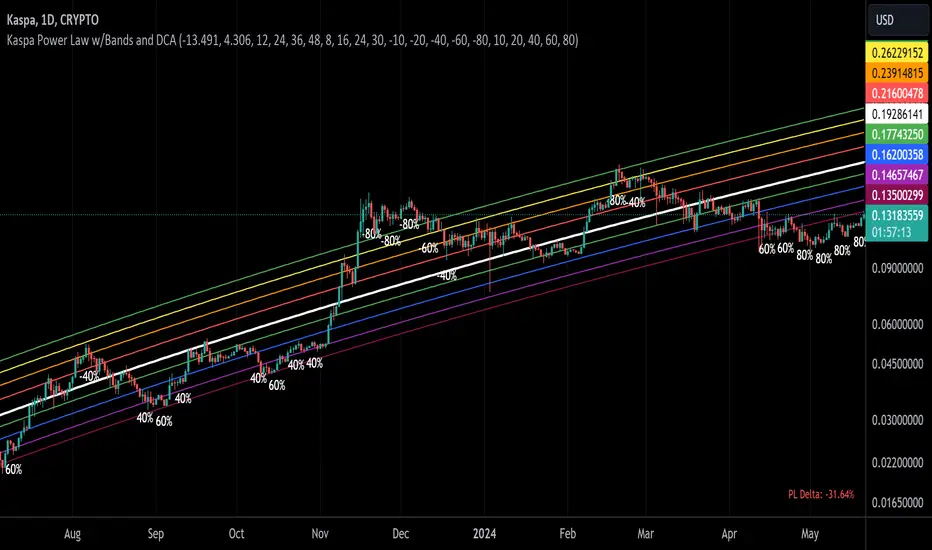
Kaspa Power LawSimple Power Law Indicator for Kaspa with addition of adjustable bands above and below the Power Law Price. Best used on Logarithmic view on Daily Time Frame.
Monte Carlo Shuffled Projection [LuxAlgo]The Monte Carlo Shuffled Projection tool randomly simulates future price points based on historical bar movements made within a user-selected window.
The tool shows potential paths price might take in the future, as well as highlighting potential support/resistance levels.
Note that simulations and their resulting elements are subject to slight changes over time.
🔶 USAGE
By randomly simulating bar movements, a range is developed of potential price action which could be utilized to locate future price development as well as potential support/resistance levels.
Performing a large number of simulations and taking the average at each step will converge toward the result highlighted by the "Average Line", and can point out where the price might develop assuming the trend and amount of volatility persist.
Current closing price + Sum of changes in the calculation window)
This constraint will cause the simulations to always display an endpoint consistent with the current lookback's slope.
While this may be helpful to some traders, this indicator includes an option to produce a less biased range as seen below:
🔶 DETAILS
The Monte Carlo Shuffled Projection tool creates simulations based on the most recent prices within a user-set window. Simulations are done as follows:
Collect each bar's price changes in the user-set window.
Randomize the order of each change in the window.
Project the cumulative sum of the shuffled changes from the current closing price.
Collect data on each point along the way.
This is the process for the Default calculation, for the 'Randomize Direction' calculation, when added onto the front for every other change, the value is inverted, creating the randomized endpoints for each simulation.
The script contains each simulation's data for that bar with a maximum of 1000 simulations.
To get a glimpse behind the scenes each simulation (up to 99) can be viewed using the 'Visualize Simulations' Options as seen below.
Because the script holds the full simulation data, the script can also do calculations on this data, such as calculating standard deviations.
In this script the Standard deviation lines are the average of all standard deviations across the vertical data groups, this provides a singular value that can be displayed a distance away from the simulation center line.
🔶 SETTINGS
Color and Toggle Options are Provided throughout.
Lookback: Sets the number of Bars to include in calculations.
Simulation Count: Sets the number of randomized simulations to calculate. (Max 1000)
Randomize Direction: See Details Above. Creates a more 'Normalized' Distribution
Visualize Simulations: See Details Above. Turns on Visualizations, and colors are randomly generated. Visualized max does not cap the calculated max. If 1000 simulations are used, the data will be from 1000 simulations, however only the last 99 simulations will be visualized.
Standard Deviation Multiplier: Sets the multiplier to use for the Standard Deviation distance away from the center line.

Long-Term Trend DetectorThe Long-Term Trend Detector is a powerful tool designed to identify sustainable trends in price movements, offering significant advantages for traders and investors.
Key Benefits:
1. Projection Confidence: This indicator leverages Pearson's R, a statistical measure that indicates the strength of the linear relationship between price and trend projection. A higher Pearson's R value reflects a stronger correlation, providing increased confidence in the identified trend direction.
2. Adaptive Channel Detection: By calculating deviations and correlations over varying lengths, the indicator dynamically adapts to changing market conditions. This adaptive nature ensures robust trend detection across different time frames.
3. Visual Clarity: The indicator visually displays long-term trend channels on the chart, offering clear insights into potential price trajectories. This visualization aids in decision-making by highlighting periods of strong trend potential.
4. Flexibility and Customization: Users can customize parameters such as deviation multiplier, line styles, transparency levels, and display preferences. This flexibility allows traders to tailor the indicator to their specific trading strategies and preferences.
5. Historical Analysis: The indicator can analyze extensive historical data (up to 5000 bars back) to provide comprehensive trend insights. This historical perspective enables users to assess trends over extended periods, enhancing strategic decision-making.
In summary, the Long-Term Trend Detector empowers traders with accurate trend projections and confidence levels, facilitating informed trading decisions. Its adaptive nature and customizable features make it a valuable tool for identifying and capitalizing on long-term market trends.

Sector ETFs performance overviewThe indicator provides a nuanced view of sector performance through ETF analysis, focusing on long-term price trends and deviations from these trends to gauge relative strength or weakness. It utilizes a methodical approach to smooth out ETF price data and then applies a regression analysis to pinpoint the primary trend direction. By examining how far the current price deviates from this regression line, the indicator identifies potential overbought or oversold conditions within various sectors.
Core Analysis Techniques:
Logarithmic Transformation and Regression: This process transforms ETF closing prices on a logarithmic scale to better understand sector growth patterns and dynamics. A linear regression of these prices helps define the overarching trend, crucial for understanding market movements.
Volatility Bands for Market State Assessment: The indicator calculates standard deviation based on logarithmic prices to establish dynamic bands around the regression line. These bands are instrumental in identifying market states, highlighting when sectors may be overextended from their central trend.
Sector-Specific Analysis: By focusing on distinct sector ETFs, the tool enables targeted analysis across various market segments. This specificity allows for a granular look at sectors like technology, healthcare, and financials, providing insights tailored to each area.
Adaptability and Insight:
Customizable Parameters: The indicator offers users the ability to adjust key parameters such as regression length and smoothing factors. This customization ensures that the analysis can be tailored to individual preferences and market outlooks.
Trend Direction and Momentum: It assesses the ETF's price movement relative to historical data and the established volatility bands, helping to clarify the sector's trend strength and potential directional shifts.
Strategic Application:
Focusing on trend and volatility analysis rather than direct trading signals, the indicator aids in forming a strategic view of sector investments. It's particularly useful for:
Spotting macroeconomic trends through the lens of sector ETF performance.
Informing portfolio decisions with nuanced insights into sector momentum and market conditions.
Anticipating potential market shifts by evaluating how current prices align with historical volatility and trend patterns.
This tool stands out as a vital resource for analyzing sector-level market trends, offering detailed insights into the dynamics of economic sectors for comprehensive market analysis.

Sector ETF macro trendThe Sector ETF Macro Trend indicator is designed for technical analysis of broad economic trends through sector-specific exchange-traded funds (ETFs). It uses logarithmic price transformation, linear regression, and volatility analysis to examine sector trends and stability, providing a technical basis for analytical assessment.
Core Analysis Techniques
Logarithmic Transformation and Regression: Converts ETF closing prices logarithmically to reveal sector growth patterns and dynamics. Linear regression on these prices defines the main trend direction, essential for trend analysis.
Volatility Bands for Market State Assessment: Applies standard deviation on logarithmic prices to create dynamic bands around the trendline, identifying overbought or oversold sector conditions by marking deviations from the central trend.
Sector-Specific Analysis: Selection among different sector ETFs allows for precise examination of sectors like technology, healthcare, and financials, enabling focused insights into specific market segments.
Adaptability and Insight
Customizable Parameters: Offers flexibility in modifying regression length and smoothing factors to accommodate various analysis strategies and risk preferences.
Trend Direction and Momentum: Evaluates the ETF's trajectory against historical data and volatility bands to determine sector trend strength and direction, aiding in the prediction of market shifts.
Strategic Application
Without providing explicit trading signals, the indicator focuses on trend and volatility analysis for a strategic view on sector investments. It supports:
Identifying macroeconomic trends through ETF performance analysis.
Informing portfolio decisions with insights into sector momentum and stability.
Forecasting market movements by analyzing overbought or oversold conditions against the ETF price movement and volatility bands.
The Sector ETF Macro Trend indicator serves as a technical tool for analyzing sector-level market trends, offering detailed insights into the dynamics of economic sectors for thorough market analysis.

Custom Swing Index [AstroHub]Custom Swing Index - Unleashing Precision in Trend Analysis
🌟 Overview:
The Custom Swing Index is a meticulously crafted tool that empowers traders with advanced insights into market dynamics, specifically focusing on identifying potential trend reversals. Developed by AstroHub, this indicator stands out for its unique combination of price-related calculations, ratios, and averages, providing a comprehensive and nuanced view of market sentiment.
📈 Key Components:
Price Calculation:
- Price Change: Captures the difference between the current and previous closing prices.
- High and Low Points: Analyzes the high and low points of each bar for crucial price movement data.
Ratios and Averages:
- Upper-Lower Shadow Ratio: Measures the relationship between the upper and lower shadows.
- Open-Close Ratio: Evaluates the ratio of opening to closing prices.
- Sum Price Changes: Sums up price changes over a specified period.
Differences and Shadows:
- Open-Close Difference: Considers the difference between opening and closing prices.
- Upper and Lower Shadow Ratios: Examines the proportions of upper and lower shadows.
Bar Size Metrics:
- Average Bar Size: Determines the average size of each bar.
- High-Low Difference: Measures the difference between the high and low points.
Swing Indicator Calculation:
- The Custom Swing Index is the result of combining these components, creating a dynamic metric that reflects potential trend reversals.
🚥 How to Use:
Understanding the Indicator:
- Bullish signals may be indicated when the swing index surpasses a defined threshold.
- Bearish signals may be indicated when the swing index falls below the negative threshold.
Visual Interpretation:
- Color-coded bars enhance visual interpretation, turning green for bullish conditions and red for bearish conditions.
Entry Points:
- Look for entry points where circle markings are present, indicating potential opportunities.
Alerts:
- Integrated alerts keep traders informed of significant swings, ensuring timely decision-making.
[S] Rolling TrendlineThe Rolling Linear Regression Trendline is a sophisticated technical analysis tool designed to offer traders a dynamic view of market trends over a selectable period. This indicator employs linear regression to calculate and plot a trendline that best fits the closing prices within a specified window, either defined by a number of bars or a set period in days, independent of the chart's timeframe.
Key Features:
Dynamic Window Selection: Users can choose the calculation window based on a fixed number of bars or days, providing flexibility to adapt to different trading strategies and timeframes. For the 'days' option, the indicator calculates the equivalent number of bars based on the chart's timeframe, ensuring relevance across various market conditions and trading sessions.
Linear Regression Analysis: At its core, the indicator uses linear regression to identify the trend direction by calculating the slope and intercept of the trendline. This method offers a statistical approach to trend analysis, highlighting potential uptrends or downtrends based on the positioning and direction of the trendline.
Customizable Period: Traders can input their desired period (N), allowing for tailored analysis. Whether it's short-term movements or longer-term trends, the indicator can adjust to focus on specific time horizons, enhancing its utility across different trading styles and objectives.
Applications:
Trend Identification: By plotting a trendline that mathematically fits the closing prices over the chosen period, traders can quickly identify the prevailing market trend, aiding in bullish or bearish decision-making.
Support and Resistance: The trendline can also serve as a dynamic level of support or resistance, offering potential entry or exit points based on the price's interaction with the trendline.
Strategic Planning: With the ability to adjust the calculation window, traders can align the indicator with their trading strategy, whether focusing on intraday movements or broader swings.
Using this indicator with other parameters can widen you view of the market and help identifying trends

Least Median of Squares Regression | ymxbThe Least Median of Squares (LMedS) is a robust statistical method predominantly used in the context of regression analysis. This technique is designed to fit a model to a dataset in a way that is resistant to outliers. Developed as an alternative to more traditional methods like Ordinary Least Squares (OLS) regression, LMedS is distinguished by its focus on minimizing the median of the squares of the residuals rather than their mean. Residuals are the differences between observed and predicted values.
The key advantage of LMedS is its robustness against outliers. In contrast to methods that minimize the mean squared residuals, the median is less influenced by extreme values, making LMedS more reliable in datasets where outliers are present. This is particularly useful in linear regression, where it identifies the line that minimizes the median of the squared residuals, ensuring that the line is not overly influenced by anomalies.
STATISTICAL PROPERTIES
A critical feature of the LMedS method is its robustness, particularly its resilience to outliers. The method boasts a high breakdown point, which is a measure of an estimator's capacity to handle outliers. In the context of LMedS, this breakdown point is approximately 50%, indicating that it can tolerate corruption of up to half of the input data points without a significant degradation in accuracy. This robustness makes LMedS particularly valuable in real-world data analysis scenarios, where outliers are common and can severely skew the results of less robust methods.
Rousseeuw, Peter J.. “Least Median of Squares Regression.” Journal of the American Statistical Association 79 (1984): 871-880.
The LMedS estimator is also characterized by its equivariance under linear transformations of the response variable. This means that whether you transform the data first and then apply LMedS, or apply LMedS first and then transform the data, the end result remains consistent. However, it's important to note that LMedS is not equivariant under affine transformations of both the predictor and response variables.
ALGORITHM
The algorithm randomly selects pairs of points, calculates the slope (m) and intercept (b) of the line, and then evaluates the median squared deviation (mr2) from this line. The line minimizing this median squared deviation is considered the best fit.
DISCLAIMER
In the LMedS approach, a subset of the data is randomly selected to compute potential models (e.g., lines in linear regression). The method then evaluates these models based on the median of the squared residuals. Since the selection of data points is random, different runs may select different subsets, leading to variability in the computed models.

F.B_Vortex Indicator ProThe "F.B_Vortex Indicator Pro" is a technical analysis tool designed to identify trends in financial markets. It calculates two Vortex Indicators (VI) based on price movements, considering positive and negative price changes.
The smoothed VI+ line represents the smoothed negative trend, while the smoothed VI+ line represents the smoothed positive trend.
The crossing of the smoothed VI+ line above the smoothed VI+ line could indicate a potential bullish trend.
Conversely, the crossing of the smoothed VI+ line above the smoothed VI+ line suggests a possible bearish trend.
The "Smoothed VI-" line is also displayed.
When the Smoothed VI- line is above both the smoothed VI+ line and the smoothed VI+ line, it may signal a transition to a bearish main trend or indicate an expected one.
When the Smoothed VI- line is below both the smoothed VI+ line and the smoothed VI+ line, it may indicate a transition to a bullish main trend or suggest an expected one.
Adjustments can be made using input parameters such as length and smoothing periods to tailor the indicator to specific market conditions.
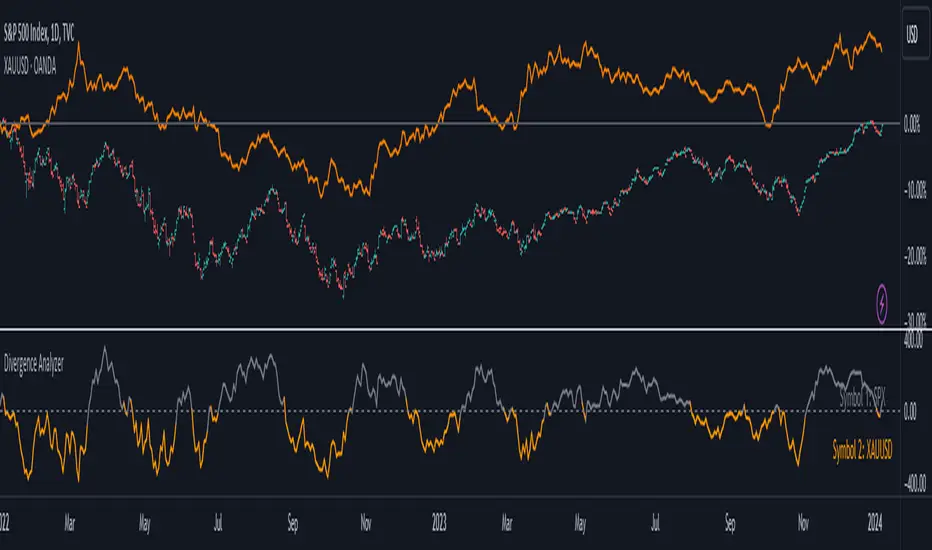
Divergence AnalyzerUnlock the potential of your trading strategy with the Divergence Analyzer, a sophisticated indicator designed to identify divergence patterns between two financial instruments. Whether you're a seasoned trader or just starting, this tool provides valuable insights into market trends and potential trading opportunities.
Key Features:
1. Versatility in Symbol Selection:
- Choose from a wide range of symbols for comparison, including popular indices like XAUUSD and SPX.
- Seamlessly toggle between symbols to analyze divergences and make informed trading decisions.
2. Flexible Calculation Options:
- Customizable options allow you to use a different symbol for calculation instead of the chart symbol.
- Fine-tune your analysis by selecting specific symbols for comparison based on your trading preferences.
3. Logarithmic Scale Analysis:
- Utilizes logarithmic scales for accurate representation of price movements.
- Linear regression coefficients are calculated on the logarithmic scale, providing a comprehensive view of trend strength.
4. Dynamic Length and Smoothing:
- Adjust the length parameter to adapt the indicator to different market conditions.
- Smoothed linear regression with exponential moving averages enhances clarity and reduces noise.
5. Standard Deviation Normalization:
- Normalizes standard deviations over 200 periods, offering a standardized view of price volatility.
- Easily compare volatility levels across different symbols for effective divergence analysis.
6. Color-Coded Divergence Visualization:
- Clearly distinguish positive and negative divergences with customizable color options.
- Visualize divergence deltas with an intuitive color scheme for quick and effective interpretation.
7. Symbol Information Table:
- An included table provides at-a-glance information about the selected symbols.
- Identify Symbol 1 and Symbol 2, along with their corresponding positive and negative divergence colors.
How to Use:
1. Select symbols for analysis using the user-friendly inputs.
2. Customize calculation options based on your preferences.
3. Analyze the divergence delta plot for clear visual indications.
4. Refer to the symbol information table for a quick overview of selected instruments.
Empower your trading strategy with the Divergence Analyzer and gain a competitive edge in the dynamic world of financial markets. Start making more informed decisions today!
Adaptive Trend Finder (log)In the dynamic landscape of financial markets, the Adaptive Trend Finder (log) stands out as an example of precision and professionalism. This advanced tool, equipped with a unique feature, offers traders a sophisticated approach to market trend analysis: the choice between automatic detection of the long-term or short-term trend channel.
Key Features:
1. Choice Between Long-Term or Short-Term Trend Channel Detection: Positioned first, this distinctive feature of the Adaptive Trend Finder (log) allows traders to customize their analysis by choosing between the automatic detection of the long-term or short-term trend channel. This increased flexibility adapts to individual trading preferences and changing market conditions.
2. Autonomous Trend Channel Detection: Leveraging the robust statistical measure of the Pearson coefficient, the Adaptive Trend Finder (log) excels in autonomously locating the optimal trend channel. This data-driven approach ensures objective trend analysis, reducing subjective biases, and enhancing overall precision.
3. Precision of Logarithmic Scale: A distinctive characteristic of our indicator is its strategic use of the logarithmic scale for regression channels. This approach enables nuanced analysis of linear regression channels, capturing the subtleties of trends while accommodating variations in the amplitude of price movements.
4. Length and Strength Visualization: Traders gain a comprehensive view of the selected trend channel, with the revelation of its length and quantification of trend strength. These dual pieces of information empower traders to make informed decisions, providing insights into both the direction and intensity of the prevailing trend.
In the demanding universe of financial markets, the Adaptive Trend Finder (log) asserts itself as an essential tool for traders, offering an unparalleled combination of precision, professionalism, and customization. Highlighting the choice between automatic detection of the long-term or short-term trend channel in the first position, this indicator uniquely caters to the specific needs of each trader, ensuring informed decision-making in an ever-evolving financial environment.

Triple Confirmation Kernel Regression Overlay [QuantraSystems]Kernel Regression Oscillator - Overlay
Introduction
The Kernel Regression Oscillator (ᏦᏒᎧ) represents an advanced tool for traders looking to capitalize on market trends.
This Indicator is valuable in identifying and confirming trend directions, as well as probabilistic and dynamic oversold and overbought zones.
It achieves this through a unique composite approach using three distinct Kernel Regressions combined in an Oscillator.
The additional Chart Overlay Indicator adds confidence to the signal.
Which is this Indicator.
This methodology helps the trader to significantly reduce false signals and offers a more reliable indication of market movements than more widely used indicators can.
Legend
The upper section is the Overlay. It features the Signal Wave to display the current trend.
Its Overbought and Oversold zones start at 50% and end at 100% of the selected Standard Deviation (default σ = 3), which can indicate extremely rare situations which can lead to either a softening momentum in the trend or even a mean reversion situation.
The lower one is the Base Chart.
The Indicator is linked here
It features the Kernel Regression Oscillator to display a composite of three distinct regressions, also displaying current trend.
Its Overbought and Oversold zones start at 50% and end at 100% of the selected Standard Deviation (default σ = 2), which can indicate extremely rare situations.
Case Study
To effectively utilize the ᏦᏒᎧ, traders should use both the additional Overlay and the Base
Chart at the same time. Then focus on capturing the confluence in signals, for example:
If the 𝓢𝓲𝓰𝓷𝓪𝓵 𝓦𝓪𝓿𝓮 on the Overlay and the ᏦᏒᎧ on the Base Chart both reside near the extreme of an Oversold zone the probability is higher than normal that momentum in trend may soften or the token may even experience a reversion soon.
If a bar is characterized by an Oversold Shading in both the Overlay and the Base Chart, then the probability is very high to experience a reversion soon.
In this case the trader may want to look for appropriate entries into a long position, as displayed here.
If a bar is characterized by an Overbought Shading in either Overlay or Base Chart, then the probability is high for momentum weakening or a mean reversion.
In this case the trade may have taken profit and closed his long position, as displayed here.
Please note that we always advise to find more confluence by additional indicators.
Recommended Settings
Swing Trading (1D chart)
Overlay
Bandwith: 45
Width: 2
SD Lookback: 150
SD Multiplier: 2
Base Chart
Bandwith: 45
SD Lookback: 150
SD Multiplier: 2
Fast-paced, Scalping (4min chart)
Overlay
Bandwith: 75
Width: 2
SD Lookback: 150
SD Multiplier: 3
Base Chart
Bandwith: 45
SD Lookback: 150
SD Multiplier: 2
Notes
The Kernel Regression Oscillator on the Base Chart is also sensitive to divergences if that is something you are keen on using.
For maximum confluence, it is recommended to use the indicator both as a chart overlay and in its Base Chart.
Please pay attention to shaded areas with Standard Deviation settings of 2 or 3 at their outer borders, and consider action only with high confidence when both parts of the indicator align on the same signal.
This tool shows its best performance on timeframes lower than 4 hours.
Traders are encouraged to test and determine the most suitable settings for their specific trading strategies and timeframes.
The trend following functionality is indicated through the "𝓢𝓲𝓰𝓷𝓪𝓵 𝓦𝓪𝓿𝓮" Line, with optional "Up" and "Down" arrows to denote trend directions only (toggle “Show Trend Signals”).
Methodology
The Kernel Regression Oscillator takes three distinct kernel regression functions,
used at similar weight, in order to calculate a balanced and smooth composite of the regressions. Part of it are:
The Epanechnikov Kernel Regression: Known for its efficiency in smoothing data by assigning less weight to data points further away from the target point than closer data points, effectively reducing variance.
The Wave Kernel Regression: Similarly assigning weight to the data points based on distance, it captures repetitive and thus wave-like patterns within the data to smoothen out and reduce the effect of underlying cyclical trends.
The Logistic Kernel Regression: This uses the logistic function in order to assign weights by probability distribution on the distance between data points and target points. It thus avoids both bias and variance to a certain level.
kernel(source, bandwidth, kernel_type) =>
switch kernel_type
"Epanechnikov" => math.abs(source) <= 1 ? 0.75 * (1 - math.pow(source, 2)) : 0.0
"Logistic" => 1/math.exp(source + 2 + math.exp(-source))
"Wave" => math.abs(source) <= 1 ? (1 - math.abs(source)) * math.cos(math.pi * source) : 0.
kernelRegression(src, bandwidth, kernel_type) =>
sumWeightedY = 0.
sumKernels = 0.
for i = 0 to bandwidth - 1
base = i*i/math.pow(bandwidth, 2)
kernel = kernel(base, 1, kernel_type)
sumWeightedY += kernel * src
sumKernels += kernel
(src - sumWeightedY/sumKernels)/src
// Triple Confirmations
Ep = kernelRegression(source, bandwidth, 'Epanechnikov' )
Lo = kernelRegression(source, bandwidth, 'Logistic' )
Wa = kernelRegression(source, bandwidth, 'Wave' )
By combining these regressions in an unbiased average, we follow our principle of achieving confluence for a signal or a decision, by stacking several edges to increase the probability that we are correct.
// Average
AV = math.avg(Ep, Lo, Wa)
The Standard Deviation bands take defined parameters from the user, in this case sigma of ideally between 2 to 3,
to help the indicator detect extremely improbable conditions and thus take an inversely probable signal from it to forward to the user.
The parameter settings and also the visualizations allow for ample customizations by the trader. The indicator comes with default and recommended settings.
For questions or recommendations, please feel free to seek contact in the comments.
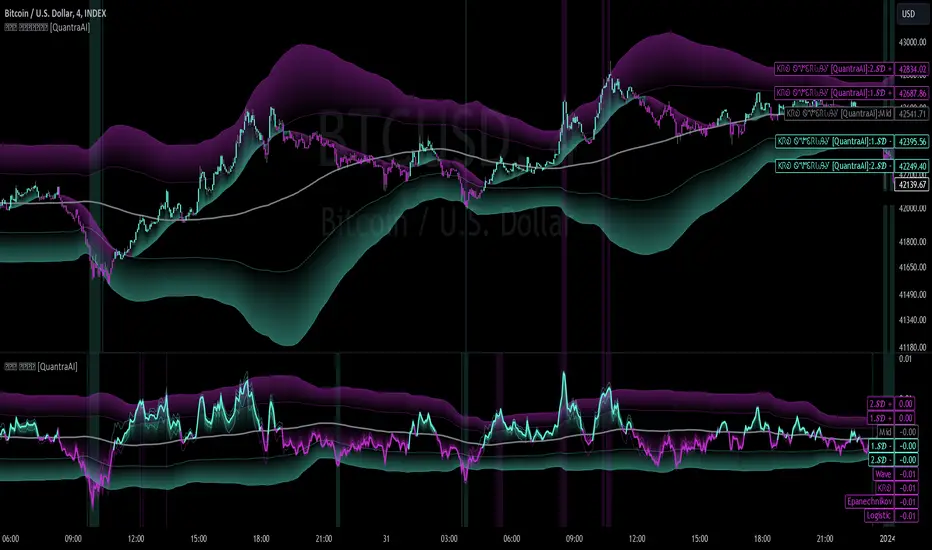
Triple Confirmation Kernel Regression Base [QuantraSystems]Kernel Regression Oscillator - BASE
Introduction
The Kernel Regression Oscillator (ᏦᏒᎧ) represents an advanced tool for traders looking to capitalize on market trends.
This Indicator is valuable in identifying and confirming trend directions, as well as probabilistic and dynamic oversold and overbought zones.
It achieves this through a unique composite approach using three distinct Kernel Regressions combined in an Oscillator. The additional Chart Overlay Indicator adds confidence to the signal.
This methodology helps the trader to significantly reduce false signals and offers a more reliable indication of market movements than more widely used indicators can.
Legend
The upper section is the Overlay. It features the Signal Wave to display the current trend.
Its Overbought and Oversold zones start at 50% and end at 100% of the selected Standard Deviation (default σ = 3), which can indicate extremely rare situations which can lead to either a softening momentum in the trend or even a mean reversion situation.
The lower one is the Base Chart - This Indicator.
It features the Kernel Regression Oscillator to display a composite of three distinct regressions, also displaying current trend.
Its Overbought and Oversold zones start at 50% and end at 100% of the selected Standard Deviation (default σ = 2), which can indicate extremely rare situations.
Case Study
To effectively utilize the ᏦᏒᎧ, traders should use both the additional Overlay and the Base
Chart at the same time. Then focus on capturing the confluence in signals, for example:
If the 𝓢𝓲𝓰𝓷𝓪𝓵 𝓦𝓪𝓿𝓮 on the Overlay and the ᏦᏒᎧ on the Base Chart both reside near the extreme of an Oversold zone the probability is higher than normal that momentum in trend may soften or the token may even experience a reversion soon.
If a bar is characterized by an Oversold Shading in both the Overlay and the Base Chart, then the probability is very high to experience a reversion soon.
In this case the trader may want to look for appropriate entries into a long position, as displayed here.
If a bar is characterized by an Overbought Shading in either Overlay or Base Chart, then the probability is high for momentum weakening or a mean reversion.
In this case the trade may have taken profit and closed his long position, as displayed here.
Please note that we always advise to find more confluence by additional indicators.
Recommended Settings
Swing Trading (1D chart)
Overlay
Bandwith: 45
Width: 2
SD Lookback: 150
SD Multiplier: 2
Base Chart
Bandwith: 45
SD Lookback: 150
SD Multiplier: 2
Fast-paced, Scalping (4min chart)
Overlay
Bandwith: 75
Width: 2
SD Lookback: 150
SD Multiplier: 3
Base Chart
Bandwith: 45
SD Lookback: 150
SD Multiplier: 2
Notes
The Kernel Regression Oscillator on the Base Chart is also sensitive to divergences if that is something you are keen on using.
For maximum confluence, it is recommended to use the indicator both as a chart overlay and in its Base Chart.
Please pay attention to shaded areas with Standard Deviation settings of 2 or 3 at their outer borders, and consider action only with high confidence when both parts of the indicator align on the same signal.
This tool shows its best performance on timeframes lower than 4 hours.
Traders are encouraged to test and determine the most suitable settings for their specific trading strategies and timeframes.
The trend following functionality is indicated through the "𝓢𝓲𝓰𝓷𝓪𝓵 𝓦𝓪𝓿𝓮" Line, with optional "Up" and "Down" arrows to denote trend directions only (toggle “Show Trend Signals”).
Methodology
The Kernel Regression Oscillator takes three distinct kernel regression functions,
used at similar weight, in order to calculate a balanced and smooth composite of the regressions. Part of it are:
The Epanechnikov Kernel Regression: Known for its efficiency in smoothing data by assigning less weight to data points further away from the target point than closer data points, effectively reducing variance.
The Wave Kernel Regression: Similarly assigning weight to the data points based on distance, it captures repetitive and thus wave-like patterns within the data to smoothen out and reduce the effect of underlying cyclical trends.
The Logistic Kernel Regression: This uses the logistic function in order to assign weights by probability distribution on the distance between data points and target points. It thus avoids both bias and variance to a certain level.
kernel(source, bandwidth, kernel_type) =>
switch kernel_type
"Epanechnikov" => math.abs(source) <= 1 ? 0.75 * (1 - math.pow(source, 2)) : 0.0
"Logistic" => 1/math.exp(source + 2 + math.exp(-source))
"Wave" => math.abs(source) <= 1 ? (1 - math.abs(source)) * math.cos(math.pi * source) : 0.
kernelRegression(src, bandwidth, kernel_type) =>
sumWeightedY = 0.
sumKernels = 0.
for i = 0 to bandwidth - 1
base = i*i/math.pow(bandwidth, 2)
kernel = kernel(base, 1, kernel_type)
sumWeightedY += kernel * src
sumKernels += kernel
(src - sumWeightedY/sumKernels)/src
// Triple Confirmations
Ep = kernelRegression(source, bandwidth, 'Epanechnikov' )
Lo = kernelRegression(source, bandwidth, 'Logistic' )
Wa = kernelRegression(source, bandwidth, 'Wave' )
By combining these regressions in an unbiased average, we follow our principle of achieving confluence for a signal or a decision, by stacking several edges to increase the probability that we are correct.
// Average
AV = math.avg(Ep, Lo, Wa)
The Standard Deviation bands take defined parameters from the user, in this case sigma of ideally between 2 to 3,
to help the indicator detect extremely improbable conditions and thus take an inversely probable signal from it to forward to the user.
The parameter settings and also the visualizations allow for ample customizations by the trader. The indicator comes with default and recommended settings.
For questions or recommendations, please feel free to seek contact in the comments.

FX Forecasting Model [TrendX_]FX Forecasting Model indicator is a forecasting tool that takes advantages of macroeconomic analysis and market surveillance to predict Exchange rate movement.
*** Customize the macro data for home country (base currency) and foreign country
USAGE
This consists of 4 editable options align with 4 Forecasting Models
TrendX Model)
TrendX Model is a type of multiple linear regression, which is a statistical method that estimates the relationship between the currency exchange rate and various macroeconomic indicators.
*** Remember the 1st thing to do is to customize the macro data for home country (base currency) and foreign country, before take any further steps.
Purchasing Power Parity (PPP Model)
The PPP model is a conceptual model of currency exchange. The model illustrates how the exchange rate between two countries’ currencies is influenced by the variations in the prices of goods and services in those countries, which depend on the inflation rate. The activity of buying and selling goods and services internationally will shift the exchange rate to balance the prices in both countries.
Interest Rate Parity (IRP Model)
Interest Rate Parity (IRP) model is a theoretical model that relates the interest rates and the exchange rates of two countries. According to IRP, the difference between the forward and spot exchange rates of two currencies should be equal to the difference between their interest rates. IRP helps traders to determine the fair value of a currency pair and compare it with the market value. If the market value deviates from the fair value, then there is a potential for arbitrage or hedging.
Combined Forecast Model (Mixed Model)
Since each model has its own advantages, many people are interested in the concept of using a mix of forecasts to get better results than any single forecast. Mix Model is a method that uses different proportions of the forecasts from three models: TrendX, PPP and IRP models. The default proportion is 0.2 for TrendX, and 0.4 for both PPP and IRP. You can change these proportions according to your liking.
CONCLUSION
FX Forecasting Model Indicator is very practical for FOREX traders who wants to make informed and rational decisions based on Macroeconomic Analysis. It can help find arbitrage opportunity in currency exchange market. Accordingly, it can also be helpful for traders to use alongside other forms of Technical Analysis.
DISCLAIMER
The results achieved in the past are not all reliable sources of what will happen in the future. There are many factors and uncertainties that can affect the outcome of any endeavor, and no one can guarantee or predict with certainty what will occur.
Therefore, you should always exercise caution and judgment when making decisions based on past performance.

Chaos CypherOverview
Technically a smooth linear rate transformation, the "Chaos Cypher" drew some inspiration from the principles of Markov and chaos. Aside from price action, this combination provides a different lens through which to observe and interpret market movements. Markov models are based on the principle that future states depend only on the current state, not on the sequence of events that preceded it. Chaos theory deals with systems that are highly sensitive to initial conditions, a concept popularly referred to as the butterfly effect.
Efficient with Minimal Data: Designed to perform efficiently, the CC indicator is particularly useful in situations regardless of extensive historical data, except for obvious back testing, while still providing strength at identifying potential overbought/oversold zones and critical divergences.
Simplified Momentum Analysis: With further inspiration from the triple smoothed exponential rate, the CC actually uses linear regression for its calculations. This approach allows for a clear and more straightforward identification of deviations in momentum. The smoothing helps allow it to provide details while still operating at a fast pace due to the regression speed.
Adaptable to Various Timeframes: The transformation calculation then employed effectively narrows its scope in relation to the pace, enhancing its applicability across multiple timeframes and periods. This flexibility makes it a versatile tool suitable for various strategies and market conditions.
Fisher Transform Style Presentation: The indicator is presented in a style reminiscent of the Fisher Transform. However, this method of the script recalculates based on every individual dataset. To maintain efficiency, the adjustable length only applies to the regression rate.
The Chaos Cypher when compared to the Fisher Transform
Inversion Option for Leads: Lastly, an intriguing find when testing this script is the potential of the inversion option. This aspect proved particularly useful when searching for pullbacks on a trending market.
Conclusion
This indicator is designed to be forward-thinking and attempts to combine theoretical concepts with practicality. It has the ability to work with minimal data, adapt to various timeframes, and provide clear views of market movements. It back tested very well even when unrealistically used as a sole instrument.
"Two states differing by imperceptible amounts may eventually evolve into two considerably different states ... If, then, there is any error whatever in observing the present state—and in any real system such errors seem inevitable—an acceptable prediction of an instantaneous state in the distant future may well be impossible....In view of the inevitable inaccuracy and incompleteness of weather observations, precise very-long-range forecasting would seem to be nonexistent." -Edward Norton Lorenz
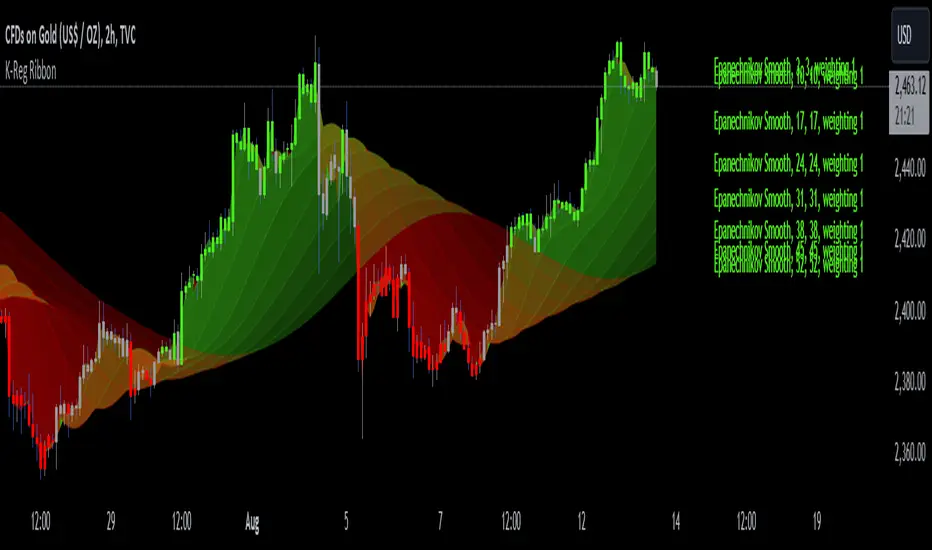
Kernel Regression RibbonKernel Regression Ribbon is a flexible, visually pleasing trend identification tool. Plotting 8 different kernel regressions of different types and parameters allows the user to see where levels of support and resistance are being tested, retested and broken.
What’s Kernel Regression?
A statistical method for estimating the best fitting curve for a dataset, in this case, a time/price chart.
How’s Kernel Regression different from a Moving Average?
A Moving Average is basically a simple form of Kernel Regression, in that it uses a fixed (Retangular) Kernel function. In an MA, all data points are weighted equally over its length. However, a Kernel function reacts more to data points that are closer to the current point. This means it will adapt more quickly to changes in data than an MA. Due to this adaptability, Kernel functions often form part of Machine Learning.
Using this indicator:
Explore the default Regular mode first to get a feel for the inputs, which are more numerous than for MAs. Try out different settings, filters and intervals to get the best out of each kernel. Not all parameters are available for each KR. There are info tips to explain this in the menu, but I’ve also included handy, optional labels on the chart for each KR as a more accessible guide.
Once you know your way round the Regular mode, check out the Presets and start changing the parameters of each kernel to your liking in the “User KR1, KR2, … “ mode. Each kernel type has its strong and weak points. Blending different kernels is where this indicator comes into its own. Give your charts a funky shine!
This indicator does NOT repaint.
This script acknowledges, and hopefully showcases, the great work of @veryfid Kernel Regression Toolkit.
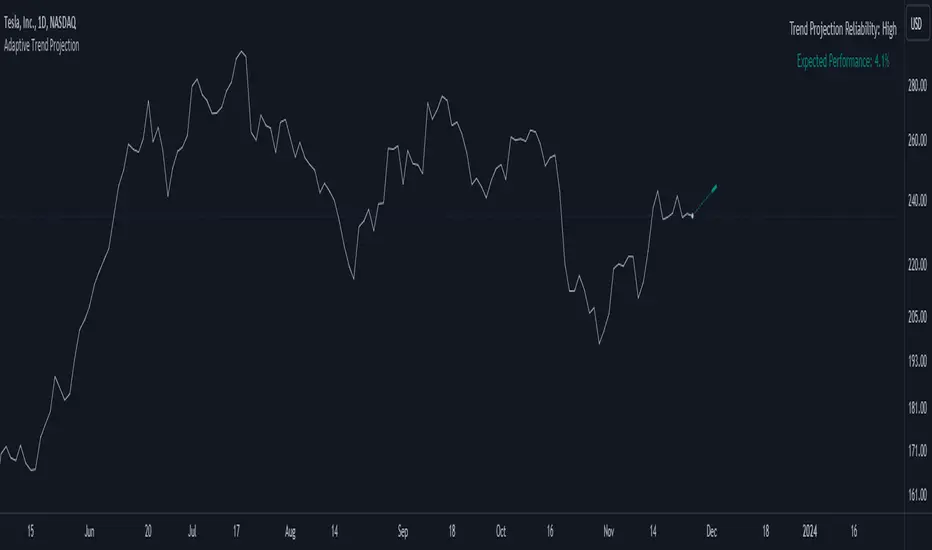
Adaptiv Trend Projection with Dynamic Length RegressionThe Adaptive Trend Projection indicator is a robust tool designed to provide an optimal trend projection calculated in a highly sophisticated manner. By utilizing linear regression lengths ranging from 20 to 200, this indicator estimates the duration of the trend by dynamically adjusting the projection length based on the calculated trend's strength.
Key Features:
1. Dynamic Length Adjustment: The indicator intelligently adapts the projection length between 20 and 200 using linear regression, ensuring adaptability to market conditions.
2. Trend Strength Calculation: Through linear regression analysis, the indicator calculates the slope, average, and intercept for each selected length, providing insights into the strength and direction of the trend.
3. Deviation Analysis: Beyond traditional trend analysis, the indicator calculates standard deviation, Pearson's correlation coefficient, and deviation values, offering a comprehensive view of market dynamics.
4. Confidence Levels: A unique feature of the Adaptive Trend Projection is its ability to determine confidence levels based on the highest Pearson's R value. Reliability is categorized into levels such as Neutral, Moderate, High, Very High, and Ultra High, providing users with a quick assessment of the projection's robustness.
5. Dynamic Forecasting: The indicator not only analyzes historical data but extends its functionality by dynamically forecasting future trend points. The projection adjusts in length based on the strength of the trend, allowing for more accurate predictions.
6. Visual Clarity: Enhancing visual clarity, the Adaptive Trend Projection indicator uses different line styles, widths, and colors to highlight crucial points, making it easier for traders to interpret and act upon the information.
In conclusion, the Adaptive Trend Projection indicator offers a nuanced understanding of market trends by combining advanced linear regression techniques, deviation analysis, and confidence level assessments. This enables traders to make informed decisions.
KNN ATR Dual Range Predictions [SS]Excited to release this indicator!
I wanted to do a machine learning, ATR based indicator for a while, but I first had to learn about machine learning algos haha.
Now that I have created a KNN based regression methodology (shared in a previous indicator), I can finally do it!
So this is a Nearest Known Neighbor or KNN regression based indicator that uses ATR (average ranges) to predict future ranges.
It operates by calculating the move from High to Open and Open to Low and performing KNN regression to look for other, similar instances of similar movements and what followed those movements.
It provides for 2 methods of KNN regression, the traditional Cluster method (where it identifies a number of clusters within a tolerance range and averages them out), or the method of last instance (where it finds the most recent identical instance and plots the result from that).
You can toggle the parameters as you wish, including the:
a) Type of Regression
b) Number of Clusters
c) Tolerance for Clusters
Others functions:
The indicator provides for the ability to view 2 different timeframe targets. The default calculation is the current timeframe you are on. So if you are on the 1 minute, 5 minute or 1 hour, it will automatically default the primary range to this timeframe. This cannot be changed.
But it permits for a second prediction to be calculated for a timeframe you can specify. The example in the chart above is the 1 hour overlaid on the 5 minute chart.
You can see how the model is performing in the statistics table. The statistics table can be removed as well if you don't want it overlaid on your chart.
You can also toggle off and on the various ranges. IF you only want to visualize 1 hour levels on a 5 minute chart, you can toggle off the bands and just view the higher tf data. Inversely, if you only want the current timeframe data and not the higher tf data, you can toggle the higher tf data off as well.
General Use Tips:
Some general use tips include:
🎯The default settings are appropriate for most common tickers. Because this is performing an autoregression on itself, the parameters tend to be more tight vs. performing dual correlation between two separate tickers which are sizably different in scale (which would require a higher tolerance).
Here is an example of YM1!, which is a sizably larger ticker, however it is performing well with the current settings.
🎯 If you get not great results from your ranges or an error in the correlation table, something like this:
It means the parameters are too tight for what you want to do and it is having trouble identifying other, similar cases (in this case, the lookback length was significantly shortened). The first step is to:
a) Expand your lookback range (up to 500 is usually sufficient). This should resolve most issues in most cases. If not:
b) If you are using the Cluster method, try broadening your cluster tolerance by 0.5 increments.
Between those two implementations, you should get a functional model. And it actually honestly hasn't happened to me in general use, I had to force that example by significantly shortening the lookback period.
Concluding Remarks
And that's pretty much the indicator.
I hope you enjoy it! I was really excited to be finally able to do it, like I said I attempted to do this for a while but needed to research the whole KNN process and how its performed.
Enjoy and leave your comments and questions below!

KNN Regression [SS]Another indicator release, I know.
But note, this isn't intended to be a stand-alone indicator, this is just a functional addition for those who program Machine Learning algorithms in Pinescript! There isn't enough content here to merit creating a library for (it's only 1 function), but it's a really useful function for those who like machine learning and Nearest Known Neighbour Algos (or KNN).
About the indicator:
This indicator creates a function to perform KNN-based regression.
In contrast to traditional linear regression, KNN-based regression has the following advantages over linear regression:
Advantages of KNN Regression vs. Linear Regression:
🎯 Non-linearity: KNN is a non-parametric method, meaning it makes no assumptions about the underlying data distribution. This allows it to capture non-linear relationships between features and the target variable.
🎯Simple Implementation: KNN is conceptually simple and easy to understand. It doesn't require the estimation of parameters, making it straightforward to implement.
🎯Robust to Outliers: KNN is less sensitive to outliers compared to linear regression. Outliers can have a significant impact on linear regression models, but KNN tends to be less affected.
Disadvantages of KNN Regression vs. Linear Regression:
🎯 Resource Intensive for Computation: Because KNN operates on identifying the nearest neighbors in a dataset, each new instance has to be searched for and identified within the dataset, vs. linear regression which can create a coefficient-based model and draw from the coefficient for each new data point.
🎯Curse of Dimensionality: KNN performance can degrade with an increasing number of features, leading to a "curse of dimensionality." This is because, in high-dimensional spaces, the concept of proximity becomes less meaningful.
🎯Sensitive to Noise: KNN can be sensitive to noisy data, as it relies on the local neighborhood for predictions. Noisy or irrelevant features may affect its performance.
Which is better?
I am very biased, coming from a statistics background. I will always love linear regression and will always prefer it over KNN. But depending on what you want to accomplish, KNN makes sense. If you are using highly skewed data or data that you cannot identify linearity in, KNN is probably preferable.
However, if you require precise estimations of ranges and outliers, such as creating co-integration models, I would advise sticking with linear regression. However, out of curiosity, I exported the function into a separate dummy indicator and pulled in data from QQQ to predict SPY close, and the results are actually very admirable:
And plotted with showing the standard error variance:
Pretty impressive, I must say I was a little shocked, it's really giving linear regression a run for its money. In school I was taught LinReg is the gold standard for modeling, nothing else compares. So as with most things in trading, this is challenging some biases of mine ;).
Functionality of the function
I have permitted 3 types of KNN regression. Traditional KNN regression, as I understand it, revolves around clustering. ( Clustering refers to identifying a cluster, normally 3, of identical cases and averaging out the Dependent variable in each of those cases) . Clustering is great, but when you are working with a finite dataset, identifying exact matches for 2 or 3 clusters can be challenging when you are only looking back at 500 candles or 1000 candles, etc.
So to accommodate this, I have added a functionality to clustering called "Tolerance". And it allows you to set a tolerance level for your Euclidean distance parameters. As a default, I have tested this with a default of 0.5 and it has worked great and no need to change even when working with large numbers such as NQ and ES1!.
However, I have added 2 additional regression types that can be done with KNN.
#1 One is a regression by the last IDENTICAL instance, which will find the most recent instance of a similar Independent variable and pull the Dependent variable from that instance. Or
#2 Average from all IDENTICAL instances.
Using the function
The code has the instructions for integrating the function into your own code, the parameters, and such, so I won't exhaust you with the boring details about that here.
But essentially, it exports 3, float variables, the Result, the Correlation, and the simplified R2.
As this is KNN regression, there are no coefficients, slopes, or intercepts and you do not need to test for linearity before applying it.
Also, the output can be a bit choppy, so I tend to like to throw in a bit of smoothing using the ta.sma function at a deault of 14.
For example, here is SPY from QQQ smoothed as a 14 SMA:
And it is unsmoothed:
It seems relatively similar but it does make a bit of an aesthetic difference. And if you are doing it over 14, there is no data loss and it is still quite reactive to changes in data.
And that's it! Hopefully you enjoy and find some interesting uses for this function in your own scripts :-).
Safe trades everyone!

Predictive Candles Variety Pack [SS]This indicator provides you with the ability to select from a variety of candle prediction methods.
It permits for:
👉 Traditional Linear Regression Candle Predictions
👉 Candle Predictions based on the underlying Stochastics
👉 Candle Predictions based on the underlying RSI
👉 Candle Predictions based on the underlying MFI
👉 Candle Predictions based on the EMA 9
👉 Candle Predictions based on ARIMA modelling
Which is best?
Each method serves its unique purpose.
Here are some general tips of which candles are better suited for what:
🎯Trend Following🎯
For Trend following, the EMA 9 would be an appropriate choice of candle as it helps you to identify the current trend and potential early pullbacks/reversals.
🎯Momentum Following🎯
Momentum following is best carried out with the Stochastics Candles.
🎯Pullback Determination🎯
Pullback Determination is best accomplished through the RSI candles, as the ranges compress or expand based on the current state of oversold/overboughtness.
🎯Detrended Range🎯
To see the detrended range of where the ticker should be falling, absent the trendy noise, it's best to use the ARIMA candles.
Other Features
👉 Other features include a Backtest option that can be toggled on or off and will backtest over the length of the assessment. I don't recommend leaving it on as it can be resource-heavy on Pinescript though.
👉 The ability to adjust the transparency of the candles if you want them to be more or less visible.
Troubleshooting Note
The ARIMA modeling version is extremely resource-heavy, as it has to fully develop an ARIMA model. I have tried to optimize it by reducing the lagged assessment to just 2 lags. If you are using a free or non-premium membership, you may need to reduce the length of the assessment.
And that's it! Pretty straightforward indicator.
Hope you enjoy it!

MacroTrend VisionThe "MacroTrend Vision" indicator is crafted with a singular goal – to provide traders with a quick and insightful snapshot of a country's global index. Seamlessly combining macroeconomic and technical perspectives, this tool is designed for those seeking a straightforward yet comprehensive overview. Let's explore the key features that make the "MacroTrend Vision" a valuable asset for traders looking to grasp both the big-picture economic context and technical nuances.
1. Long-Term Vision with Weekly Periods:
Gain a genuine long-term perspective with the ability to process 2500 weekly periods. This feature ensures a holistic understanding of global indices from both macroeconomic and technical viewpoints.
2. Composite Leading Indicator (CLI) Conditions:
Integrate both macroeconomic trends and technical signals through Composite Leading Indicator (CLI) conditions derived from the Relative Strength Index (RSI), offering a comprehensive outlook for informed decision-making.
3. Deviation Bands for Volatility Analysis:
Refine market analysis with strategically integrated deviation bands (0.2 and 0.4) based on smoothed linear regression. Anticipate volatility and potential trend shifts, aligning macro and technical insights.
4. Logarithmic Scale Transformation:
Enhance precision in understanding price movements with a logarithmic scale transformation, especially beneficial for assets with exponential growth patterns.
5. Separated Window for Easy Navigation:
Streamline your analysis with a user-friendly design – a separated window allowing easy navigation through different symbols without altering indicator settings.
6. Alert System for CLI Conditions:
Stay informed about critical shifts with an alert system for both long and close conditions based on the RSI of the CLI. Even during periods of limited chart monitoring, this feature keeps you connected to macroeconomic and technical changes.
In essence, the "MacroTrend Vision" is your go-to tool for a balanced view, simplifying the complexities of global indices with a blend of macroeconomic insights and technical clarity.

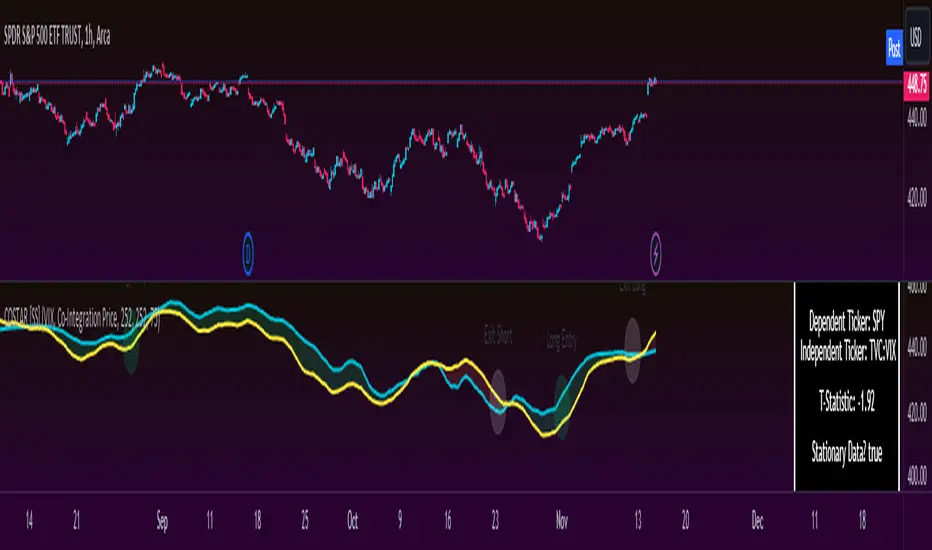
COSTAR [SS]This idea came to me after I wrote the post about Co-Integration and pair trading. I wondered if you could use pair trading principles as a way to determine overbought and oversold conditions in a more neutral way than RSI or Stochastics.
The results were promising and this indicator resulted :-)!
About:
COSTAR provides another, more neutral way to determine whether an equity is overbought or oversold.
Instead of relying on the traditional oscillator based ways, such as using RSI, Stochastics and MFI, which can be somewhat biased and narrow sided, COSTAR attempts to take a neutral, unbiased approached to determine overbought and oversold conditions. It does this through using a co-integrated partner, or "pair" that is closely linked to the underlying equity and succeeds on both having a high correlation and a high t-statistic on the ADF test. It then references this underlying, co-integrated partner as the "benchmark" for the co-integration relationship.
How this succeeds as being "unbiased" and "neutral" is because it is responsive to underlying drivers. If there is a market catalyst or just general bullish or bearish momentum in the market, the indicator will be referencing the integrated relationship between the two pairs and referencing that as a baseline. If there is a sustained rally on the integrated partner of the underlying ticker that is holding, but the other ticker is lagging, it will indicate that the other ticker is likely to be under-valued and thus "oversold" because it is underperforming its benchmark partner.
This is in contrast to traditional approaches to determining overbought and oversold conditions, which rely completely on a single ticker, with no external reference to other tickers and no control over whether the move could potentially be a fundamental move based on an industry or sector, or whether it is a fluke or a squeeze.
The control for this giving "false" signals comes from its extent of modelling and assessment of the degree of integration of the relationship. The parameters are set by default to assess over a 1 year period, both the correlation and the integration. Anything that passes this degree of integration is likely to have a solid, co-integrated state and not likely to be a "fluke". Thus, the reliability of the assessment is augmented by the degree of statistical significance found within the relationship. The indicator is not going to prompt you to rely on a relationship that is statistically weak, and will warn you of such.
The indicator will show you all the information you require regarding the relationship and whether it is reliable or not, so you do not need to worry!
How to Use
The first step to use COSTAR is identifying which ticker has a strong relationship with the current ticker. In the main chart, you will see that SPY is overlaid with VIX. There is a strong, negative correlation between the VIX and SPY. When VIX is entered as the paired ticker, the indicator returns the data as stationary, indicating a compatible match.
Now you have 3 ways of viewing this relationship, 2 of which are going to be directly applicable to trading.
You can view them as
Price to Price Ratio (Not very useful for trading, but if you are curious)
Z-Score: Helpful for trading
Co-integration: Helpful for trading
Here is an example of all three:
Example of Z-Score Chart:
Example of Price Ratio:
Example of Co-Integration Pair:
Using for Trading
As stated above, the two best ways to use this for trading is to either use the Z-Score Chart or the Co-Integrated Pair chart.
The Z-Score chart is based off of the price ratio data and provides an assessment of both the independent and dependent data.
The co-integration shows the dependent (the ticker you are trading) in yellow and the independent (the ticker you are referencing) in teal. When teal is above yellow, you will see it is green. This means, based on your benchmark pair, there is still more up room and the ticker you are trading is actually lagging behind.
When the yellow crosses up, it will turn red. This means that your ticker is out-performing the benchmark pair and you likely will see pullback and a "regression to the mean" through re-integration.
The indicator is capable of plotting out entries and exits, which are guided by the z-score:
How Effective is it?
I created a basic strategy in Pinescript, and the back-test results vary. Trading ES1! using NQ1! as the co-integrated pair, results were around 78% effective.
With VIX, results were around 50% effective, but with a net profit.
Generally, the efficacy surpassed that of both stochastics and RSI.
I will be releasing the strategy version of this in the coming days, still just cleaning up that code and making it more "public use" friendly.
Other Applications
If you are a pair trader, you can technically use this for pair trading as well. That's essentially all this is doing :-).
Tips
If you are trading a ticker such as MSFT, AMD, KO etc., it's best to try to find an ETF or index that has that particular ticker as a large holding and use that as your benchmark. You will see on the indicator whether there is a high correlation and whether the data is indeed stationary.
If the indicator returns "Non-stationary", you can attempt to extend your regression range from 252 to 500. If this fixes the issue, ensure that the correlation is still >= 0.5 or <= -0.5. If this does not work still, you will need to find another pair, as its likely the result of incompatibility and an insignificant relationship.
To help you identify tickers with strong relationships, consider using a correlation heatmap indicator. I have one available and I think there are a couple of other similar ish ones out there. You want to make sure the relationship is stable over time (a correlation of >= 0.50 or <= -0.5 over the past 252 to 500 days).
IMPORTANT: The long and short exits delete the signal after one is signaled. Therefore, when you look back in the chart you will notice there are no signals to exit long or short. That is because they signal as they happen. This is to keep the chart clean.
'Tis all my friends!
Hope you enjoy and let me know your questions and suggestions below!
Side note:
COSTAR stands for Co-integration Statistical Analysis and Regression. ;)