COT Report Indicator with Selectable Data TypeOverview
The COT Report Indicator with Selectable Data Types is a powerful tool for traders who want to gain deeper insights into market sentiment using the Commitment of Traders (COT) data. This indicator allows you to visualize the net positions of different participant categories—Commercial, Noncommercial, and Nonreportable—directly on your chart.
The indicator is fully customizable, allowing you to select the type of data to display, sync with your chart's timeframe, or choose a custom timeframe. Whether you're analyzing gold, crude oil, indices, or forex pairs, this indicator adapts seamlessly to your trading needs.
Features
Dynamic Data Selection:
Choose between Commercial, Noncommercial, or Nonreportable data types.
Analyze the net positions of market participants for more informed decision-making.
Flexible Timeframes:
Sync with the chart's timeframe for quick analysis.
Select a custom timeframe to view COT data at your preferred granularity.
Wide Asset Coverage:
Supports various assets, including gold, silver, crude oil, indices, and forex pairs.
Automatically adjusts to the ticker you're analyzing.
Clear Visual Representation:
Displays Net Long, Net Short, and Net Difference (Long - Short) positions with distinct colors for easy interpretation.
Error Handling:
Alerts you if the symbol is unsupported, ensuring you know when COT data isn't available for a specific asset.
How to Use
Add the Indicator:
Click "Indicators" in TradingView and search for "COT Report Indicator with Selectable Data Types."
Add it to your chart.
Customize the Settings:
Data Type: Choose between Commercial, Noncommercial, or Nonreportable positions.
Data Source: Select "Futures Only" or "Futures and Options."
Timeframe: Sync with the chart's timeframe or specify a custom one (e.g., weekly, monthly).
Interpret the Data:
Green Line: Net Long Positions.
Red Line: Net Short Positions.
Black Line: Net Difference (Long - Short).
Supported Symbols:
Gold, Silver, Crude Oil, Natural Gas, Forex Pairs, S&P 500, US30, NAS100, and more.
Who Can Benefit
Trend Followers: Identify the buying/selling trends of Commercial and Noncommercial participants.
Sentiment Analysts: Understand shifts in sentiment among major market players.
Long-Term Traders: Use COT data to confirm or contradict your fundamental analysis.
Example Use Case
For example, if you're trading gold (XAUUSD) and select Noncommercial Positions, you’ll see the long and short positions of speculators. An increase in net long positions may signal bullish sentiment, while an increase in net short positions may indicate bearish sentiment.
If you switch to Commercial Positions, you'll get insights into how hedgers and institutions are positioning themselves, helping you confirm or counterbalance your current trading strategy.
Limitations
The indicator only works with supported symbols (COT data availability is limited to specific assets).
The COT data is updated weekly, so it is not suitable for short-term intraday trading.
Statistics

Weekly H/L DOTWThe Weekly High/Low Day Breakdown indicator provides a detailed statistical analysis of the days of the week (Monday to Sunday) on which weekly highs and lows occur for a given timeframe. It helps traders identify recurring patterns, correlations, and tendencies in price behavior across different days of the week. This can assist in planning trading strategies by leveraging day-specific patterns.
The indicator visually displays the statistical distribution of weekly highs and lows in an easy-to-read tabular format on your chart. Users can customize how the data is displayed, including whether the table is horizontal or vertical, the size of the text, and the position of the table on the chart.
Key Features:
Weekly Highs and Lows Identification:
Tracks the highest and lowest price of each trading week.
Records the day of the week on which these events occur.
Customizable Table Layout:
Option to display the table horizontally or vertically.
Text size can be adjusted (Small, Normal, or Large).
Table position is customizable (top-right, top-left, bottom-right, or bottom-left of the chart).
Flexible Value Representation:
Allows the display of values as percentages or as occurrences.
Default setting is occurrences, but users can toggle to percentages as needed.
Day-Specific Display:
Option to hide Saturday or Sunday if these days are not relevant to your trading strategy.
Visible Date Range:
Users can define a start and end date for the analysis, focusing the results on a specific period of interest.
User-Friendly Interface:
The table dynamically updates based on the selected timeframe and visibility of the chart, ensuring the displayed data is always relevant to the current context.
Adaptable to Custom Needs:
Includes all-day names from Monday to Sunday, but allows for specific days to be excluded based on the user’s preferences.
Indicator Logic:
Data Collection:
The indicator collects daily high, low, day of the week, and time data from the selected ticker using the request.security() function with a daily timeframe ('D').
Weekly Tracking:
Tracks the start and end times of each week.
During each week, it monitors the highest and lowest prices and the days they occurred.
Weekly Closure:
When a week ends (detected by Sunday’s daily candle), the indicator:
Updates the statistics for the respective days of the week where the weekly high and low occurred.
Resets tracking variables for the next week.
Visible Range Filter:
Only processes data for weeks that fall within the visible range of the chart, ensuring the table reflects only the visible portion of the chart.
Statistical Calculations:
Counts the number of weekly highs and lows for each day.
Calculates percentages relative to the total number of weeks in the visible range.
Dynamic Table Display:
Depending on user preferences, displays the data either horizontally or vertically.
Formats the table with proper alignment, colors, and text sizes for easy readability.
Custom Value Representation:
If set to "percentages," displays the percentage of weeks a high/low occurred on each day.
If set to "occurrences," displays the raw count of weekly highs/lows for each day.
Input Parameters:
High Text Color:
Color for the text in the "Weekly High" row or column.
Low Text Color:
Color for the text in the "Weekly Low" row or column.
High Background Color:
Background color for the "Weekly High" row or column.
Low Background Color:
Background color for the "Weekly Low" row or column.
Table Background Color:
General background color for the table.
Hide Saturday:
Option to exclude Saturday from the analysis and table.
Hide Sunday:
Option to exclude Sunday from the analysis and table.
Values Format:
Dropdown menu to select "percentages" or "occurrences."
Default value: "occurrences."
Table Position:
Dropdown menu to select the table position on the chart: "top_right," "top_left," "bottom_right," "bottom_left."
Default value: "top_right."
Text Size:
Dropdown menu to select text size: "Small," "Normal," "Large."
Default value: "Normal."
Vertical Table Format:
Checkbox to toggle the table layout:
Checked: Table displays days vertically, with Monday at the top.
Unchecked: Table displays days horizontally.
Start Date:
Allows users to specify the starting date for the analysis.
End Date:
Allows users to specify the ending date for the analysis.
Use Cases:
Day-Specific Pattern Recognition:
Identify if specific days, such as Monday or Friday, are more likely to form weekly highs or lows.
Seasonal Analysis:
Use the start and end date filters to analyze patterns during specific trading seasons.
Strategy Development:
Plan day-based entry and exit strategies by identifying recurring patterns in weekly highs/lows.
Historical Review:
Study historical data to understand how market behavior has changed over time.
TradingView TOS Compliance Notes:
Originality:
This script is uniquely designed to provide day-based statistics for weekly highs and lows, which is not a common feature in other publicly available indicators.
Usefulness:
Offers practical insights for traders interested in understanding day-specific price behavior.
Detailed Description:
Fully explains the purpose, features, logic, input settings, and use cases of the indicator.
Includes clear and concise details on how each input works.
Clear Input Descriptions:
All input parameters are clearly named and explained in the script and this description.
No Redundant Functionality:
Focused specifically on tracking weekly highs and lows, ensuring the indicator serves a distinct purpose without unnecessary features.
Simple Decesion Matrix Classification Algorithm [SS]Hello everyone,
It has been a while since I posted an indicator, so thought I would share this project I did for fun.
This indicator is an attempt to develop a pseudo Random Forest classification decision matrix model for Pinescript.
This is not a full, robust Random Forest model by any stretch of the imagination, but it is a good way to showcase how decision matrices can be applied to trading and within Pinescript.
As to not market this as something it is not, I am simply calling it the "Simple Decision Matrix Classification Algorithm". However, I have stolen most of the aspects of this machine learning algo from concepts of Random Forest modelling.
How it works:
With models like Support Vector Machines (SVM), Random Forest (RF) and Gradient Boosted Machine Learning (GBM), which are commonly used in Machine Learning Classification Tasks (MLCTs), this model operates similarity to the basic concepts shared amongst those modelling types. While it is not very similar to SVM, it is very similar to RF and GBM, in that it uses a "voting" system.
What do I mean by voting system?
How most classification MLAs work is by feeding an input dataset to an algorithm. The algorithm sorts this data, categorizes it, then introduces something called a confusion matrix (essentially sorting the data in no apparently order as to prevent over-fitting and introduce "confusion" to the algorithm to ensure that it is not just following a trend).
From there, the data is called upon based on current data inputs (so say we are using RSI and Z-Score, the current RSI and Z-Score is compared against other RSI's and Z-Scores that the model has saved). The model will process this information and each "tree" or "node" will vote. Then a cumulative overall vote is casted.
How does this MLA work?
This model accepts 2 independent variables. In order to keep things simple, this model was kept as a three node model. This means that there are 3 separate votes that go in to get the result. A vote is casted for each of the two independent variables and then a cumulative vote is casted for the overall verdict (the result of the model's prediction).
The model actually displays this system diagrammatically and it will likely be easier to understand if we look at the diagram to ground the example:
In the diagram, at the very top we have the classification variable that we are trying to predict. In this case, we are trying to predict whether there will be a breakout/breakdown outside of the normal ATR range (this is either yes or no question, hence a classification task).
So the question forms the basis of the input. The model will track at which points the ATR range is exceeded to the upside or downside, as well as the other variables that we wish to use to predict these exceedences. The ATR range forms the basis of all the data flowing into the model.
Then, at the second level, you will see we are using Z-Score and RSI to predict these breaks. The circle will change colour according to "feature importance". Feature importance basically just means that the indicator has a strong impact on the outcome. The stronger the importance, the more green it will be, the weaker, the more red it will be.
We can see both RSI and Z-Score are green and thus we can say they are strong options for predicting a breakout/breakdown.
So then we move down to the actual voting mechanisms. You will see the 2 pink boxes. These are the first lines of voting. What is happening here is the model is identifying the instances that are most similar and whether the classification task we have assigned (remember out ATR exceedance classifier) was either true or false based on RSI and Z-Score.
These are our 2 nodes. They both cast an individual vote. You will see in this case, both cast a vote of 1. The options are either 1 or 0. A vote of 1 means "Yes" or "Breakout likely".
However, this is not the only voting the model does. The model does one final vote based on the 2 votes. This is shown in the purple box. We can see the final vote and result at the end with the orange circle. It is 1 which means a range exceedance is anticipated and the most likely outcome.
The Data Table Component
The model has many moving parts. I have tried to represent the pivotal functions diagrammatically, but some other important aspects and background information must be obtained from the companion data table.
If we bring back our diagram from above:
We can see the data table to the left.
The data table contains 2 sections, one for each independent variable. In this case, our independent variables are RSI and Z-Score.
The data table will provide you with specifics about the independent variables, as well as about the model accuracy and outcome.
If we take a look at the first row, it simply indicates which independent variable it is looking at. If we go down to the next row where it reads "Weighted Impact", we can see a corresponding percent. The "weighted impact" is the amount of representation each independent variable has within the voting scheme. So in this case, we can see its pretty equal, 45% and 55%, This tells us that there is a slight higher representation of z-score than RSI but nothing to worry about.
If there was a major over-respresentation of greater than 30 or 40%, then the model would risk being skewed and voting too heavily in favour of 1 variable over the other.
If we move down from there we will see the next row reads "independent accuracy". The voting of each independent variable's accuracy is considered separately. This is one way we can determine feature importance, by seeing how well one feature augments the accuracy. In this case, we can see that RSI has the greatest importance, with an accuracy of around 87% at predicting breakouts. That makes sense as RSI is a momentum based oscillator.
Then if we move down one more, we will see what each independent feature (node) has voted for. In this case, both RSI and Z-Score voted for 1 (Breakout in our case).
You can weigh these in collaboration, but its always important to look at the final verdict of the model, which if we move down, we can see the "Model prediction" which is "Bullish".
If you are using the ATR breakout, the model cannot distinguish between "Bullish" or "Bearish", must that a "Breakout" is likely, either bearish or bullish. However, for the other classification tasks this model can do, the results are either Bullish or Bearish.
Using the Function:
Okay so now that all that technical stuff is out of the way, let's get into using the function. First of all this function innately provides you with 3 possible classification tasks. These include:
1. Predicting Red or Green Candle
2. Predicting Bullish / Bearish ATR
3. Predicting a Breakout from the ATR range
The possible independent variables include:
1. Stochastics,
2. MFI,
3. RSI,
4. Z-Score,
5. EMAs,
6. SMAs,
7. Volume
The model can only accept 2 independent variables, to operate within the computation time limits for pine execution.
Let's quickly go over what the numbers in the diagram mean:
The numbers being pointed at with the yellow arrows represent the cases the model is sorting and voting on. These are the most identical cases and are serving as the voting foundation for the model.
The numbers being pointed at with the pink candle is the voting results.
Extrapolating the functions (For Pine Developers:
So this is more of a feature application, so feel free to customize it to your liking and add additional inputs. But here are some key important considerations if you wish to apply this within your own code:
1. This is a BINARY classification task. The prediction must either be 0 or 1.
2. The function consists of 3 separate functions, the 2 first functions serve to build the confusion matrix and then the final "random_forest" function serves to perform the computations. You will need all 3 functions for implementation.
3. The model can only accept 2 independent variables.
I believe that is the function. Hopefully this wasn't too confusing, it is very statsy, but its a fun function for me! I use Random Forest excessively in R and always like to try to convert R things to Pinescript.
Hope you enjoy!
Safe trades everyone!

Moment-Based Adaptive DetectionMBAD (Moment-Based Adaptive Detection) : a method applicable to a wide range of purposes, like outlier or novelty detection, that requires building a sensible interval/set of thresholds. Unlike other methods that are static and rely on optimizations that inevitably lead to underfitting/overfitting, it dynamically adapts to your data distribution without any optimizations, MLE, or stuff, and provides a set of data-driven adaptive thresholds, based on closed-form solution with O(n) algo complexity.
1.5 years ago, when I was still living in Versailles at my friend's house not knowing what was gonna happen in my life tomorrow, I made a damn right decision not to give up on one idea and to actually R&D it and see what’s up. It allowed me to create this one.
The Method Explained
I’ve been wandering about z-values, why exactly 6 sigmas, why 95%? Who decided that? Why would you supersede your opinion on data? Based on what? Your ego?
Then I consciously noticed a couple of things:
1) In control theory & anomaly detection, the popular threshold is 3 sigmas (yet nobody can firmly say why xD). If your data is Laplace, 3 sigmas is not enough; you’re gonna catch too many values, so it needs a higher sigma.
2) Yet strangely, the normal distribution has kurtosis of 3, and 6 for Laplace.
3) Kurtosis is a standardized moment, a moment scaled by stdev, so it means "X amount of something measured in stdevs."
4) You generate synthetic data, you check on real data (market data in my case, I am a quant after all), and you see on both that:
lower extension = mean - standard deviation * kurtosis ≈ data minimum
upper extension = mean + standard deviation * kurtosis ≈ data maximum
Why not simply use max/min?
- Lower info gain: We're not using all info available in all data points to estimate max/min; we just pick the current higher and lower values. Lol, it’s the same as dropping exponential smoothing with alpha = 0 on stationary data & calling it a day.
You can’t update the estimates of min and max when new data arrives containing info about the matter. All you can do is just extend min and max horizontally, so you're not using new info arriving inside new data.
- Mixing order and non-order statistics is a bad idea; we're losing integrity and coherence. That's why I don't like the Hurst exponent btw (and yes, I came up with better metrics of my own).
- Max & min are not even true order statistics, unlike a percentile (finding which requires sorting, which requires multiple passes over your data). To find min or max, you just need to do one traversal over your data. Then with or without any weighting, 100th percentile will equal max. So unlike a weighted percentile, you can’t do weighted max. Then while you can always check max and min of a geometric shape, now try to calculate the 56th percentile of a pentagram hehe.
TL;DR max & min are rather topological characteristics of data, just as the difference between starting and ending points. Not much to do with statistics.
Now the second part of the ballet is to work with data asymmetry:
1) Skewness is also scaled by stdev -> so it must represent a shift from the data midrange measured in stdevs -> given asymmetric data, we can include this info in our models. Unlike kurtosis, skewness has a sign, so we add it to both thresholds:
lower extension = mean - standard deviation * kurtosis + standard deviation * skewness
upper extension = mean + standard deviation * kurtosis + standard deviation * skewness
2) Now our method will work with skewed data as well, omg, ain’t it cool?
3) Hold up, but what about 5th and 6th moments (hyperskewness & hyperkurtosis)? They should represent something meaningful as well.
4) Perhaps if extensions represent current estimated extremums, what goes beyond? Limits, beyond which we expect data not to be able to pass given the current underlying process generating the data?
When you extend this logic to higher-order moments, i.e., hyperskewness & hyperkurtosis (5th and 6th moments), they measure asymmetry and shape of distribution tails, not its core as previous moments -> makes no sense to mix 4th and 3rd moments (skewness and kurtosis) with 5th & 6th, so we get:
lower limit = mean - standard deviation * hyperkurtosis + standard deviation * hyperskewness
upper limit = mean + standard deviation * hyperkurtosis + standard deviation * hyperskewness
While extensions model your data’s natural extremums based on current info residing in the data without relying on order statistics, limits model your data's maximum possible and minimum possible values based on current info residing in your data. If a new data point trespasses limits, it means that a significant change in the data-generating process has happened, for sure, not probably—a confirmed structural break.
And finally we use time and volume weighting to include order & process intensity information in our model.
I can't stress it enough: despite the popularity of these non-weighted methods applied in mainstream open-access time series modeling, it doesn’t make ANY sense to use non-weighted calculations on time series data . Time = sequence, it matters. If you reverse your time series horizontally, your means, percentiles, whatever, will stay the same. Basically, your calculations will give the same results on different data. When you do it, you disregard the order of data that does have order naturally. Does it make any sense to you? It also concerns regressions applied on time series as well, because even despite the slope being opposite on your reversed data, the centroid (through which your regression line always comes through) will be the same. It also might concern Fourier (yes, you can do weighted Fourier) and even MA and AR models—might, because I ain’t researched it extensively yet.
I still can’t believe it’s nowhere online in open access. No chance I’m the first one who got it. It’s literally in front of everyone’s eyes for centuries—why no one tells about it?
How to use
That’s easy: can be applied to any, even non-stationary and/or heteroscedastic time series to automatically detect novelties, outliers, anomalies, structural breaks, etc. In terms of quant trading, you can try using extensions for mean reversion trades and limits for emergency exits, for example. The market-making application is kinda obvious as well.
The only parameter the model has is length, and it should NOT be optimized but picked consciously based on the process/system you’re applying it to and based on the task. However, this part is not about sharing info & an open-access instrument with the world. This is about using dem instruments to do actual business, and we can’t talk about it.
∞
IU Price Density(Market Noise)This Price density Indicator will help you understand what and how market noise is calculated and treated.
Market noise = when the market is moving up and down without any clear direction
The Price Density Indicator is a technical analysis tool used to measure the concentration or "density" of price movements within a specific range. It helps traders differentiate between noisy, choppy markets and trending ones.
I’ve developed a custom Pine Script indicator, "IU Price Density," designed to help traders distinguish between noisy, indecisive markets and clear trading opportunities. It can be applied across multiple markets.
How this work:
Formula = (Σ (High𝑖 - Low𝑖)) / (Max(High) - Min(Low))
Where,
High𝑖 = the high price at the 𝑖 data point.
Low𝑖 = the low price at the 𝑖 data point.
Max(High) = highest price over the data set.
Max(Low) = Lowest price over the data set.
How to use it :
This indicator ranges from 0 to 10
Green(0-3) = Trending Market
Orange(3-6) = Market is normal
Red(6-10) = Noise market
💡 Key Features:
Dynamic Visuals: The indicator uses color-coded signals—green for trending markets and red for noisy, volatile conditions—making it easy to identify optimal trading periods at a glance.
Background Shading: With background colors highlighting significant market conditions, traders can quickly assess when to engage or avoid certain trades.
Customizable Parameters: The length and smoothing factors allow for flexibility in adapting the indicator to various assets and timeframes.
Whether you're a swing trader or an intraday strategist, this tool provides valuable insights to improve your market analysis. I’m excited to bring this indicator to the community!

Position Size Using Manual Stop Loss [odnac]
This indicator calculates the risk per position based on user-defined settings.
Two Calculation Methods
1. Manual Stop Loss (%) & Manual Leverage
2. Manual Stop Loss (%) & Optimized Leverage
Settings
1. init_capital
Enter your current total capital.
2. Maximum Risk (%) per Position of Total Capital
Specify the percentage of your total funds to be risked for a single position.
3. manual_SL(%)
Enter the stop-loss percentage.
Range: 0.01 ~ 100
4. manual_leverage
Enter the leverage you wish to use.
Range: 1 ~ 100
Used in the first method (Manual Stop Loss (%) & Manual Leverage).
5. Safety Margin
Specify the safety margin for optimized leverage.
Range: 0.01 ~ 1
Used in the second method (Manual Stop Loss (%) & Optimized Leverage). Details are explained below.
Indicator Colors
Black: Indicates which method is being used.
White: Leverage.
First Green: Funds to be invested.
Second Green: Funds to be invested * Leverage.
First Red: Stop-loss (%).
Second Red: Stop-loss (%) * Leverage.
Details for Each Method:
1. Manual Stop Loss (%) & Manual Leverage
This method calculates the size of the funds based on user-defined stop-loss (%) and leverage settings.
White: manual_leverage.
First Green: Investment = Maximum Risk / (manual_SL / 100) / manual_leverage
Second Green: Maximum Risk * (manual_SL / 100)
First Red: manual_SL.
Second Red: manual_SL * manual_leverage
Ensure that the product of manual_SL and manual_leverage does not exceed 100.
If it does, there is a risk of liquidation.
2. Manual Stop Loss (%) & Optimized Leverage
This method calculates optimized leverage based on the user-defined stop-loss (%) and determines the size of the funds.
Optimization_LEVER = auto_leverage * safety_margin
auto_leverage = 100 / stop-loss (%), rounded down to the nearest whole number.
(Exception: If the stop-loss (%) is in the range of 0 ~ 1%, auto_leverage is always 100.)
Example:
If the stop-loss is 4%, auto_leverage = 25 (100 / 4 = 25).
However, 4% × 25 leverage equals 100%, meaning liquidation occurs even with a stop-loss.
To reduce this risk, the safety_margin value is applied.
White: auto_leverage * safety_margin
First Green: Investment = Maximum Risk / (manual_SL / 100) / optimization_LEVER
Second Green: Maximum Risk * (manual_SL / 100)
First Red: manual_SL.
Second Red: manual_SL * optimization_LEVER
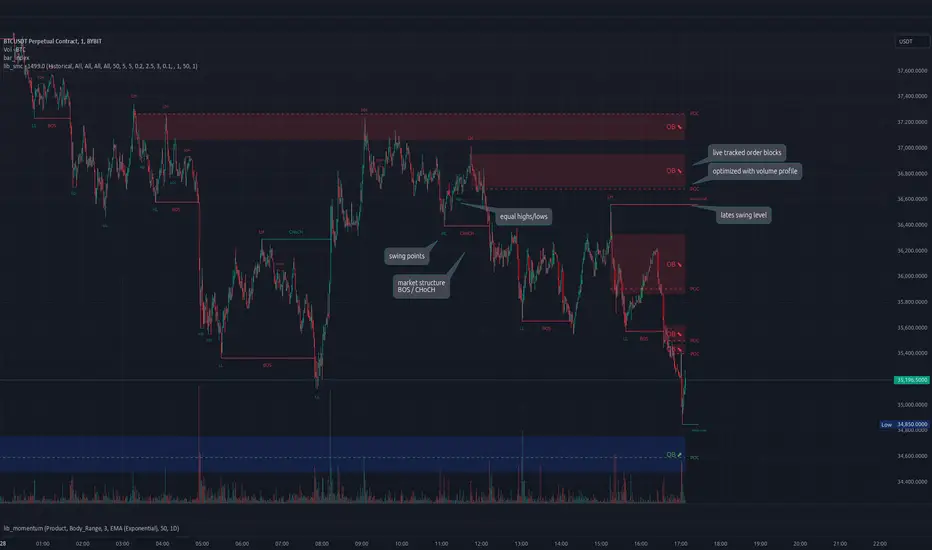
lib_smcLibrary "lib_smc"
This is an adaptation of LuxAlgo's Smart Money Concepts indicator with numerous changes. Main changes include integration of object based plotting, plenty of performance improvements, live tracking of Order Blocks, integration of volume profiles to refine Order Blocks, and many more.
This is a library for developers, if you want this converted into a working strategy, let me know.
buffer(item, len, force_rotate)
Parameters:
item (float)
len (int)
force_rotate (bool)
buffer(item, len, force_rotate)
Parameters:
item (int)
len (int)
force_rotate (bool)
buffer(item, len, force_rotate)
Parameters:
item (Profile type from robbatt/lib_profile/32)
len (int)
force_rotate (bool)
swings(len)
INTERNAL: detect swing points (HH and LL) in given range
Parameters:
len (simple int) : range to check for new swing points
Returns: values are the price level where and if a new HH or LL was detected, else na
method init(this)
Namespace types: OrderBlockConfig
Parameters:
this (OrderBlockConfig)
method delete(this)
Namespace types: OrderBlock
Parameters:
this (OrderBlock)
method clear_broken(this, broken_buffer)
INTERNAL: delete internal order blocks box coordinates if top/bottom is broken
Namespace types: map
Parameters:
this (map)
broken_buffer (map)
Returns: any_bull_ob_broken, any_bear_ob_broken, broken signals are true if an according order block was broken/mitigated, broken contains the broken block(s)
create_ob(id, mode, start_t, start_i, top, end_t, end_i, bottom, break_price, early_confirmation_price, config, init_plot, force_overlay)
INTERNAL: set internal order block coordinates
Parameters:
id (int)
mode (int) : 1: bullish, -1 bearish block
start_t (int)
start_i (int)
top (float)
end_t (int)
end_i (int)
bottom (float)
break_price (float)
early_confirmation_price (float)
config (OrderBlockConfig)
init_plot (bool)
force_overlay (bool)
Returns: signals are true if an according order block was broken/mitigated
method align_to_profile(block, align_edge, align_break_price)
Namespace types: OrderBlock
Parameters:
block (OrderBlock)
align_edge (bool)
align_break_price (bool)
method create_profile(block, opens, tops, bottoms, closes, values, resolution, vah_pc, val_pc, args, init_calculated, init_plot, force_overlay)
Namespace types: OrderBlock
Parameters:
block (OrderBlock)
opens (array)
tops (array)
bottoms (array)
closes (array)
values (array)
resolution (int)
vah_pc (float)
val_pc (float)
args (ProfileArgs type from robbatt/lib_profile/32)
init_calculated (bool)
init_plot (bool)
force_overlay (bool)
method create_profile(block, resolution, vah_pc, val_pc, args, init_calculated, init_plot, force_overlay)
Namespace types: OrderBlock
Parameters:
block (OrderBlock)
resolution (int)
vah_pc (float)
val_pc (float)
args (ProfileArgs type from robbatt/lib_profile/32)
init_calculated (bool)
init_plot (bool)
force_overlay (bool)
track_obs(swing_len, hh, ll, top, btm, bull_bos_alert, bull_choch_alert, bear_bos_alert, bear_choch_alert, min_block_size, max_block_size, config_bull, config_bear, init_plot, force_overlay, enabled, extend_blocks, clear_broken_buffer_before, align_edge_to_value_area, align_break_price_to_poc, profile_args_bull, profile_args_bear, use_soft_confirm, soft_confirm_offset, use_retracements_with_FVG_out)
Parameters:
swing_len (int)
hh (float)
ll (float)
top (float)
btm (float)
bull_bos_alert (bool)
bull_choch_alert (bool)
bear_bos_alert (bool)
bear_choch_alert (bool)
min_block_size (float)
max_block_size (float)
config_bull (OrderBlockConfig)
config_bear (OrderBlockConfig)
init_plot (bool)
force_overlay (bool)
enabled (bool)
extend_blocks (simple bool)
clear_broken_buffer_before (simple bool)
align_edge_to_value_area (simple bool)
align_break_price_to_poc (simple bool)
profile_args_bull (ProfileArgs type from robbatt/lib_profile/32)
profile_args_bear (ProfileArgs type from robbatt/lib_profile/32)
use_soft_confirm (simple bool)
soft_confirm_offset (float)
use_retracements_with_FVG_out (simple bool)
method draw(this, config, extend_only)
Namespace types: OrderBlock
Parameters:
this (OrderBlock)
config (OrderBlockConfig)
extend_only (bool)
method draw(blocks, config)
INTERNAL: plot order blocks
Namespace types: array
Parameters:
blocks (array)
config (OrderBlockConfig)
method draw(blocks, config)
INTERNAL: plot order blocks
Namespace types: map
Parameters:
blocks (map)
config (OrderBlockConfig)
method cleanup(this, ob_bull, ob_bear)
removes all Profiles that are older than the latest OrderBlock from this profile buffer
Namespace types: array
Parameters:
this (array type from robbatt/lib_profile/32)
ob_bull (OrderBlock)
ob_bear (OrderBlock)
_plot_swing_points(mode, x, y, show_swing_points, linecolor_swings, keep_history, show_latest_swings_levels, trail_x, trail_y, trend)
INTERNAL: plot swing points
Parameters:
mode (int) : 1: bullish, -1 bearish block
x (int) : x-coordingate of swing point to plot (bar_index)
y (float) : y-coordingate of swing point to plot (price)
show_swing_points (bool) : switch to enable/disable plotting of swing point labels
linecolor_swings (color) : color for swing point labels and lates level lines
keep_history (bool) : weater to remove older swing point labels and only keep the most recent
show_latest_swings_levels (bool)
trail_x (int) : x-coordinate for latest swing point (bar_index)
trail_y (float) : y-coordinate for latest swing point (price)
trend (int) : the current trend 1: bullish, -1: bearish, to determine Strong/Weak Low/Highs
_pivot_lvl(mode, trend, hhll_x, hhll, super_hhll, filter_insignificant_internal_breaks)
INTERNAL: detect whether a structural level has been broken and if it was in trend direction (BoS) or against trend direction (ChoCh), also track the latest high and low swing points
Parameters:
mode (simple int) : detect 1: bullish, -1 bearish pivot points
trend (int) : current trend direction
hhll_x (int) : x-coordinate of newly detected hh/ll (bar_index)
hhll (float) : y-coordinate of newly detected hh/ll (price)
super_hhll (float) : level/y-coordinate of superior hhll (if this is an internal structure pivot level)
filter_insignificant_internal_breaks (bool) : if true pivot points / internal structure will be ignored where the wick in trend direction is longer than the opposite (likely to push further in direction of main trend)
Returns: coordinates of internal structure that has been broken (x,y): start of structure, (trail_x, trail_y): tracking hh/ll after structure break, (bos_alert, choch_alert): signal whether a structural level has been broken
_plot_structure(x, y, is_bos, is_choch, line_color, line_style, label_style, label_size, keep_history)
INTERNAL: plot structural breaks (BoS/ChoCh)
Parameters:
x (int) : x-coordinate of newly broken structure (bar_index)
y (float) : y-coordinate of newly broken structure (price)
is_bos (bool) : whether this structural break was in trend direction
is_choch (bool) : whether this structural break was against trend direction
line_color (color) : color for the line connecting the structural level and the breaking candle
line_style (string) : style (line.style_dashed/solid) for the line connecting the structural level and the breaking candle
label_style (string) : style (label.style_label_down/up) for the label above/below the line connecting the structural level and the breaking candle
label_size (string) : size (size.small/tiny) for the label above/below the line connecting the structural level and the breaking candle
keep_history (bool) : weater to remove older swing point labels and only keep the most recent
structure_values(length, super_hh, super_ll, filter_insignificant_internal_breaks)
detect (and plot) structural breaks and the resulting new trend
Parameters:
length (simple int) : lookback period for swing point detection
super_hh (float) : level/y-coordinate of superior hh (for internal structure detection)
super_ll (float) : level/y-coordinate of superior ll (for internal structure detection)
filter_insignificant_internal_breaks (bool) : if true pivot points / internal structure will be ignored where the wick in trend direction is longer than the opposite (likely to push further in direction of main trend)
Returns: trend: direction 1:bullish -1:bearish, (bull_bos_alert, bull_choch_alert, top_x, top_y, trail_up_x, trail_up): whether and which level broke in a bullish direction, trailing high, (bbear_bos_alert, bear_choch_alert, tm_x, btm_y, trail_dn_x, trail_dn): same in bearish direction
structure_plot(trend, bull_bos_alert, bull_choch_alert, top_x, top_y, trail_up_x, trail_up, hh, bear_bos_alert, bear_choch_alert, btm_x, btm_y, trail_dn_x, trail_dn, ll, color_bull, color_bear, show_swing_points, show_latest_swings_levels, show_bos, show_choch, line_style, label_size, keep_history)
detect (and plot) structural breaks and the resulting new trend
Parameters:
trend (int) : crrent trend 1: bullish, -1: bearish
bull_bos_alert (bool) : if there was a bullish bos alert -> plot it
bull_choch_alert (bool) : if there was a bullish choch alert -> plot it
top_x (int) : latest shwing high x
top_y (float) : latest swing high y
trail_up_x (int) : trailing high x
trail_up (float) : trailing high y
hh (float) : if there was a higher high
bear_bos_alert (bool) : if there was a bearish bos alert -> plot it
bear_choch_alert (bool) : if there was a bearish chock alert -> plot it
btm_x (int) : latest swing low x
btm_y (float) : latest swing low y
trail_dn_x (int) : trailing low x
trail_dn (float) : trailing low y
ll (float) : if there was a lower low
color_bull (color) : color for bullish BoS/ChoCh levels
color_bear (color) : color for bearish BoS/ChoCh levels
show_swing_points (bool) : whether to plot swing point labels
show_latest_swings_levels (bool) : whether to track and plot latest swing point levels with lines
show_bos (bool) : whether to plot BoS levels
show_choch (bool) : whether to plot ChoCh levels
line_style (string) : whether to plot BoS levels
label_size (string) : label size of plotted BoS/ChoCh levels
keep_history (bool) : weater to remove older swing point labels and only keep the most recent
structure(length, color_bull, color_bear, super_hh, super_ll, filter_insignificant_internal_breaks, show_swing_points, show_latest_swings_levels, show_bos, show_choch, line_style, label_size, keep_history, enabled)
detect (and plot) structural breaks and the resulting new trend
Parameters:
length (simple int) : lookback period for swing point detection
color_bull (color) : color for bullish BoS/ChoCh levels
color_bear (color) : color for bearish BoS/ChoCh levels
super_hh (float) : level/y-coordinate of superior hh (for internal structure detection)
super_ll (float) : level/y-coordinate of superior ll (for internal structure detection)
filter_insignificant_internal_breaks (bool) : if true pivot points / internal structure will be ignored where the wick in trend direction is longer than the opposite (likely to push further in direction of main trend)
show_swing_points (bool) : whether to plot swing point labels
show_latest_swings_levels (bool) : whether to track and plot latest swing point levels with lines
show_bos (bool) : whether to plot BoS levels
show_choch (bool) : whether to plot ChoCh levels
line_style (string) : whether to plot BoS levels
label_size (string) : label size of plotted BoS/ChoCh levels
keep_history (bool) : weater to remove older swing point labels and only keep the most recent
enabled (bool)
_check_equal_level(mode, len, eq_threshold, enabled)
INTERNAL: detect equal levels (double top/bottom)
Parameters:
mode (int) : detect 1: bullish/high, -1 bearish/low pivot points
len (int) : lookback period for equal level (swing point) detection
eq_threshold (float) : maximum price offset for a level to be considered equal
enabled (bool)
Returns: eq_alert whether an equal level was detected and coordinates of the first and the second level/swing point
_plot_equal_level(show_eq, x1, y1, x2, y2, label_txt, label_style, label_size, line_color, line_style, keep_history)
INTERNAL: plot equal levels (double top/bottom)
Parameters:
show_eq (bool) : whether to plot the level or not
x1 (int) : x-coordinate of the first level / swing point
y1 (float) : y-coordinate of the first level / swing point
x2 (int) : x-coordinate of the second level / swing point
y2 (float) : y-coordinate of the second level / swing point
label_txt (string) : text for the label above/below the line connecting the equal levels
label_style (string) : style (label.style_label_down/up) for the label above/below the line connecting the equal levels
label_size (string) : size (size.tiny) for the label above/below the line connecting the equal levels
line_color (color) : color for the line connecting the equal levels (and it's label)
line_style (string) : style (line.style_dotted) for the line connecting the equal levels
keep_history (bool) : weater to remove older swing point labels and only keep the most recent
equal_levels_values(len, threshold, enabled)
detect (and plot) equal levels (double top/bottom), returns coordinates
Parameters:
len (int) : lookback period for equal level (swing point) detection
threshold (float) : maximum price offset for a level to be considered equal
enabled (bool) : whether detection is enabled
Returns: (eqh_alert, eqh_x1, eqh_y1, eqh_x2, eqh_y2) whether an equal high was detected and coordinates of the first and the second level/swing point, (eql_alert, eql_x1, eql_y1, eql_x2, eql_y2) same for equal lows
equal_levels_plot(eqh_x1, eqh_y1, eqh_x2, eqh_y2, eql_x1, eql_y1, eql_x2, eql_y2, color_eqh, color_eql, show, keep_history)
detect (and plot) equal levels (double top/bottom), returns coordinates
Parameters:
eqh_x1 (int) : coordinates of first point of equal high
eqh_y1 (float) : coordinates of first point of equal high
eqh_x2 (int) : coordinates of second point of equal high
eqh_y2 (float) : coordinates of second point of equal high
eql_x1 (int) : coordinates of first point of equal low
eql_y1 (float) : coordinates of first point of equal low
eql_x2 (int) : coordinates of second point of equal low
eql_y2 (float) : coordinates of second point of equal low
color_eqh (color) : color for the line connecting the equal highs (and it's label)
color_eql (color) : color for the line connecting the equal lows (and it's label)
show (bool) : whether plotting is enabled
keep_history (bool) : weater to remove older swing point labels and only keep the most recent
Returns: (eqh_alert, eqh_x1, eqh_y1, eqh_x2, eqh_y2) whether an equal high was detected and coordinates of the first and the second level/swing point, (eql_alert, eql_x1, eql_y1, eql_x2, eql_y2) same for equal lows
equal_levels(len, threshold, color_eqh, color_eql, enabled, show, keep_history)
detect (and plot) equal levels (double top/bottom)
Parameters:
len (int) : lookback period for equal level (swing point) detection
threshold (float) : maximum price offset for a level to be considered equal
color_eqh (color) : color for the line connecting the equal highs (and it's label)
color_eql (color) : color for the line connecting the equal lows (and it's label)
enabled (bool) : whether detection is enabled
show (bool) : whether plotting is enabled
keep_history (bool) : weater to remove older swing point labels and only keep the most recent
Returns: (eqh_alert) whether an equal high was detected, (eql_alert) same for equal lows
_detect_fvg(mode, enabled, o, h, l, c, filter_insignificant_fvgs, change_tf)
INTERNAL: detect FVG (fair value gap)
Parameters:
mode (int) : detect 1: bullish, -1 bearish gaps
enabled (bool) : whether detection is enabled
o (float) : reference source open
h (float) : reference source high
l (float) : reference source low
c (float) : reference source close
filter_insignificant_fvgs (bool) : whether to calculate and filter small/insignificant gaps
change_tf (bool) : signal when the previous reference timeframe closed, triggers new calculation
Returns: whether a new FVG was detected and its top/mid/bottom levels
_clear_broken_fvg(mode, upper_boxes, lower_boxes)
INTERNAL: clear mitigated FVGs (fair value gaps)
Parameters:
mode (int) : detect 1: bullish, -1 bearish gaps
upper_boxes (array) : array that stores the upper parts of the FVG boxes
lower_boxes (array) : array that stores the lower parts of the FVG boxes
_plot_fvg(mode, show, top, mid, btm, border_color, extend_box)
INTERNAL: plot (and clear broken) FVG (fair value gap)
Parameters:
mode (int) : plot 1: bullish, -1 bearish gap
show (bool) : whether plotting is enabled
top (float) : top level of fvg
mid (float) : center level of fvg
btm (float) : bottom level of fvg
border_color (color) : color for the FVG box
extend_box (int) : how many bars into the future the FVG box should be extended after detection
fvgs_values(o, h, l, c, filter_insignificant_fvgs, change_tf, enabled)
detect (and plot / clear broken) FVGs (fair value gaps), and return alerts and level values
Parameters:
o (float) : reference source open
h (float) : reference source high
l (float) : reference source low
c (float) : reference source close
filter_insignificant_fvgs (bool) : whether to calculate and filter small/insignificant gaps
change_tf (bool) : signal when the previous reference timeframe closed, triggers new calculation
enabled (bool) : whether detection is enabled
Returns: (bullish_fvg_alert, bull_top, bull_mid, bull_btm): whether a new bullish FVG was detected and its top/mid/bottom levels, (bearish_fvg_alert, bear_top, bear_mid, bear_btm): same for bearish FVGs
fvgs_plot(bullish_fvg_alert, bull_top, bull_mid, bull_btm, bearish_fvg_alert, bear_top, bear_mid, bear_btm, color_bull, color_bear, extend_box, show)
Parameters:
bullish_fvg_alert (bool)
bull_top (float)
bull_mid (float)
bull_btm (float)
bearish_fvg_alert (bool)
bear_top (float)
bear_mid (float)
bear_btm (float)
color_bull (color) : color for bullish FVG boxes
color_bear (color) : color for bearish FVG boxes
extend_box (int) : how many bars into the future the FVG box should be extended after detection
show (bool) : whether plotting is enabled
Returns: (bullish_fvg_alert, bull_top, bull_mid, bull_btm): whether a new bullish FVG was detected and its top/mid/bottom levels, (bearish_fvg_alert, bear_top, bear_mid, bear_btm): same for bearish FVGs
fvgs(o, h, l, c, filter_insignificant_fvgs, change_tf, color_bull, color_bear, extend_box, enabled, show)
detect (and plot / clear broken) FVGs (fair value gaps)
Parameters:
o (float) : reference source open
h (float) : reference source high
l (float) : reference source low
c (float) : reference source close
filter_insignificant_fvgs (bool) : whether to calculate and filter small/insignificant gaps
change_tf (bool) : signal when the previous reference timeframe closed, triggers new calculation
color_bull (color) : color for bullish FVG boxes
color_bear (color) : color for bearish FVG boxes
extend_box (int) : how many bars into the future the FVG box should be extended after detection
enabled (bool) : whether detection is enabled
show (bool) : whether plotting is enabled
Returns: (bullish_fvg_alert): whether a new bullish FVG was detected, (bearish_fvg_alert): same for bearish FVGs
OrderBlock
Fields:
id (series int)
dir (series int)
left_top (chart.point)
right_bottom (chart.point)
break_price (series float)
early_confirmation_price (series float)
ltf_high (array)
ltf_low (array)
ltf_volume (array)
plot (Box type from robbatt/lib_plot_objects/49)
profile (Profile type from robbatt/lib_profile/32)
trailing (series bool)
extending (series bool)
awaiting_confirmation (series bool)
touched_break_price_before_confirmation (series bool)
soft_confirmed (series bool)
has_fvg_out (series bool)
hidden (series bool)
broken (series bool)
OrderBlockConfig
Fields:
show (series bool)
show_last (series int)
show_id (series bool)
show_profile (series bool)
args (BoxArgs type from robbatt/lib_plot_objects/49)
txt (series string)
txt_args (BoxTextArgs type from robbatt/lib_plot_objects/49)
delete_when_broken (series bool)
broken_args (BoxArgs type from robbatt/lib_plot_objects/49)
broken_txt (series string)
broken_txt_args (BoxTextArgs type from robbatt/lib_plot_objects/49)
broken_profile_args (ProfileArgs type from robbatt/lib_profile/32)
use_profile (series bool)
profile_args (ProfileArgs type from robbatt/lib_profile/32)
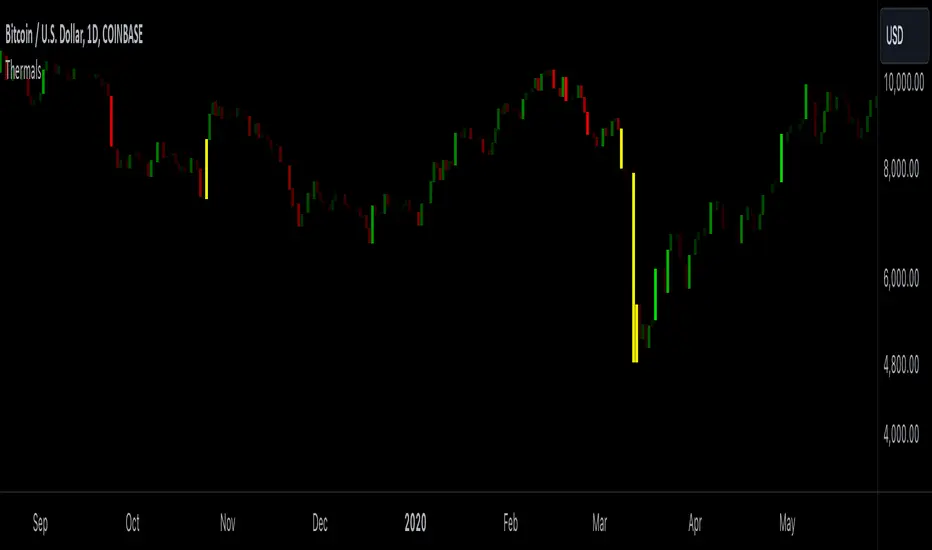
Candle ThermalsThis indicator color candles based on their percentage price change, relative to the average, maximum, and minimum changes over the last 100 candles.
-It calculates the percentage change of all candles
-Calculates the minimum, maximum and average in the last 100 bars in percentage change
-Changes color of the candle based on the range between the current percent and min/max value
-The brightest candle provides the highest compound effect to you account if you act on it at the open.
-Candles that have a percentage close to the average then they are barely visible = lowest compound effect to your account
This indicator functions like a "heatmap" for candles, highlighting the relative volatility of price movements in both directions. Strong bullish candles are brighter green, and strong bearish candles are brighter red. It's particularly useful for traders wanting quick visual feedback on price volatility and strength trends within the last 100 bars.
Volatility-Adjusted Trend Deviation Statistics (C-Ratios)The Pine Script logic provided generates and displays a table with key information derived from VWMA, EMA, and ATR-based "C Ratios," alongside stochastic oscillators, correlation coefficients, Z-scores, and bias indicators. Here’s an explanation of the logic and what the output in the table informs:
Key Calculations and Their Purpose
VWMA and EMA (Smoothing Lengths):
Multiple EMAs are calculated using VWMA as the source, with lengths spanning short-term (13) to long-term (233).
These EMAs provide a hierarchy of smoothed price levels to assess trends over various time horizons.
ATR-Based "C Ratios":
The C Ratios measure deviations of smoothed prices (a_1 to a_7) from the source price relative to ATR at corresponding lengths.
These values normalize deviations, giving insight into the price's relative movement strength and direction over various periods.
Stochastic Oscillator for C Ratios:
Calculates normalized stochastic values for each C Ratio to assess overbought/oversold conditions dynamically over a rolling window.
Helps identify short-term momentum trends within the broader context of C Ratios.
Displays the average stochastic value derived from all C Ratios.
Text: Shows overbought/oversold conditions (Overbought, Oversold, or ---).
Color: Green for strong upward momentum, red for downward, and white for neutral.
Weighted and Mean C Ratio:
The script computes both an arithmetic mean (c_mean) and a weighted mean (c_mean_w) for all C Ratios.
Weighted mean emphasizes short-term values using predefined weights.
Trend Bias and Reversal Detection:
The script calculates Z-scores for c_mean to identify statistically significant deviations.
It combines Z-scores and weighted C Ratio values to determine:
Bias (Bullish/Bearish based on Z-score thresholds and mean values).
Reversals (Based on relative positioning and how the weighted c_mean and un-weighted C_mean move. ).
Correlation Coefficient:
Correlation of mean C Ratios (c_mean) with bar indices over the short-term length (sl) assesses the strength and direction of trend consistency.
Table Output and Its Meaning
Stochastic Strength:
Long-term Correlation:
List of Lengths: Define the list of lengths for EMA and ATR explicitly (e.g., ).
Calculate Mean C Ratios: For each length in the list, calculate the mean C Ratio
Average these values over the entire dataset.
Store Lengths and Mean C Ratios: Maintain arrays for lengths and their corresponding mean C Ratios.
Correlation: compute the Pearson correlation between the list of lengths and the mean C Ratios.
Text: Indicates Uptrend, Downtrend, or neutral (---).
Color: Green for positive (uptrend), red for negative (downtrend), and white for neutral.
Z-Score Bias:
Assesses the statistical deviation of C Ratios from their historical mean.
Text: Bullish Bias, Bearish Bias, or --- (neutral).
Color: Green or red based on the direction and significance of the Z-score.
C-Ratio Mean:
Displays the weighted average C Ratio (c_mean_w) or a reversal condition.
Text: If no reversal is detected, shows c_mean_w; otherwise, a reversal condition (Bullish Reversal, Bearish Reversal).
Color: Indicates the strength and direction of the bias or reversal.
Practical Insights
Trend Identification: Correlation coefficients, Z-scores, and stochastic values collectively highlight whether the market is trending and the trend's direction.
Momentum and Volatility: Stochastic and ATR-normalized C Ratios provide insights into the momentum and price movement consistency across different timeframes.
Bias and Reversal Detection: The script highlights potential shifts in market sentiment or direction (bias or reversal) using statistical measures.
Customization: Users can toggle plots and analyze specific EMA lengths or focus on combined metrics like the weighted C Ratio.

BacktestLibraryLibrary "BacktestLibrary"
A library providing functions for equity calculation and performance metrics.
since(date, active)
: Calculates the number of candles since a specified date.
Parameters:
date (simple float) : (simple float): The starting date in timestamp format (e.g., input.time(timestamp()))
active (simple bool) : (simple bool): If true, counts the number of candles since the date; if false, returns 0.
Returns: (int): The number of candles since the specified date.
buy_and_hold(r, startDate)
: Calculates the Buy and Hold Equity from a specified date.
Parameters:
r (float) : (series float): Daily returns of the asset (e.g., 0.02 for 2% move).
startDate (simple float) : (simple float): Timestamp of the starting date for the equity calculation.
Returns: (float): Buy and Hold Equity of the asset from the specified date.
equity(sig, threshold, r, startDate, signals)
: Calculates the strategy's equity on a candle-by-candle basis.
Parameters:
sig (float) : (series float): Signal values; positive for long, negative for short.
threshold (simple float) : (simple float): Signal threshold for entering trades.
r (float) : (series float): Daily returns of the asset (e.g., 0.02 for 2% move).
startDate (simple float) : (simple float): Timestamp of the starting date for the equity calculation.
signals (simple string) : (simple string): Type of signals to backtest ("Long & Short", "Long Only", "Short Only").
Returns: (float): Strategy equity on a candle-by-candle basis.
PerformanceMetrics(base, Lookback, startDate)
: Calculates performance metrics of a strategy from a specified date.
Parameters:
base (float) : (series float): Equity values of the strategy or Buy and Hold equity.
Lookback (int) : (series int): Number of periods since the start date; recommended to use the 'since' function.
startDate (simple float) : (simple float): Timestamp of the starting date for the equity calculation.
Returns: (float ): Array of performance metrics.
PerfMetricTable(buy_and_hold, strategy)
: Plots a table comparing performance metrics of Buy and Hold and Strategy equity.
Parameters:
buy_and_hold (array) : (float ): Metrics from the PerformanceMetrics() function for Buy and Hold.
strategy (array) : (float ): Metrics from the PerformanceMetrics() function for the strategy.
Returns: : Table displaying the performance metrics comparison.

Portfolio [Afnan]🚀 Portfolio - Advanced Portfolio Management Indicator 📊
A game-changing portfolio management tool designed to help traders stay on top of their positions and manage risk efficiently. This indicator combines detailed tracking, real-time analytics, and visual clarity to ensure traders are well-equipped for the dynamic world of financial markets.
📈 Key Features 💡
Track up to 14 positions with ease
Real-time Profit & Loss (P&L) updates and risk metrics
Visual representation of entry, stop-loss (SL), and target levels
Alerts for stop-loss breaches and target achievements
Comprehensive portfolio summaries for quick analysis
Customizable options to suit individual trading styles
🔍 Main Components ⚙️
📊 1. Position Tracking
Detailed position data: entry, stop-loss, target levels, and more
Real-time risk-reward ratios
Insights into position size and exposure percentages
Continuous updates on P&L in real-time
📉 2. Visual Indicators
Clear visual markers for entry, SL, and target prices
Price labels with detailed percentage changes
Indicators that show the current position's market status
💼 3. Portfolio Summary
Aggregate account values and exposure
Summarized P&L metrics across all positions
Risk management insights for better decision-making
Daily performance tracking to evaluate strategies
⚠️ 4. Alert System
Instant notifications for stop-loss breaches
Alerts when target prices are hit
Alerts operate for the current chart symbol
⚡ Customization Options 🎨
Show or hide specific data columns
Adjust the table's position and size for better visibility
Personalize color schemes and text styles
Switch between full portfolio view and single symbol focus
📱 How to Use 📝
Input your positions in the indicator's settings
Enable or disable specific positions dynamically
Customize display preferences to your liking
Set up alerts for proactive risk management
Monitor all your trading activities in one comprehensive dashboard
📌 Important Notes ℹ️
Compatible with any trading symbol
Updates seamlessly during market hours
Alerts are specific to the currently active chart symbol
Maximum capacity: 14 simultaneous positions
Created by: @AfnanTAjuddin
⚠️ Disclaimer ⚠️
This indicator is a tool for informational purposes only. Ensure all calculations are verified and consult a financial professional before making investment decisions.
🎯 "Stay disciplined, trade smart, and let data guide your decisions." 📊

ArrayMovingAveragesLibrary "ArrayMovingAverages"
This library adds several moving average methods to arrays, so you can call, eg.:
myArray.ema(3)
method emaArray(id, length)
Calculate Exponential Moving Average (EMA) for Arrays
Namespace types: array
Parameters:
id (array) : (array) Input array
length (int) : (int) Length of the EMA
Returns: (array) Array of EMA values
method ema(id, length)
Get the last value of the EMA array
Namespace types: array
Parameters:
id (array) : (array) Input array
length (int) : (int) Length of the EMA
Returns: (float) Last EMA value or na if empty
method rmaArray(id, length)
Calculate Rolling Moving Average (RMA) for Arrays
Namespace types: array
Parameters:
id (array) : (array) Input array
length (int) : (int) Length of the RMA
Returns: (array) Array of RMA values
method rma(id, length)
Get the last value of the RMA array
Namespace types: array
Parameters:
id (array) : (array) Input array
length (int) : (int) Length of the RMA
Returns: (float) Last RMA value or na if empty
method smaArray(id, windowSize)
Calculate Simple Moving Average (SMA) for Arrays
Namespace types: array
Parameters:
id (array) : (array) Input array
windowSize (int) : (int) Window size for calculation, defaults to array size
Returns: (array) Array of SMA values
method sma(id, windowSize)
Get the last value of the SMA array
Namespace types: array
Parameters:
id (array) : (array) Input array
windowSize (int) : (int) Window size for calculation, defaults to array size
Returns: (float) Last SMA value or na if empty
method wmaArray(id, windowSize)
Calculate Weighted Moving Average (WMA) for Arrays
Namespace types: array
Parameters:
id (array) : (array) Input array
windowSize (int) : (int) Window size for calculation, defaults to array size
Returns: (array) Array of WMA values
method wma(id, windowSize)
Get the last value of the WMA array
Namespace types: array
Parameters:
id (array) : (array) Input array
windowSize (int) : (int) Window size for calculation, defaults to array size
Returns: (float) Last WMA value or na if empty

Quick scan for signal🙏🏻 Hey TV, this is QSFS, following:
^^ Quick scan for drift (QSFD)
^^ Quick scan for cycles (QSFC)
As mentioned before, ML trading is all about spotting any kind of non-randomness, and this metric (along with 2 previously posted) gonna help ya'll do it fast. This one will show you whether your time series possibly exhibits mean-reverting / consistent / noisy behavior, that can be later confirmed or denied by more sophisticated tools. This metric is O(n) in windowed mode and O(1) if calculated incrementally on each data update, so you can scan Ks of datasets w/o worrying about melting da ice.
^^ windowed mode
Now the post will be divided into several sections, and a couple of things I guess you’ve never seen or thought about in your life:
1) About Efficiency Ratios posted there on TV;
Some of you might say this is the Efficiency Ratio you’ve seen in Perry's book. Firstly, I can assure you that neither me nor Perry, just as X amount of quants all over the world and who knows who else, would say smth like, "I invented it," lol. This is just a thing you R&D when you need it. Secondly, I invite you (and mods & admin as well) to take a lil glimpse at the following screenshot:
^^ not cool...
So basically, all the Efficiency Ratios that were copypasted to our platform suffer the same bug: dudes don’t know how indexing works in Pine Script. I mean, it’s ok, I been doing the same mistakes as well, but loxx, cmon bro, you... If you guys ever read it, the lines 20 and 22 in da code are dedicated to you xD
2) About the metric;
This supports both moving window mode when Length > 0 and all-data expanding window mode when Length < 1, calculating incrementally from the very first data point in the series: O(n) on history, O(1) on live updates.
Now, why do I SQRT transform the result? This is a natural action since the metric (being a ratio in essence) is bounded between 0 and 1, so it can be modeled with a beta distribution. When you SQRT transform it, it still stays beta (think what happens when you apply a square root to 0.01 or 0.99), but it becomes symmetric around its typical value and starts to follow a bell-shaped curve. This can be easily checked with a normality test or by applying a set of percentiles and seeing the distances between them are almost equal.
Then I noticed that on different moving window sizes, the typical value of the metric seems to slide: higher window sizes lead to lower typical values across the moving windows. Turned out this can be modeled the same way confidence intervals are made. Lines 34 and 35 explain it all, I guess. You can see smth alike on an autocorrelogram. These two match the mean & mean + 1 stdev applied to the metric. This way, we’ve just magically received data to estimate alpha and beta parameters of the beta distribution using the method of moments. Having alpha and beta, we can now estimate everything further. Btw, there’s an alternative parameterization for beta distributions based on data length.
Now what you’ll see next is... u guys actually have no idea how deep and unrealistically minimalistic the underlying math principles are here.
I’m sure I’m not the only one in the universe who figured it out, but the thing is, it’s nowhere online or offline. By calculating higher-order moments & combining them, you can find natural adaptive thresholds that can later be used for anomaly detection/control applications for any data. No hardcoded thresholds, purely data-driven. Imma come back to this in one of the next drops, but the truest ones can already see it in this code. This way we get dem thresholds.
Your main thresholds are: basis, upper, and lower deviations. You can follow the common logic I’ve described in my previous scripts on how to use them. You just register an event when the metric goes higher/lower than a certain threshold based on what you’re looking for. Then you take the time series and confirm a certain behavior you were looking for by using an appropriate stat test. Or just run a certain strategy.
To avoid numerous triggers when the metric jitters around a threshold, you can follow this logic: forget about one threshold if touched, until another threshold is touched.
In general, when the metric gets higher than certain thresholds, like upper deviation, it means the signal is stronger than noise. You confirm it with a more sophisticated tool & run momentum strategies if drift is in place, or volatility strategies if there’s no drift in place. Otherwise, you confirm & run ~ mean-reverting strategies, regardless of whether there’s drift or not. Just don’t operate against the trend—hedge otherwise.
3) Flex;
Extension and limit thresholds based on distribution moments gonna be discussed properly later, but now you can see this:
^^ magic
Look at the thresholds—adaptive and dynamic. Do you see any optimizations? No ML, no DL, closed-form solution, but how? Just a formula based on a couple of variables? Maybe it’s just how the Universe works, but how can you know if you don’t understand how fundamentally numbers 3 and 15 are related to the normal distribution? Hm, why do they always say 3 sigmas but can’t say why? Maybe you can be different and say why?
This is the primordial power of statistical modeling.
4) Thanks;
I really wanna dedicate this to Charlotte de Witte & Marion Di Napoli, and their new track "Sanctum." It really gets you connected to the Source—I had it in my soul when I was doing all this ∞

MTF ADX TableThis Indicator displays a table on the chart with the Average Directional Index (ADX) values for two different timeframes. It calculates the ADX using a custom formula and shows the ADX values along with their corresponding timeframes. The table's position, font size, and background color can be customized, and the timeframes are labeled with "ADX" appended to their unit (e.g., "5m ADX", "1D ADX"). The table updates dynamically with the latest ADX values for each timeframe. The indicator also provides a rating, based of the thresholds settings

BTC vs Altcoin CorrelationThis Pine Script indicator calculates and visualizes the rolling correlation between Bitcoin (BTC) and a selected altcoin, while providing insights into the percentage of time the correlation remains above a user-defined threshold. Users can independently configure the correlation calculation period and the lookback period for measuring the percentage of time above the threshold. The correlation is displayed as a color-coded line: green when above the threshold and red otherwise, with a dashed horizontal line marking the threshold level. A dynamic table displays the current correlation value and the percentage of time spent above the threshold within the specified period, enabling quick evaluation of correlation dynamics between BTC and the chosen altcoin.

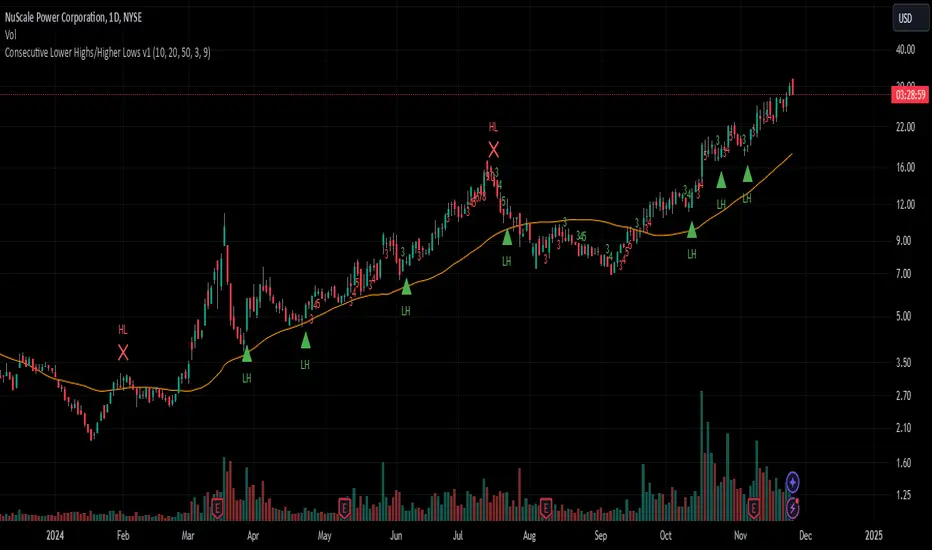
Consecutive Lower Highs/Higher Lows v1 [tradinggeniusberlin]This indicator counts the lower highs and higher low streaks. If the streak is above a certain threshold a buy or exit arrow is shown.
Idea:
The probability of a reversal is rising the more lower highs the asset had already because if mean reversion tendencies of asset prices. Especially in uptrend above the 20ma and/or 50ma.
How to use it:
In Uptrends, lower high streak of 3 or more, enter at first new high.
Daily PlayDaily Play Indicator
The Daily Play Indicator is a clean and versatile tool designed to help traders organize and execute their daily trading plan directly on their charts. This indicator simplifies your workflow by visually displaying key inputs like market trend, directional bias, and key levels, making it easier to focus on your trading strategy.
Features
Dropdown Selection for Trend and Bias:
• Set the overall market trend (Bullish, Bearish, or Neutral) and your directional bias (Long, Short, or Neutral) using intuitive dropdown menus. No more manual typing or guesswork!
Key Levels:
Quickly input and display the Previous Day High and Previous Day Low. These levels are essential for many trading strategies, such as breakouts.
Real-Time News Notes:
Add a quick note about impactful news or market events (e.g., “Fed meeting today” or “Earnings season”) to keep contextual awareness while trading.
Simple On-Chart Display:
The indicator creates a “table-like” structure on the chart, aligning your inputs in an easy-to-read format. The data is positioned dynamically so it doesn’t obstruct the price action.
Customisable Visual Style:
Simple labels with clear text to ensure that your chart remains neat and tidy.
----
Use Case
The Daily Play Indicator is ideal for:
• Day traders and scalpers who rely on precise planning and real-time execution.
• Swing traders looking to mark critical levels and develop a trade plan before the session begins.
• Anyone who needs a structured way to stay focused and disciplined during volatile market conditions.
By integrating this tool into your workflow, you can easily align your daily preparation with live market action.
----
How to Use
Open the indicator settings to configure your inputs:
• Trend: Use the dropdown to choose between Bullish, Bearish, or Neutral.
• Bias: Select Long, Short, or Neutral to align your personal bias with the market.
• Previous Day Levels: Enter the High and Low of the previous trading session for key reference points.
• News: Add a short description of any relevant market-moving events.

MadTrend [InvestorUnknown]The MadTrend indicator is an experimental tool that combines the Median and Median Absolute Deviation (MAD) to generate signals, much like the popular Supertrend indicator. In addition to identifying Long and Short positions, MadTrend introduces RISK-ON and RISK-OFF states for each trade direction, providing traders with nuanced insights into market conditions.
Core Concepts
Median and Median Absolute Deviation (MAD)
Median: The middle value in a sorted list of numbers, offering a robust measure of central tendency less affected by outliers.
Median Absolute Deviation (MAD): Measures the average distance between each data point and the median, providing a robust estimation of volatility.
Supertrend-like Functionality
MadTrend utilizes the median and MAD in a manner similar to how Supertrend uses averages and volatility measures to determine trend direction and potential reversal points.
RISK-ON and RISK-OFF States
RISK-ON: Indicates favorable conditions for entering or holding a position in the current trend direction.
RISK-OFF: Suggests caution, signaling RISK-ON end and potential trend weakening or reversal.
Calculating MAD
The mad function calculates the median of the absolute deviations from the median, providing a robust measure of volatility.
// Function to calculate the Median Absolute Deviation (MAD)
mad(series float src, simple int length) =>
med = ta.median(src, length) // Calculate median
abs_deviations = math.abs(src - med) // Calculate absolute deviations from median
ta.median(abs_deviations, length) // Return the median of the absolute deviations
MADTrend Function
The MADTrend function calculates the median and MAD-based upper (med_p) and lower (med_m) bands. It determines the trend direction based on price crossing these bands.
MADTrend(series float src, simple int length, simple float mad_mult) =>
// Calculate MAD (volatility measure)
mad_value = mad(close, length)
// Calculate the MAD-based moving average by scaling the price data with MAD
median = ta.median(close, length)
med_p = median + (mad_value * mad_mult)
med_m = median - (mad_value * mad_mult)
var direction = 0
if ta.crossover(src, med_p)
direction := 1
else if ta.crossunder(src, med_m)
direction := -1
Trend Direction and Signals
Long Position (direction = 1): When the price crosses above the upper MAD band (med_p).
Short Position (direction = -1): When the price crosses below the lower MAD band (med_m).
RISK-ON: When the price moves further in the direction of the trend (beyond median +- MAD) after the initial signal.
RISK-OFF: When the price retraces towards the median, signaling potential weakening of the trend.
RISK-ON and RISK-OFF States
RISK-ON LONG: Price moves above the upper band after a Long signal, indicating strengthening bullish momentum.
RISK-OFF LONG: Price falls back below the upper band, suggesting potential weakness in the bullish trend.
RISK-ON SHORT: Price moves below the lower band after a Short signal, indicating strengthening bearish momentum.
RISK-OFF SHORT: Price rises back above the lower band, suggesting potential weakness in the bearish trend.
Picture below show example RISK-ON periods which can be identified by “cloud”
Note: Highlighted areas on the chart indicating RISK-ON and RISK-OFF periods for both Long and Short positions.
Implementation Details
Inputs and Parameters:
Source (input_src): The price data used for calculations (e.g., close, open, high, low).
Median Length (length): The number of periods over which the median and MAD are calculated.
MAD Multiplier (mad_mult): Determines the distance of the upper and lower bands from the median.
Calculations:
Median and MAD are recalculated each period based on the specified length.
Upper (med_p) and Lower (med_m) Bands are computed by adding and subtracting the scaled MAD from the median.
Visual representation of the indicator on a price chart:
Backtesting and Performance Metrics
The MadTrend indicator includes a Backtesting Mode with a performance metrics table to evaluate its effectiveness compared to a simple buy-and-hold strategy.
Equity Calculation:
Calculates the equity curve based on the signals generated by the indicator.
Performance Metrics:
Metrics such as Mean Returns, Standard Deviation, Sharpe Ratio, Sortino Ratio, and Omega Ratio are computed.
The metrics are displayed in a table for both the strategy and the buy-and-hold approach.
Note: Due to the use of labels and plot shapes, automatic chart scaling may not function ideally in Backtest Mode.
Alerts and Notifications
MadTrend provides alert conditions to notify traders of significant events:
Trend Change Alerts
RISK-ON and RISK-OFF Alerts - Provides real-time notifications about the RISK-ON and RISK-OFF states for proactive trade management.
Customization and Calibration
Default Settings: The provided default settings are experimental and not optimized. They serve as a starting point for users.
Parameter Adjustment: Traders are encouraged to calibrate the indicator's parameters (e.g., length, mad_mult) to suit their specific trading style and the characteristics of the asset being analyzed.
Source Input: The indicator allows for different price inputs (open, high, low, close, etc.), offering flexibility in how the median and MAD are calculated.
Important Notes
Market Conditions: The effectiveness of the MadTrend indicator can vary across different market conditions. Regular calibration is recommended.
Backtest Limitations: Backtesting results are historical and do not guarantee future performance.
Risk Management: Always apply sound risk management practices when using any trading indicator.

Mean Price
^^ Plotting switched to Line.
This method of financial time series (aka bars) downsampling is literally, naturally, and thankfully the best you can do in terms of maximizing info gain. You can finally chill and feed it to your studies & eyes, and probably use nothing else anymore.
(HL2 and occ3 also have use cases, but other aggregation methods? Not really, even if they do, the use cases are ‘very’ specific). Tho in order to understand why, you gotta read the following wall, or just believe me telling you, ‘I put it on my momma’.
The true story about trading volumes and why this is all a big misdirection
Actually, you don’t need to be a quant to get there. All you gotta do is stop blindly following other people’s contextual (at best) solutions, eg OC2 aggregation xD, and start using your own brain to figure things out.
Every individual trade (basically an imprint on 1D price space that emerges when market orders hit the order book) has several features like: price, time, volume, AND direction (Up if a market buy order hits the asks, Down if a market sell order hits the bids). Now, the last two features—volume and direction—can be effectively combined into one (by multiplying volume by 1 or -1), and this is probably how every order matching engine should output data. If we’re not considering size/direction, we’re leaving data behind. Moreover, trades aren’t just one-price dots all the time. One trade can consume liquidity on several levels of the order book, so a single trade can be several ticks big on the price axis.
You may think now that there are no zero-volume ticks. Well, yes and no. It depends on how you design an exchange and whether you allow intra-spread trades/mid-spread trades (now try to Google it). Intra-spread trades could happen if implemented when a matching engine receives both buy and sell orders at the same microsecond period. This way, you can match the orders with each other at a better price for both parties without even hitting the book and consuming liquidity. Also, if orders have different sizes, the remaining part of the bigger order can be sent to the order book. Basically, this type of trade can be treated as an OTC trade, having zero volume because we never actually hit the book—there’s no imprint. Another reason why it makes sense is when we think about volume as an impact or imbalance act, and how the medium (order book in our case) responds to it, providing information. OTC and mid-spread trades are not aggressive sells or buys; they’re neutral ticks, so to say. However huge they are, sometimes many blocks on NYSE, they don’t move the price because there’s no impact on the medium (again, which is the order book)—they’re not providing information.
... Now, we need to aggregate these trades into, let’s say, 1-hour bars (remember that a trade can have either positive or negative volume). We either don’t want to do it, or we don’t have this kind of information. What we can do is take already aggregated OHLC bars and extract all the info from them. Given the market is fractal, bars & trades gotta have the same set of features:
- Highest & lowest ticks (high & low) <- by price;
- First & last ticks (open & close) <- by time;
- Biggest and smallest ticks <- by volume.*
*e.g., in the array ,
2323: biggest trade,
-1212: smallest trade.
Now, in our world, somehow nobody started to care about the biggest and smallest trades and their inclusion in OHLC data, while this is actually natural. It’s the same way as it’s done with high & low and open & close: we choose the minimum and maximum value of a given feature/axis within the aggregation period.
So, we don’t have these 2 values: biggest and smallest ticks. The best we can do is infer them, and given the fact the biggest and smallest ticks can be located with the same probability everywhere, all we can do is predict them in the middle of the bar, both in time and price axes. That’s why you can see two HL2’s in each of the 3 formulas in the code.
So, summed up absolute volumes that you see in almost every trading platform are actually just a derivative metric, something that I call Type 2 time series in my own (proprietary ‘for now’) methods. It doesn’t have much to do with market orders hitting the non-uniform medium (aka order book); it’s more like a statistic. Still wanna use VWAP? Ok, but you gotta understand you’re weighting Type 1 (natural) time series by Type 2 (synthetic) ones.
How to combine all the data in the right way (khmm khhm ‘order’)
Now, since we have 6 values for each bar, let’s see what information we have about them, what we don’t have, and what we can do about it:
- Open and close: we got both when and where (time (order) and price);
- High and low: we got where, but we don’t know when;
- Biggest & smallest trades: we know shit, we infer it the way it was described before.'
By using the location of the close & open prices relative to the high & low prices, we can make educated guesses about whether high or low was made first in a given bar. It’s not perfect, but it’s ultimately all we can do—this is the very last bit of info we can extract from the data we have.
There are 2 methods for inferring volume delta (which I call simply volume) that are presented everywhere, even here on TradingView. Funny thing is, this is actually 2 parts of the 1 method. I wonder how many folks see through it xD. The same method can be used for both inferring volume delta AND making educated guesses whether high or low was made first.
Imagine and/or find the cases on your charts to understand faster:
* Close > open means we have an up bar and probably the volume is positive, and probably high was made later than low.
* Close < open means we have a down bar and probably the volume is negative, and probably low was made later than high.
Now that’s the point when you see that these 2 mentioned methods are actually parts of the 1 method:
If close = open, we still have another clue: distance from open/close pair to high (HC), and distance from open/close pair to low (LC):
* HC < LC, probably high was made later.
* HC > LC, probably low was made later.
And only if close = open and HC = LC, only in this case we have no clue whether high or low was made earlier within a bar. We simply don’t have any more information to even guess. This bar is called a neutral bar.
At this point, we have both time (order) and price info for each of our 6 values. Now, we have to solve another weighted average problem, and that’s it. We’ll weight prices according to the order we’ve guessed. In the neutral bar case, open has a weight of 1, close has a weight of 3, and both high and low have weights of 2 since we can’t infer which one was made first. In all cases, biggest and smallest ticks are modeled with HL2 and weighted like they’re located in the middle of the bar in a time sense.
P.S.: I’ve also included a "robust" method where all the bars are treated like neutral ones. I’ve used it before; obviously, it has lesser info gain -> works a bit worse.
Cryptocurrency StrengthMulti-Currency Analysis: Monitor up to 19 different currencies simultaneously, including major pairs like USD, EUR, JPY, and GBP, as well as emerging market currencies such as CNY, INR, and BRL.
Customizable Display: Easily toggle the visibility of each currency and personalize their colors to suit your preferences, allowing for a tailored analysis experience.
Real-Time Strength Measurement: The indicator calculates and displays the relative strength of each currency in real-time, helping you identify potential trends and trading opportunities.
Clear Visual Representation: With color-coded lines and a dynamic legend, the indicator presents complex currency relationships in an easy-to-understand format.
Advantages
Comprehensive Market View: Gain insights into the broader forex market dynamics by analyzing multiple currencies at once.
Trend Identification: Quickly spot strong and weak currencies, aiding in the identification of potential trending pairs.
Divergence Detection: Use the indicator to identify divergences between currency strength and price action, potentially signaling reversals or continuation patterns.
Flexible Time Frames: Apply the indicator across various time frames to align with your trading strategy, from intraday to long-term analysis.
Enhanced Decision Making: Make more informed trading decisions by understanding the relative strength of currencies involved in your trades.
Unique Qualities
TSI-Based Calculations: Utilizes the True Strength Index for a more nuanced and responsive measure of currency strength compared to simple price-based indicators.
Adaptive Legend: The indicator features a dynamic legend that updates automatically based on the selected currencies, ensuring a clutter-free and relevant display.
Emerging Market Inclusion: Unlike many standard currency strength indicators, this tool includes a wide range of emerging market currencies, providing a truly global perspective.
Whether you're a seasoned forex trader or just starting out, this Currency Strength Indicator offers valuable insights that can complement your existing strategy and potentially improve your trading outcomes. Its combination of comprehensive analysis, customization options, and clear visualization makes it an essential tool for navigating the complex world of currency trading.

Currency StrengthThis innovative Currency Strength Indicator is a powerful tool for forex traders, offering a comprehensive and visually intuitive way to analyze the relative strength of multiple currencies simultaneously. Here's what makes this indicator stand out:
Extensive Currency Coverage
One of the most striking features of this indicator is its extensive coverage of currencies. While many similar tools focus on just the major currencies, this indicator includes:
Major currencies: USD, EUR, JPY, GBP, CHF, CAD, AUD, NZD
Additional currencies: CNY, HKD, KRW, MXN, INR, RUB, SGD, TRY, BRL, ZAR, THB
This wide range allows traders to gain insights into a broader spectrum of the forex market, including emerging markets and less commonly traded currencies.
Unique Visual Presentation
The indicator boasts a clear and user-friendly interface:
Each currency is represented by a distinct colored line for easy identification
A legend is prominently displayed at the top of the chart, using color-coded labels for quick reference
Users can customize which currencies to display, allowing for a tailored analysis
This clean, organized presentation enables traders to quickly grasp the relative strengths of different currencies at a glance.
Robust Measurement Methodology
The indicator employs the True Strength Index (TSI) to calculate currency strength, which provides several advantages:
TSI is a momentum oscillator that shows both trend direction and overbought/oversold conditions
It uses two smoothing periods (fast and slow), which helps filter out market noise and provides more reliable signals
The indicator calculates TSI for each currency index (e.g., DXY for USD, EXY for EUR), ensuring a comprehensive strength measurement
By using TSI, this indicator offers a more nuanced and accurate representation of currency strength compared to simpler moving average-based indicators.
Customization and Flexibility
Traders can fine-tune the indicator to suit their needs:
Adjustable TSI parameters (fast and slow periods)
Ability to show/hide specific currencies
Customizable color scheme for each currency line
Practical Applications
This Currency Strength Indicator can be used for various trading strategies:
Identifying potential trend reversals when a currency reaches extreme overbought or oversold levels
Spotting divergences between currency pairs
Confirming trends across multiple timeframes
Enhancing multi-pair trading strategies
By providing a clear, comprehensive, and customizable view of currency strength across a wide range of currencies, this indicator equips traders with valuable insights for making informed trading decisions in the complex world of forex.

BTC Seasonality Strategy (Weekly)This strategy identifies potential weekend opportunities in Bitcoin (BTC) markets by leveraging the concept of seasonality, entering a position at a predefined time and day, and exiting at a specified time and day.
Key Features
Customizable Time and Day Selection:
Users can select the entry and exit days and corresponding times (in EST).
Directional Flexibility:
The strategy allows traders to choose between long or short positions.
TradingView Compliance:
The script adheres to TradingView's house rules, avoids overly complex conditions, and provides clear user-configurable inputs.
How It Works
The script determines the current weekday and hour in EST, converting TradingView's UTC time for accurate comparisons.
If the current day and hour match the selected entry conditions, a trade (long or short) is opened.
The position is closed when the current day and hour match the specified exit conditions.
Theoretical Basis
Market Seasonality:
The concept of seasonality in financial markets refers to predictable patterns based on time, such as weekends or specific days of the week. Studies have shown that cryptocurrency markets exhibit unique trading behaviors during weekends due to reduced institutional activity and higher retail participation behavioral Biases**:
Retail traders often dominate weekend markets, potentially causing predictable inefficiencies .
Reverences**
Baur, D. G., Hong, K., & Lee, A. D. (2018). Bitcoin: Medium of exchange or speculative assets? Journal of International Financial Markets, Institutions and Money, 54, 177–189.
Urquhart, A. (2016). The inefficiency of Bitcoin. Economics Letters, 148, 80–82.

simple swing indicator-KTRNSE:NIFTY
1. Pivot High/Low as Lines:
Purpose: Identifies local peaks (pivot highs) and troughs (pivot lows) in price and draws horizontal lines at these levels.
How it Works:
A pivot high occurs when the price is higher than the surrounding bars (based on the pivotLength parameter).
A pivot low occurs when the price is lower than the surrounding bars.
These pivots are drawn as horizontal lines at the price level of the pivot.
Visualization:
Pivot High: A red horizontal line is drawn at the price level of the pivot high.
Pivot Low: A green horizontal line is drawn at the price level of the pivot low.
Example:
Imagine the price is trending up, and at some point, it forms a peak. The script identifies this peak as a pivot high and draws a red line at the price of that peak. Similarly, if the price forms a trough, the script will draw a green line at the low point.
2. Moving Averages (20-day and 50-day):
Purpose: Plots the 20-day and 50-day simple moving averages (SMA) on the chart.
How it Works:
The 20-day SMA smooths the closing price over the last 20 days.
The 50-day SMA smooths the closing price over the last 50 days.
These lines provide an overview of short-term and long-term price trends.
Visualization:
20-day SMA: A blue line showing the 20-day moving average.
50-day SMA: An orange line showing the 50-day moving average.
Example:
When the price is above both moving averages, it indicates an uptrend. If the price crosses below these averages, it might signal a downtrend.
3. Supertrend:
Purpose: The Supertrend is an indicator based on the Average True Range (ATR) and is used to track the market trend.
How it Works:
When the market is in an uptrend, the Supertrend line will be green.
When the market is in a downtrend, the Supertrend line will be red.
Visualization:
Uptrend: The Supertrend line will be plotted in green.
Downtrend: The Supertrend line will be plotted in red.
Example:
If the price is above the Supertrend, the market is considered to be in an uptrend, and if the price is below the Supertrend, the market is in a downtrend.
4. Momentum (Rate of Change):
Purpose: Measures the rate at which the price changes over a set period, showing if the momentum is positive or negative.
How it Works:
The Rate of Change (ROC) measures how much the price has changed over a certain number of periods (e.g., 14).
Positive ROC indicates upward momentum, and negative ROC indicates downward momentum.
Visualization:
Positive ROC: A purple line is plotted above the zero line.
Negative ROC: A purple line is plotted below the zero line.
Example:
If the ROC line is above zero, it means the price is increasing, suggesting bullish momentum. If the ROC is below zero, it indicates bearish momentum.
5. Volume:
Purpose: Displays the volume of traded assets, giving insight into the strength of price movements.
How it Works:
The script will color the volume bars based on whether the price closed higher or lower than the previous bar.
Green bars indicate bullish volume (closing price higher than the previous bar), and red bars indicate bearish volume (closing price lower than the previous bar).
Visualization:
Bullish Volume: Green volume bars when the price closes higher.
Bearish Volume: Red volume bars when the price closes lower.
Example:
If you see a green volume bar, it suggests that the market is participating in an uptrend, and the price has closed higher than the previous period. Red bars indicate a downtrend or selling pressure.
6. MACD (Moving Average Convergence Divergence):
Purpose: The MACD is a trend-following momentum indicator that shows the relationship between two moving averages of the price.
How it Works:
The MACD Line is the difference between the 12-period EMA (Exponential Moving Average) and the 26-period EMA.
The Signal Line is the 9-period EMA of the MACD Line.
The MACD Histogram shows the difference between the MACD line and the Signal line.
Visualization:
MACD Line: A blue line representing the difference between the 12-period and 26-period EMAs.
Signal Line: An orange line representing the 9-period EMA of the MACD line.
MACD Histogram: A red or green histogram that shows the difference between the MACD line and the Signal line.
Example:
When the MACD line crosses above the Signal line, it’s considered a bullish signal. When the MACD line crosses below the Signal line, it’s considered a bearish signal.
Full Chart Example:
Imagine you're looking at a price chart with all the indicators:
Pivot High/Low Lines are drawn as red and green horizontal lines.
20-day and 50-day SMAs are plotted as blue and orange lines, respectively.
Supertrend shows a green or red line indicating the trend.
Momentum (ROC) is shown as a purple line oscillating around zero.
Volume bars are green or red based on whether the close is higher or lower.
MACD appears as a blue line and orange line, with a red or green histogram showing the MACD vs. Signal line difference.
How the Indicators Work Together:
Trend Confirmation: If the price is above the Supertrend line and both SMAs are trending up, it indicates a strong bullish trend.
Momentum: If the ROC is positive and the MACD line is above the Signal line, it further confirms bullish momentum.
Volume: Increasing volume, especially with green bars, suggests that the trend is being supported by active participation.
By using these combined indicators, you can get a comprehensive view of the market's trend, momentum, and potential reversal points (via pivot highs and lows).
