[SGM Auto Regressiv - significant lags only]This Pine Script™ is designed for traders seeking advanced statistical analysis based on autoregressive (AR) models, with automatic filtering of significant lags according to a customizable confidence threshold.
Key Features:
AR(p) Model with Significance Filtering:
Only statistically significant lags (based on the selected confidence level) are included in the model calculations.
Coefficient Weighting Options:
Uniform weighting.
Weighting based on the t-statistic.
Visualization of Key Indicators:
Dynamic plotting of autoregressive values, upper and lower bounds (based on standard deviation).
Buy ("Buy") and Sell ("Sell") signals when values exceed the defined bounds.
Robust Analysis:
Calculation of statistical parameters: T-stat, p-value, skewness, kurtosis, r², and the Jarque-Bera test to assess the robustness and normality of residuals.
Summary of results displayed in a visual table for simplified interpretation.
Interactive Tables:
Display of lags, coefficients, t-statistics, p-values, and their significance via a dynamic table.
Overall robustness indicator and interpretation of results ("Good," "Non-significant," etc.).
Easy Customization:
Adjustable confidence level (90% to 99%).
Configurable lengths for moving average and standard deviation to fine-tune signal thresholds.
Benefits for Traders:
Effortless Analysis:
Automatically identifies significant relationships between past and present values, removing unnecessary assumptions.
Enhanced Accuracy:
Filters signals based on rigorous statistical criteria to avoid false signals.
Clear Visualization:
Interactive tables and plots to quickly understand critical parameters.
Default Configuration:
Confidence level: 95%.
Lag weighting: Uniform.
Moving average length: 20 periods.
Standard deviation length: 15 periods.
Usage Recommendations:
Ideal for analyzing volatile assets or identifying potential reversal zones.
Use alongside other indicators to confirm signals.
Statistics

QuantifyPS - 1Library "QuantifyPS"
normdist(z)
Parameters:
z (float) : (float): The z-score for which the CDF is to be calculated.
Returns: (float): The cumulative probability corresponding to the input z-score.
Notes:
- Uses an approximation method for the normal distribution CDF, which is computationally efficient.
- The result is accurate for most practical purposes but may have minor deviations for extreme values of `z`.
Formula:
- Based on the approximation formula:
`Φ(z) ≈ 1 - f(z) * P(t)` if `z > 0`, otherwise `Φ(z) ≈ f(z) * P(t)`,
where:
`f(z) = 0.3989423 * exp(-z^2 / 2)` (PDF of standard normal distribution)
`P(t) = Σ [c * t^i]` with constants `c` and `t = 1 / (1 + 0.2316419 * |z|)`.
Implementation details:
- The approximation uses five coefficients for the polynomial part of the CDF.
- Handles both positive and negative values of `z` symmetrically.
Constants:
- The coefficients and scaling factors are chosen to minimize approximation errors.
gamma(x)
Parameters:
x (float) : (float): The input value for which the Gamma function is to be calculated.
Must be greater than 0. For x <= 0, the function returns `na` as it is undefined.
Returns: (float): Approximation of the Gamma function for the input `x`.
Notes:
- The Lanczos approximation provides a numerically stable and efficient method to compute the Gamma function.
- The function is not defined for `x <= 0` and will return `na` in such cases.
- Uses precomputed Lanczos coefficients for accuracy.
- Includes handling for small numerical inaccuracies.
Formula:
- The Gamma function is approximated as:
`Γ(x) ≈ sqrt(2π) * t^(x + 0.5) * e^(-t) * Σ(p / (x + k))`
where `t = x + g + 0.5` and `p` is the array of Lanczos coefficients.
Implementation details:
- Lanczos coefficients (`p`) are precomputed and stored in an array.
- The summation iterates over these coefficients to compute the final result.
- The constant `g` controls the precision of the approximation (commonly `g = 7`).
t_cdf(t, df)
Parameters:
t (float) : (float): The t-statistic for which the CDF value is to be calculated.
df (int) : (int): Degrees of freedom of the t-distribution.
Returns: (float): Approximate CDF value for the given t-statistic.
Notes:
- This function computes a one-tailed p-value.
- Relies on an approximation formula using gamma functions and standard t-distribution properties.
- May not be as accurate as specialized statistical libraries for extreme values or very high degrees of freedom.
Formula:
- Let `x = df / (t^2 + df)`.
- The approximation formula is derived using:
`CDF(t, df) ≈ 1 - * x^((df + 1) / 2) / 2`,
where Γ represents the gamma function.
Implementation details:
- Computes the gamma ratio for normalization.
- Applies the t-distribution formula for one-tailed probabilities.
tStatForPValue(p, df)
Parameters:
p (float) : (float): P-value for which the t-statistic needs to be calculated.
Must be in the interval (0, 1).
df (int) : (int): Degrees of freedom of the t-distribution.
Returns: (float): The t-statistic corresponding to the given p-value.
Notes:
- If `p` is outside the interval (0, 1), the function returns `na` as an error.
- The function uses binary search with a fixed number of iterations and a defined tolerance.
- The result is accurate to within the specified tolerance (default: 0.0001).
- Relies on the cumulative density function (CDF) `t_cdf` for the t-distribution.
Formula:
- Uses the cumulative density function (CDF) of the t-distribution to iteratively find the t-statistic.
Implementation details:
- `low` and `high` define the search interval for the t-statistic.
- The midpoint (`mid`) is iteratively refined until the difference between the cumulative probability
and the target p-value is smaller than the tolerance.
jarqueBera(n, s, k)
Parameters:
n (float) : (series float): Number of observations in the dataset.
s (float) : (series float): Skewness of the dataset.
k (float) : (series float): Kurtosis of the dataset.
Returns: (float): The Jarque-Bera test statistic.
Formula:
JB = n *
Notes:
- A higher JB value suggests that the data deviates more from a normal distribution.
- The test is asymptotically distributed as a chi-squared distribution with 2 degrees of freedom.
- Use this value to calculate a p-value to determine the significance of the result.
skewness(data)
Parameters:
data (float) : (series float): Input data series.
Returns: (float): The skewness value.
Notes:
- Handles missing values (`na`) by ignoring invalid points.
- Includes error handling for zero variance to avoid division-by-zero scenarios.
- Skewness is calculated as the normalized third central moment of the data.
kurtosis(data)
Parameters:
data (float) : (series float): Input data series.
Returns: (float): The kurtosis value.
Notes:
- Handles missing values (`na`) by ignoring invalid points.
- Includes error handling for zero variance to avoid division-by-zero scenarios.
- Kurtosis is calculated as the normalized fourth central moment of the data.
regression(y, x, lag)
Parameters:
y (float) : (series float): Dependent series (observed values).
x (float) : (series float): Independent series (explanatory variable).
lag (int) : (int): Number of lags applied to the independent series (x).
Returns: (tuple): Returns a tuple containing the following values:
- n: Number of valid observations.
- alpha: Intercept of the regression line.
- beta: Slope of the regression line.
- t_stat: T-statistic for the beta coefficient.
- p_value: Two-tailed p-value for the beta coefficient.
- r_squared: Coefficient of determination (R²) indicating goodness of fit.
- skew: Skewness of the residuals.
- kurt: Kurtosis of the residuals.
Notes:
- Handles missing data (`na`) by ignoring invalid points.
- Includes basic error handling for zero variance and division-by-zero scenarios.
- Computes residual-based statistics (skewness and kurtosis) for model diagnostics.
Correlation Confluence Trend IndicatorCorrelation Confluence Trend Indicator
Overview
The Correlation Confluence Trend Indicator combines exponential moving averages (EMAs) and statistical correlation measures to identify high-confidence trend alignments between an asset and a benchmark. By filtering signals through correlation strength, this indicator highlights opportunities when the asset and benchmark move together. In other words, it defines a trend and then uses correlation strength and the trend of a second asset to identify high-confidence trends.
Key Features
Dual EMA Trend Analysis :
Calculates fast and slow EMAs for both the asset and the selected benchmark (e.g., SPY) to identify bullish and bearish trends.
Correlation Strength Filtering :
Evaluates correlation between the asset and benchmark, identifying stronger-than-average relationships based on the mean and standard deviation.
Background Color Coding :
- Green : Strong correlation, both asset and benchmark bullish.
- Aqua : Weak correlation, both asset and benchmark bullish.
- Red : Strong correlation, both asset and benchmark bearish.
- Fuchsia : Weak correlation, both asset and benchmark bearish.
- Orange : Strong correlation, benchmark bullish, asset bearish.
- Yellow : Weak correlation, benchmark bullish, asset bearish.
- Purple : Strong correlation, benchmark bearish, asset bullish.
- Lime : Weak correlation, benchmark bearish, asset bullish.
Visual Trend Indicators :
Plots fast and slow EMAs for the asset, dynamically colored based on aggregate trend signals. The color of this corresponds to the main trend signal.
Inputs
Benchmark Symbol : Symbol of the benchmark asset to compare against.
Fast EMA Length : Period for the fast EMA calculation.
Slow EMA Length : Period for the slow EMA calculation.
Correlation Length : Number of bars for correlation calculation.
Correlation Mean Length : Number of bars for mean and standard deviation calculation.
Std Dev Multiplier : Multiplier for standard deviation to define correlation strength. When the correlation is Std Dev Multiplier standard deviations above the mean, it counts as a strong correlation.
Set Background Color : Toggle background coloring on or off.
Notes
This indicator is primarily designed for trend-following strategies. By combining trend analysis and correlation filtering, it ensures that signals occur during aligned market conditions, reducing false signals.
Before incorporating this indicator into your trading strategy:
Always backtest on historical data to evaluate its performance before committing capital.
Use proper risk management to control position sizes and mitigate potential losses.
Remember that no indicator guarantees success. I'm quite proud of this one, but it's not the holy grail.

GaussianDistributionLibrary "GaussianDistribution"
This library defines a custom type `distr` representing a Gaussian (or other statistical) distribution.
It provides methods to calculate key statistical moments and scores, including mean, median, mode, standard deviation, variance, skewness, kurtosis, and Z-scores.
This library is useful for analyzing probability distributions in financial data.
Disclaimer:
I am not a mathematician, but I have implemented this library to the best of my understanding and capacity. Please be indulgent as I tried to translate statistical concepts into code as accurately as possible. Feedback, suggestions, and corrections are welcome to improve the reliability and robustness of this library.
mean(source, length)
Calculate the mean (average) of the distribution
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
Returns: Mean (μ)
stdev(source, length)
Calculate the standard deviation (σ) of the distribution
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
Returns: Standard deviation (σ)
skewness(source, length, mean, stdev)
Calculate the skewness (γ₁) of the distribution
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
mean (float) : the mean (average) of the distribution
stdev (float) : the standard deviation (σ) of the distribution
@return Skewness (γ₁)
skewness(source, length)
Overloaded skewness to calculate from source and length
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
@return Skewness (γ₁)
mode(mean, stdev, skewness)
Estimate mode - Most frequent value in the distribution (approximation based on skewness)
Parameters:
mean (float) : the mean (average) of the distribution
stdev (float) : the standard deviation (σ) of the distribution
skewness (float) : the skewness (γ₁) of the distribution
@return Mode
mode(source, length)
Overloaded mode to calculate from source and length
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
@return Mode
median(mean, stdev, skewness)
Estimate median - Middle value of the distribution (approximation)
Parameters:
mean (float) : the mean (average) of the distribution
stdev (float) : the standard deviation (σ) of the distribution
skewness (float) : the skewness (γ₁) of the distribution
@return Median
median(source, length)
Overloaded median to calculate from source and length
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
@return Median
variance(stdev)
Calculate variance (σ²) - Square of the standard deviation
Parameters:
stdev (float) : the standard deviation (σ) of the distribution
@return Variance (σ²)
variance(source, length)
Overloaded variance to calculate from source and length
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
@return Variance (σ²)
kurtosis(source, length, mean, stdev)
Calculate kurtosis (γ₂) - Degree of "tailedness" in the distribution
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
mean (float) : the mean (average) of the distribution
stdev (float) : the standard deviation (σ) of the distribution
@return Kurtosis (γ₂)
kurtosis(source, length)
Overloaded kurtosis to calculate from source and length
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
@return Kurtosis (γ₂)
normal_score(source, mean, stdev)
Calculate Z-score (standard score) assuming a normal distribution
Parameters:
source (float) : Distribution source (typically a price or indicator series)
mean (float) : the mean (average) of the distribution
stdev (float) : the standard deviation (σ) of the distribution
@return Z-Score
normal_score(source, length)
Overloaded normal_score to calculate from source and length
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
@return Z-Score
non_normal_score(source, mean, stdev, skewness, kurtosis)
Calculate adjusted Z-score considering skewness and kurtosis
Parameters:
source (float) : Distribution source (typically a price or indicator series)
mean (float) : the mean (average) of the distribution
stdev (float) : the standard deviation (σ) of the distribution
skewness (float) : the skewness (γ₁) of the distribution
kurtosis (float) : the "tailedness" in the distribution
@return Z-Score
non_normal_score(source, length)
Overloaded non_normal_score to calculate from source and length
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
@return Z-Score
method init(this)
Initialize all statistical fields of the `distr` type
Namespace types: distr
Parameters:
this (distr)
method init(this, source, length)
Overloaded initializer to set source and length
Namespace types: distr
Parameters:
this (distr)
source (float)
length (int)
distr
Custom type to represent a Gaussian distribution
Fields:
source (series float) : Distribution source (typically a price or indicator series)
length (series int) : Window length for the distribution (must be >= 30 for meaningful statistics)
mode (series float) : Most frequent value in the distribution
median (series float) : Middle value separating the greater and lesser halves of the distribution
mean (series float) : μ (1st central moment) - Average of the distribution
stdev (series float) : σ or standard deviation (square root of the variance) - Measure of dispersion
variance (series float) : σ² (2nd central moment) - Squared standard deviation
skewness (series float) : γ₁ (3rd central moment) - Asymmetry of the distribution
kurtosis (series float) : γ₂ (4th central moment) - Degree of "tailedness" relative to a normal distribution
normal_score (series float) : Z-score assuming normal distribution
non_normal_score (series float) : Adjusted Z-score considering skewness and kurtosis
MACD -- Normalized█ OVERVIEW
This indicator is a normalized and scaled version of the Moving Average Convergence Divergence ( MACD ) indicator, inspired by the work in "Statistically Sound Indicators" by Timothy Masters. It enhances the traditional MACD by applying statistical normalization and scaling techniques, providing more consistent and reliable signals across different markets and timeframes.
█ CONCEPTS
The traditional MACD measures the difference between two Exponential Moving Averages ( EMAs ) of different lengths to identify momentum changes. However, its raw values are unbounded, making it challenging to compare across different instruments or timeframes.
This normalized MACD addresses this limitation by:
• Normalization : Adjusting the MACD values using the Average True Range ( ATR ) to account for market volatility.
• Scaling : Applying the Cumulative Distribution Function ( CDF ) to constrain the output between -50 and +50.
• Smoothing : Providing a smoothed signal line and histogram to effectively visualize momentum shifts.
█ FEATURES
• Normalized MACD Line : Computes the difference between the short-term and long-term EMAs, normalized by market volatility.
• Signal Line : Applies EMA smoothing to the normalized MACD line over a user-defined period.
• Histogram : Visualizes the difference between the normalized MACD line and the signal line, highlighting momentum changes.
• Customization Options :
• Adjustable lengths for the short-term EMA, long-term EMA, and signal line smoothing.
• Ability to toggle the visibility of the MACD line, signal line, and histogram.
• Statistical Scaling : Utilizes statistical methods from Timothy Masters' work to provide consistent scaling across different instruments.
█ HOW TO USE
1 — Identify Momentum Shifts :
• A crossover of the MACD line above the signal line may indicate a bullish momentum shift.
• A crossover of the MACD line below the signal line may indicate a bearish momentum shift.
2 — Analyze the Histogram :
• A rising histogram suggests strengthening momentum in the current trend direction.
• A falling histogram may signal weakening momentum or a potential reversal.
3 — Customize Parameters :
• Adjust the EMA lengths and smoothing periods to fit the specific instrument or timeframe.
• Use the visibility toggles to focus on the components most relevant to your analysis.
4 — Combine with Other Tools :
• Use in conjunction with support/resistance levels, trend lines, or other indicators to confirm signals.
• Consider the overall market context to enhance decision-making.
█ LIMITATIONS
• The indicator is based on historical price data; it may not predict future market movements accurately.
• May produce false signals during low volatility or ranging market conditions.
• Initial periods may display na values due to insufficient data for calculations.
█ NOTES
• Ensure that the MathHelpers library by HuntGatherTrade is imported for the indicator to function correctly.
• The default parameters are commonly used settings but may require adjustments based on the trading instrument and timeframe.
• The normalization and scaling techniques are designed to make the indicator's outputs more comparable across different markets.

Close Minus Moving Average█ OVERVIEW
The Close Minus Moving Average (CMMA) is a statistically robust mean reversion indicator designed to identify potential reversal points in the market. By analyzing the relationship between the closing price and its moving average, CMMA provides traders with actionable insights to enhance their trading strategies.
Important
This indicator requires the use of the MathHelpers library published by HuntGatherTrade
█ CONCEPTS
The CMMA indicator operates by calculating the logarithmic difference between the current closing price and its simple moving average (SMA). This difference is then normalized using the Average True Range (ATR) to account for market volatility. The resulting value is transformed using the Cumulative Distribution Function (CDF) to produce a standardized metric that oscillates around zero.
Key Steps :
Logarithmic Calculation: Computes the natural logarithm of the closing prices.
Moving Average: Applies a simple moving average to the logarithmic closing prices.
ATR Normalization: Utilizes ATR to normalize the difference, ensuring the indicator adapts to varying market conditions.
CDF Transformation: Transforms the normalized difference to a scale that highlights mean reversion tendencies.
Mean Reversion
Mean reversion is a financial theory suggesting that asset prices and historical returns eventually return to the long-term mean or average level of the entire dataset. The CMMA leverages this concept to signal potential entry and exit points based on deviations from the moving average.
█ FEATURES
Adaptive Normalization: Utilizes ATR to adjust for market volatility, ensuring consistent performance across different market conditions.
Statistical Robustness: Built upon methodologies from Timothy Masters, ensuring reliable mean reversion signals.
Clear Visuals: Differentiates positive and negative deviations with distinct color coding for easy interpretation.
Customizable Parameters: Allows users to adjust lookback periods and ATR lengths to tailor the indicator to their specific trading needs
.
█ HOW TO USE
Add the Indicator :
Navigate to the Pine Script editor on TradingView.
Paste the CMMA script and add it to your chart.
Adjust Parameters :
Lookback Period: Determines the number of periods for calculating the moving average of the logarithmic close. Default is 1.
ATR Length: Sets the number of periods for ATR calculation. Default is 252.
Interpret Signals :
Green Plot: Indicates that the closing price is above the moving average, suggesting bullish momentum.
Red Plot: Indicates that the closing price is below the moving average, suggesting bearish momentum.
Zero Line: Serves as a reference point for mean reversion signals.
Trading Strategy :
Buy Signal: When CMMA crosses above the zero line, indicating a potential upward reversal.
Sell Signal: When CMMA crosses below the zero line, indicating a potential downward reversal.
█ LIMITATIONS
Lagging Indicator: As with all moving averages, CMMA is based on historical data and may lag during rapid market movements.
Parameter Sensitivity: The effectiveness of CMMA can vary based on the chosen lookback and ATR periods. Users should optimize these parameters based on the specific asset and timeframe.
Market Conditions: Best suited for mean-reverting markets and may underperform in trending or highly volatile environments.
█ NOTES
Version Compatibility: The CMMA script is written in Pine Script™ version 6. Ensure your TradingView environment supports this version.
License: This Pine Script™ code is subject to the terms of the Mozilla Public License 2.0. Read the license here.
MathHelpersLibrary "MathHelpers"
Overview
A collection of helper functions for designing indicators and strategies.
calculateATR(length, log)
Calculates the Average True Range (ATR) or Log ATR based on the 'log' parameter. Sans Wilder's Smoothing
Parameters:
length (simple int)
log (simple bool)
Returns: float The calculated ATR value. Returns Log ATR if `log` is true, otherwise returns standard ATR.
CDF(z)
Computes the Cumulative Distribution Function (CDF) for a given value 'z', mimicking the CDF function in "Statistically Sound Indicators" by Timothy Masters.
Parameters:
z (simple float)
Returns: float The CDF value corresponding to the input `z`, ranging between 0 and 1.
logReturns(lookback)
Calculates the logarithmic returns over a specified lookback period.
Parameters:
lookback (simple int)
Returns: float The calculated logarithmic return. Returns `na` if insufficient data is available.
Global Index Spread RSI StrategyThis strategy leverages the relative strength index (RSI) to monitor the price spread between a global benchmark index (such as AMEX) and the currently opened asset in the chart window. By calculating the spread between these two, the strategy uses RSI to identify oversold and overbought conditions to trigger buy and sell signals.
Key Components:
Global Benchmark Index: The strategy compares the current asset with a predefined global index (e.g., AMEX) to measure relative performance. The choice of a global benchmark allows the trader to analyze the current asset's movement in the context of broader market trends.
Spread Calculation:
The spread is calculated as the percentage difference between the current asset's closing price and the global benchmark index's closing price:
Spread=Current Asset Close−Global Index CloseGlobal Index Close×100
Spread=Global Index CloseCurrent Asset Close−Global Index Close×100
This metric provides a measure of how the current asset is performing relative to the global index. A positive spread indicates the asset is outperforming the benchmark, while a negative spread signals underperformance.
RSI of the Spread: The RSI is then calculated on the spread values. The RSI is a momentum oscillator that ranges from 0 to 100 and is commonly used to identify overbought or oversold conditions in asset prices. An RSI below 30 is considered oversold, indicating a potential buying opportunity, while an RSI above 70 is overbought, suggesting that the asset may be due for a pullback.
Strategy Logic:
Entry Condition: The strategy enters a long position when the RSI of the spread falls below the oversold threshold (default 30). This suggests that the asset may have been oversold relative to the global benchmark and might be due for a reversal.
Exit Condition: The strategy exits the long position when the RSI of the spread rises above the overbought threshold (default 70), indicating that the asset may have become overbought and a price correction is likely.
Visual Reference:
The RSI of the spread is plotted on the chart for visual reference, making it easier for traders to monitor the relative strength of the asset in relation to the global benchmark.
Overbought and oversold levels are also drawn as horizontal reference lines (70 and 30), along with a neutral level at 50 to show market equilibrium.
Theoretical Basis:
The strategy is built on the mean reversion principle, which suggests that asset prices tend to revert to a long-term average over time. When prices move too far from this mean—either being overbought or oversold—they are likely to correct back toward equilibrium. By using RSI to identify these extremes, the strategy aims to profit from price reversals.
Mean Reversion: According to financial theory, asset prices oscillate around a long-term average, and any extreme deviation (overbought or oversold conditions) presents opportunities for price corrections (Poterba & Summers, 1988).
Momentum Indicators (RSI): The RSI is widely used in technical analysis to measure the momentum of an asset. Its application to the spread between the asset and a global benchmark allows for a more nuanced view of relative performance and potential turning points in the asset's price trajectory.
Practical Application:
This strategy works best in markets where relative strength is a key factor in decision-making, such as in equity indices, commodities, or forex markets. By assessing the performance of the asset relative to a global benchmark and utilizing RSI to identify extremes in price movements, the strategy helps traders to make more informed decisions based on potential mean reversion points.
While the "Global Index Spread RSI Strategy" offers a method for identifying potential price reversals based on relative strength and oversold/overbought conditions, it is important to recognize that no strategy is foolproof. The strategy assumes that the historical relationship between the asset and the global benchmark will hold in the future, but financial markets are subject to a wide array of unpredictable factors that can lead to sudden changes in price behavior.
Risk of False Signals:
The strategy relies heavily on the RSI to trigger buy and sell signals. However, like any momentum-based indicator, RSI can generate false signals, particularly in highly volatile or trending markets. In such conditions, the strategy may enter positions too early or exit too late, leading to potential losses.
Market Context:
The strategy may not account for macroeconomic events, news, or other market forces that could cause sudden shifts in asset prices. External factors, such as geopolitical developments, monetary policy changes, or financial crises, can cause a divergence between the asset and the global benchmark, leading to incorrect conclusions from the strategy.
Overfitting Risk:
As with any strategy that uses historical data to make decisions, there is a risk of overfitting the model to past performance. This could result in a strategy that works well on historical data but performs poorly in live trading conditions due to changes in market dynamics.
Execution Risks:
The strategy does not account for slippage, transaction costs, or liquidity issues, which can impact the execution of trades in real-market conditions. In fast-moving markets, prices may move significantly between order placement and execution, leading to worse-than-expected entry or exit prices.
No Guarantee of Profit:
Past performance is not necessarily indicative of future results. The strategy should be used with caution, and risk management techniques (such as stop losses and position sizing) should always be implemented to protect against significant losses.
Traders should thoroughly test and adapt the strategy in a simulated environment before applying it to live trades, and consider seeking professional advice to ensure that their trading activities align with their risk tolerance and financial goals.
References:
Poterba, J. M., & Summers, L. H. (1988). Mean Reversion in Stock Prices: Evidence and Implications. Journal of Financial Economics, 22(1), 27-59.

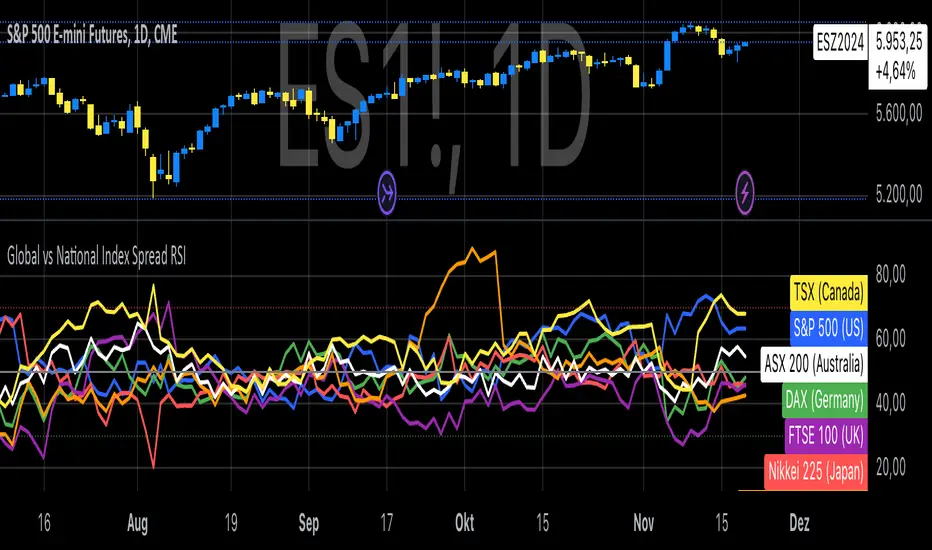
Global vs National Index Spread RSIThe Global vs National Index Spread RSI indicator visualizes the relative strength of national stock indices compared to a global benchmark (e.g., AMEX). It calculates the percentage spread between the closing prices of each national index and the global index, applying the Relative Strength Index (RSI) to each spread.
How It Works
Spread Calculation: The spread represents the percentage difference between a national index and the global index.
RSI Application: RSI is applied to these spreads to identify overbought or oversold conditions in the relative performance of the national indices.
Reference Lines: Overbought (70), oversold (30), and neutral (50) levels help guide interpretation.
Insights from Research
The correlation between global and national indices provides insights into market integration and interdependence. Studies such as Forbes & Rigobon (2002) emphasize the importance of understanding these linkages during periods of financial contagion. Observing spread trends with RSI can aid in identifying shifts in investor sentiment and regional performance anomalies.
Use Cases
- Detect divergences between national and global markets.
- Identify overbought or oversold conditions for specific indices.
- Complement portfolio management strategies by monitoring geographic performance.
References
Forbes, K. J., & Rigobon, R. (2002). "No contagion, only interdependence: Measuring stock market co-movements." Journal of Finance.
Eun, C. S., & Shim, S. (1989). "International transmission of stock market movements." Journal of Financial and Quantitative Analysis.
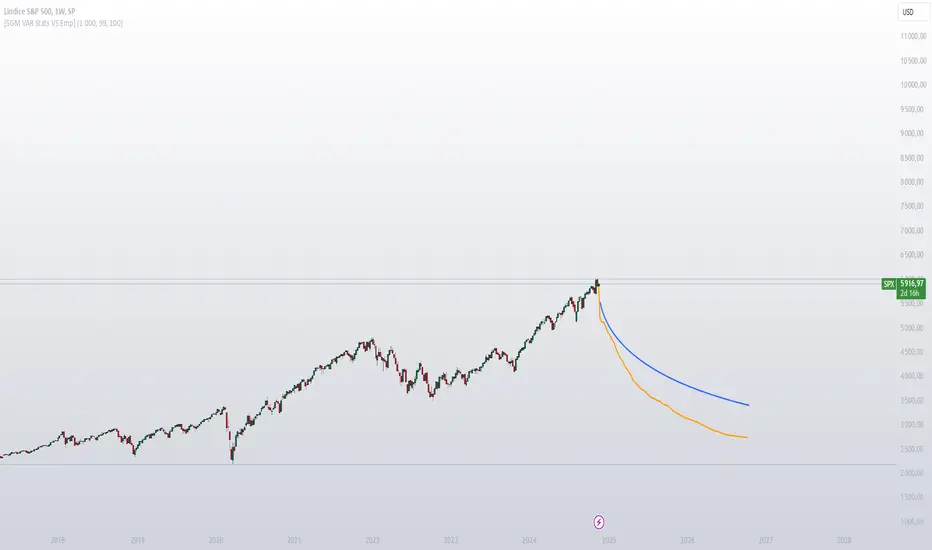
[SGM VaR Stats VS Empirical]Main Functions
Logarithmic Returns & Historical Data
Calculates logarithmic returns from closing prices.
Stores these returns in a dynamic array with a configurable maximum size.
Approximation of the Inverse Error Function
Uses an approximation of the erfinv function to calculate z-scores for given confidence levels.
Basic Statistics
Mean: Calculates the average of the data in the array.
Standard Deviation: Measures the dispersion of returns.
Median: Provides a more robust measure of central tendency for skewed distributions.
Z-Score: Converts a confidence level into a standard deviation multiplier.
Empirical vs. Statistical Projection
Empirical Projection
Based on the median of cumulative returns for each projected period.
Applies an adjustable confidence filter to exclude extreme values.
Statistical Projection
Relies on the mean and standard deviation of historical returns.
Incorporates a standard deviation multiplier for confidence-adjusted projections.
PolyLines (Graphs)
Generates projections visually through polylines:
Statistical Polyline (Blue): Based on traditional statistical methods.
Empirical Polyline (Orange): Derived from empirical data analysis.
Projection Customization
Maximum Data Size: Configurable limit for the historical data array (max_array_size).
Confidence Level: Adjustable by the user (conf_lvl), affects the width of the confidence bands.
Projection Length: Configurable number of projected periods (length_projection).
Key Steps
Capture logarithmic returns and update the historical data array.
Calculate basic statistics (mean, median, standard deviation).
Perform projections:
Empirical: Based on the median of cumulative returns.
Statistical: Based on the mean and standard deviation.
Visualization:
Compare statistical and empirical projections using polylines.
Utility
This script allows users to compare:
Traditional Statistical Projections: Based on mathematical properties of historical returns.
Empirical Projections: Relying on direct historical observations.
Divergence or convergence of these lines also highlights the presence of skewness or kurtosis in the return distribution.
Ideal for traders and financial analysts looking to assess an asset’s potential future performance using combined statistical and empirical approaches.
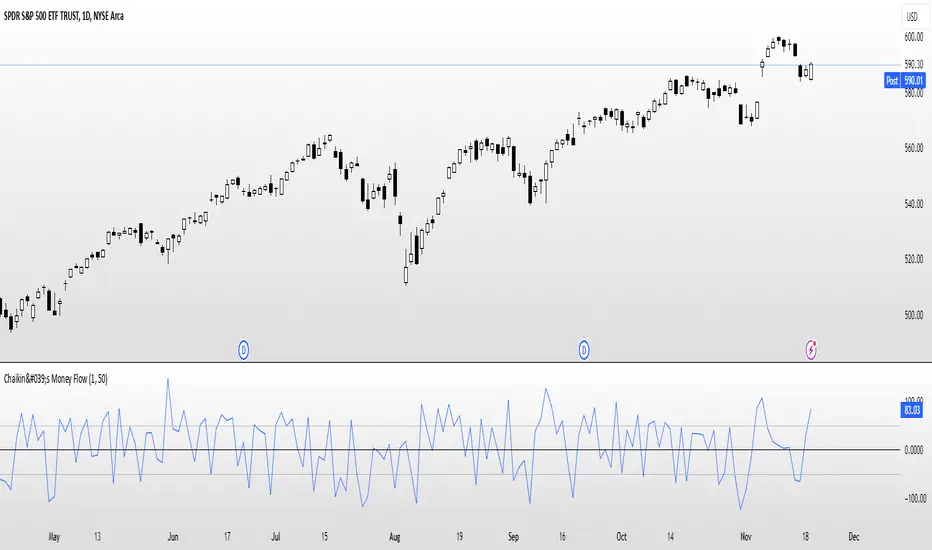
Chaikin's Money FlowOverview : Chaikin's Money Flow (CMF) is a momentum indicator that measures the buying and selling pressure of a financial instrument over a specified period. By incorporating both price and volume, CMF provides a comprehensive view of market sentiment, helping traders identify potential trend reversals and confirm the strength of existing trends.
Key Features:
Volume-Weighted : Unlike price-only indicators, CMF accounts for trading volume, offering deeper insights into the forces driving price movements.
Oscillatory Nature : CMF oscillates between positive and negative values, typically ranging from -100 to +100, indicating the balance between buying and selling pressure.
Trend Confirmation : Positive CMF values suggest accumulating buying pressure, while negative values indicate distributing selling pressure. This aids in confirming the direction and strength of trends.
Calculation Details :
Intraday Intensity (II) = 100 × (2×Close−High−Low) / (High−Low) × Volume
Condition: If High=Low, II is set to 0 to prevent division by zero.
II_smoothed = SMA(II, lookback)
Applies a Simple Moving Average (SMA) to the Intraday Intensity over the defined lookback period to smooth out short-term fluctuations.
Volume Smoothing:
V_smoothed = EMA(Volume, Volume Smoothing Period)
Utilizes an Exponential Moving Average (EMA) to smooth the volume over the specified smoothing period, giving more weight to recent data.
Money Flow Calculation:
Money Flow = II_smoothed / V_smoothed
Condition: If Vsmoothed=0Vsmoothed=0, Money Flow is set to 0 to avoid division by zero.
Usage Instructions:
Parameters Configuration:
Lookback Period: Determines the number of periods over which Intraday Intensity is averaged. A higher value results in a smoother indicator, reducing sensitivity to short-term price movements.
Volume Smoothing Period: Defines the period for the EMA applied to Volume. Adjusting this parameter affects the responsiveness of the Money Flow indicator to changes in trading volume.
Interpreting the Indicator:
Positive Values (>0): Indicate buying pressure. The higher the value, the stronger the buying interest.
Negative Values (<0): Signal selling pressure. The lower the value, the more intense the selling activity.
Crossovers: Watch for Money Flow crossing above the zero line as potential buy signals and crossing below as potential sell signals.
Divergence: Identify divergences between Money Flow and price movements to anticipate possible trend reversals.
Complementary Analysis:
Confluence with Other Indicators: Use CMF in conjunction with trend indicators like Moving Averages or oscillators like RSI to enhance signal reliability.
Volume Confirmation: CMF's volume-weighted approach makes it a powerful tool for confirming the validity of price trends and breakouts.
Acknowledgment: This implementation of Chaikin's Money Flow Indicator is inspired by and derived from the methodologies presented in "Statistically Sound Indicators" by Timothy Masters. The indicator has been meticulously translated to Pine Script to maintain the statistical integrity and effectiveness outlined in the source material.
Disclaimer: The Chaikin's Money Flow Indicator is a tool designed to assist in trading decisions. It does not guarantee profits and should be used in conjunction with other analysis methods. Trading involves risk, and it's essential to perform thorough testing and validation before deploying any indicator in live trading environments.
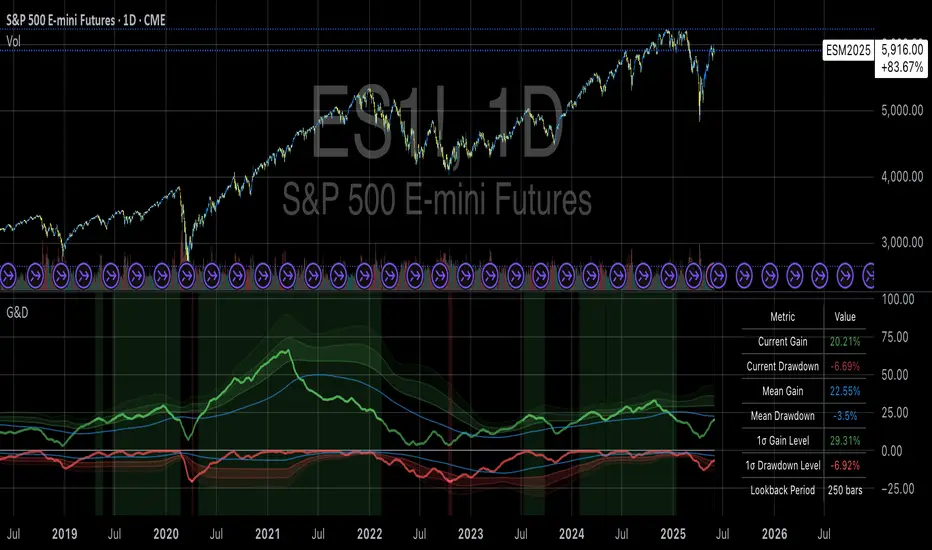
Gains and Drawdowns with Standard DeviationsThis “Gains and Drawdowns with Standard Deviations” indicator helps in analyzing and visualizing the percentage gains and drawdown phases of a market or asset relative to its historical range. By calculating gains from the lowest low and drawdowns from the highest high over a specified lookback period, this indicator provides deeper insights into price movements and risk.
Key Features and Applications:
1. Gain and Drawdown Calculation:
• Gains: The indicator calculates the percentage gain from the lowest price point within a specific lookback period (e.g., 250 days).
• Drawdowns: Drawdowns are calculated as the percentage change from the highest point in the same period. This helps in identifying the maximum loss phases.
2. Standard Deviation:
• The indicator computes the standard deviation of both gains and drawdowns over a specified period (e.g., 250 days), allowing you to quantify volatility.
• Three bands (1st, 2nd, and 3rd standard deviations) are plotted for both gains and drawdowns, representing the frequency and magnitude of price movements within the normal volatility range.
3. Extreme Movements Highlighting:
• The indicator highlights extreme gains and drawdowns when they exceed user-defined thresholds. This helps in identifying significant market events or turning points.
4. Customizable Thresholds:
• Users can adjust the thresholds for extreme gains and drawdowns, as well as the lookback period for calculating gains, drawdowns, and standard deviations, making the indicator highly adaptable to specific needs.
Application in Portfolio Management:
The use of standard deviation in portfolio management is essential for assessing the risk and volatility of a portfolio. According to Modern Portfolio Theory (MPT) by Harry Markowitz, diversification of assets in a portfolio helps to minimize overall risk (especially the standard deviation), while maximizing returns. The standard deviation of a portfolio measures the volatility of its returns, with higher standard deviation indicating higher risk.
Scientific Source: Markowitz, H. M. (1952). Portfolio Selection. The Journal of Finance, 7(1), 77-91.
Markowitz’s theory suggests that an optimized portfolio, by minimizing the standard deviation of returns and combining a diversified asset allocation, can achieve better risk-adjusted returns.
Conclusion:
This indicator is particularly useful for traders and portfolio managers who want to understand and visualize market risk and extreme events. By using gains, drawdowns, and volatility metrics, it allows for systematic monitoring and evaluation of price movements, leading to more informed decisions in trading or portfolio management. A comprehensive understanding of price behavior and volatility helps in optimizing risk management and making strategic market entries.
Key Features:
• Visualization of Gains and Drawdowns with color-coded highlights for extreme movements.
• Standard Deviation Calculations for detailed volatility analysis.
• Customizable Thresholds for identifying extreme market events.
This indicator is a valuable tool for analyzing market data from a scientific standpoint, improving risk management, and making data-driven decisions based on historical performance.
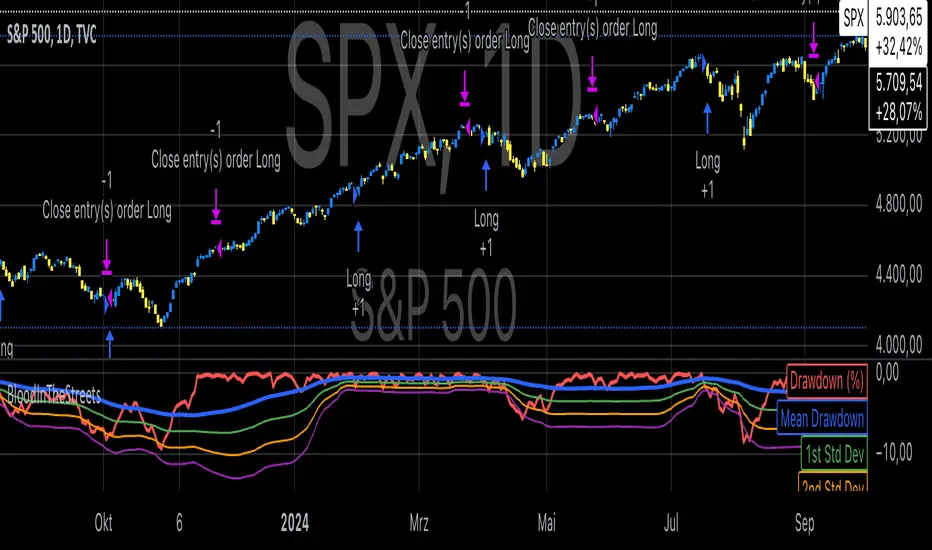
Buy When There's Blood in the Streets StrategyStatistical Analysis of Drawdowns in Stock Markets
Drawdowns, defined as the decline from a peak to a trough in asset prices, are an essential measure of risk and market dynamics. Their statistical properties provide insights into market behavior during extreme stress periods.
Distribution of Drawdowns: Research suggests that drawdowns follow a power-law distribution, implying that large drawdowns, while rare, are more frequent than expected under normal distributions (Sornette et al., 2003).
Impacts of Extreme Drawdowns: During significant drawdowns (e.g., financial crises), the average recovery time is significantly longer, highlighting market inefficiencies and behavioral biases. For example, the 2008 financial crisis led to a 57% drawdown in the S&P 500, requiring years to recover (Cont, 2001).
Using Standard Deviations: Drawdowns exceeding two or three standard deviations from their historical mean are often indicative of market overreaction or capitulation, creating contrarian investment opportunities (Taleb, 2007).
Behavioral Finance Perspective: Investors often exhibit panic-selling during drawdowns, leading to oversold conditions that can be exploited using statistical thresholds like standard deviations (Kahneman, 2011).
Practical Implications: Studies on mean reversion show that extreme drawdowns are frequently followed by periods of recovery, especially in equity markets. This underpins strategies that "buy the dip" under specific, statistically derived conditions (Jegadeesh & Titman, 1993).
References:
Sornette, D., & Johansen, A. (2003). Stock market crashes and endogenous dynamics.
Cont, R. (2001). Empirical properties of asset returns: stylized facts and statistical issues. Quantitative Finance.
Taleb, N. N. (2007). The Black Swan: The Impact of the Highly Improbable.
Kahneman, D. (2011). Thinking, Fast and Slow.
Jegadeesh, N., & Titman, S. (1993). Returns to Buying Winners and Selling Losers: Implications for Stock Market Efficiency.
USDEGP Rate MultipleIndicator shows the ratio between USDEGP rate calculated using CIB GDR and the official rate. In no stress, value should be stable.

London USDEGP priceThis indicator calculates the hypothetical USDEGP price using CIB receipts price in London Stock Exchange and its price in EGX. Values are smoothed.

Tims Smart Money COT-IndexThe **Tims Smart Money COT Index** analyzes the positions of different groups of market participants from the COT report (Commercials, Large Specs, Small Specs). It calculates their net positions and scales them relative to extremes of the last 24 weeks. It indicates bullish and bearish zones to identify market sentiments.
- Commercials (Smart Money)**: Often act against the trend, bullish from 80+.
- Large Specs (Retail Money)**: Trend-following, bullish from 80+.
- Small Specs**: Mostly impulsive, bullish from 80+.
The indicator helps to identify turning points in the market based on the behavior of the players.

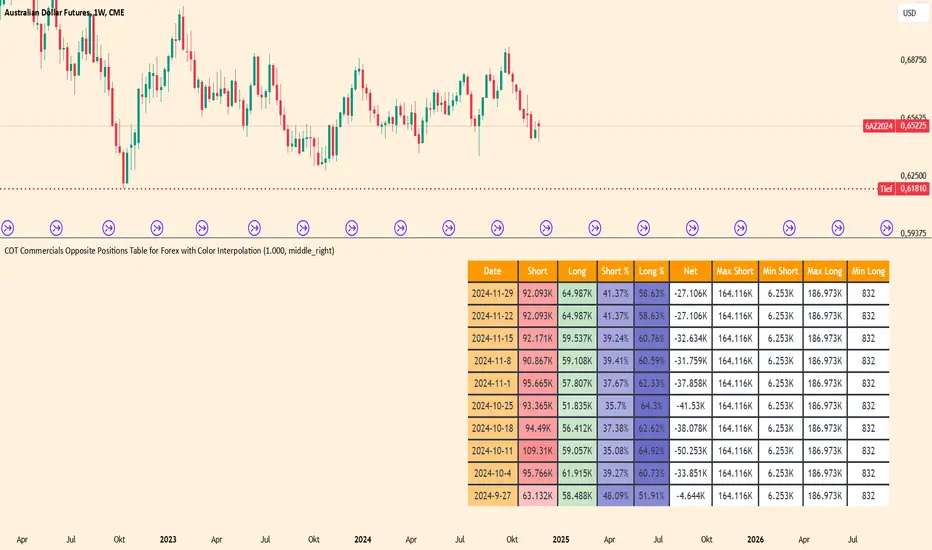
COT Commercials Positions Table Der COT Commercials Opposite Positions Table for Forex ist ein umfangreicher TradingView-Indikator, der die Positionen der kommerziellen Marktteilnehmer (Commercials) im Rahmen des Commitments of Traders (COT)-Berichts darstellt. Er zeigt Long-, Short-, und Netto-Positionen sowie deren prozentuale Anteile für ausgewählte Märkte an.
Hauptmerkmale:
Datenquellenwahl: Unterstützt "Futures Only" und "Futures and Options".
Marktabdeckung: Umfasst Währungen, Rohstoffe, Indizes und Kryptowährungen.
Farbkodierung: Dynamische Farbverläufe zur Hervorhebung von Extremen bei Long-/Short-Positionen und Prozentsätzen.
Historische Daten: Zeigt Positionsdaten der letzten 10 Wochen an.
Anpassbare Tabelle: Klar strukturiert mit wichtigen Kennzahlen wie max./min. Positionen und Netto-Positionen.
Der Indikator ist besonders für Trader nützlich, die Marktstimmungen analysieren und Positionierungen großer Marktteilnehmer in ihre Handelsentscheidungen einbeziehen möchten.
Der Indikator ist hauptsächlich für Futures gedacht und funktioniert nur im 1 Woche Chart.
MA Ratio Weighted Trend System I [InvestorUnknown]The MA Ratio Weighted Trend System I combines slow and fast indicators to identify stable trends and capture potential market turning points. By dynamically adjusting the weight of fast indicators based on the Moving Average Ratio (MAR), the system aims to provide timely entry and exit signals while maintaining overall trend stability through slow indicators.
Slow and Fast Indicators with Dynamic Weighting
Slow Indicators: Designed for stable trend identification, these indicators maintain a constant weight in the overall signal calculation. They include:
DMI For Loop (Directional Movement Index)
CCI For Loop (Commodity Channel Index)
Aroon For Loop
Fast Indicators: Aim to detect rapid market changes and potential turning points. Their weights are dynamically adjusted based on the absolute value of the Moving Average Ratio (MAR). Fast indicators include:
ZLEMA For Loop (Zero-Lag Exponential Moving Average)
IIRF For Loop (Infinite Impulse Response Filter)
Dynamic Weighting Mechanism:
Moving Average Ratio (MAR) is calculated as the ratio of the price to its moving average, minus one (for simplicity and visualization).
Weight Calculation
Fast indicator weights are determined based on the absolute value of MAR, possibly with an offset to avoid scenarios where MAR follows rapid price reversals too closely:
// Function to calculate weights based on MAR
f_mar_weights(series float mar, simple int offset, simple float weight_thre) =>
o_mar = math.abs(mar )
float fast_weight = 0
float slow_weight = 1
if o_mar != 0
if weight_thre > 0
if o_mar <= weight_thre
fast_weight := o_mar
else
fast_weight := o_mar
Threshold-Based vs. Continuous Weighting:
Threshold-Based: Fast indicators receive weight only when the absolute MAR exceeds a user-defined threshold (weight_thre).
Continuous: By setting weight_thre to zero, fast indicators always receive some weight, though this may increase false signals.
Offset Mechanism
The offset parameter shifts the MAR used for weighting by a certain number of bars. This helps avoid situations where the MAR follows sudden price movements too closely, preventing fast indicators from failing to provide timely exit signals.
Signal Calculation
The final signal is a weighted average of the slow and fast indicators:
// Calculate Signal (as weighted average)
float sig = math.round(((DMI*slow_w) + (CCI*slow_w) + (Aroon*slow_w) + (ZLEMA*fast_w) + (IIRF*fast_w)) / (3*slow_w + 2*fast_w), 2)
Backtesting and Performance Metrics
Enables users to test the indicator's performance over historical data, comparing it to a buy-and-hold strategy.
Alerts
Set up alerts for when the signal crosses above or below the thresholds.
alertcondition(long_alert, "LONG (MAR Weighted Trend System)", "MAR Weighted Trend System flipped ⬆LONG⬆")
alertcondition(short_alert, "SHORT (MAR Weighted Trend System)", "MAR Weighted Trend System flipped ⬇Short⬇")
Important Notes
Customization: Due to the experimental nature of this indicator, users are strongly encouraged to adjust and calibrate the settings to align with their trading strategies and market conditions.
Default Settings Disclaimer: The default settings are not optimized or recommended for any specific use and serve only as placeholders for the indicator's publication.
Backtest Results Disclaimer: Historical backtest results are not indicative of future performance. Market conditions change, and past results do not guarantee future outcomes.
Sharpe Ratio Z-ScoreThe "Sharpe Ratio Z-Score" indicator is a powerful tool designed to measure risk-adjusted returns in financial assets. This script helps investors evaluate the performance of a security relative to its risk, using a Z-score based modification of the Sharpe Ratio. The indicator is suitable for assessing market environments and understanding periods of underperformance or overperformance relative to historical standards.
Features:
Risk Assessment and Scaling: The indicator calculates a modified version of the Sharpe Ratio
over a user-defined period. By using scaling and mean offset adjustments, it allows for better
fitting to different market conditions.
Customizable Settings:
Period Length: The number of bars used to calculate the Sharpe Ratio.
Mean Adjustment: Offset value to adjust the average return of the calculated Sharpe ratio.
Scale Factor: A multiplier for emphasizing or reducing the calculated score's impact.
Line Color: Easily customize the plot's appearance.
Visual Cues:
Plots horizontal lines and fills specific regions to visually represent significant Z-score levels.
Highlighted zones include risk thresholds, such as overbought (positive Z-scores) and oversold
(negative Z-scores) areas, using intuitive color fills:
Green for areas below -0.5 (potential buy opportunities).
Red for areas above 0.5 (potential sell opportunities).
Yellow for neutral zones between -0.5 and 0.5.
Use Cases:
Risk-Adjusted Decision Making: Understand when returns are favorable compared to risk, especially during volatile market conditions.
Timing Reversion to Mean: Use highlighted zones to identify potential reversion-to-mean scenarios.
Trend Analysis: Identify times when an asset's performance is significantly deviating from its
average risk-adjusted return.
How It Works:
The script computes the daily returns over a set period, calculates the standard deviation of
those returns, and then applies a modified Sharpe Ratio approach. The Z-score transformation
helps to visualize how far an asset's risk-adjusted return deviates from its historical average.
This "Sharpe Ratio Z-Score" indicator is well-suited for investors seeking to combine quantitative metrics with visual cues, enhancing decision-making for long and short positions while maintaining a risk-adjusted perspective.
Conditional Value at Risk (CVaR)This Pine Script implements the Conditional Value at Risk (CVaR), a risk metric that evaluates the potential losses in a financial portfolio beyond a certain confidence level, incorporating both the Value at Risk (VaR) and the expected loss given that the VaR threshold has been breached.
Key Features:
Input Parameters:
length: Defines the observation period in days (default is 252, typically used to represent the number of trading days in a year).
confidence: Specifies the confidence interval for calculating VaR and CVaR, with values between 0.5 and 0.99 (default is 0.95, indicating a 95% confidence level).
Logarithmic Returns Calculation: The script computes the logarithmic returns based on the daily closing prices, a common method to measure financial asset returns, given by:
Log Return=ln(PtPt−1)
Log Return=ln(Pt−1Pt)
where PtPt is the price at time tt, and Pt−1Pt−1 is the price at the previous time point.
VaR Calculation: Value at Risk (VaR) is estimated as the percentile of the returns array corresponding to the given confidence interval. This represents the maximum loss expected over a given time horizon under normal market conditions at the specified confidence level.
CVaR Calculation: The Conditional VaR (CVaR) is calculated as the average of the returns that fall below the VaR threshold. This represents the expected loss given that the loss has exceeded the VaR threshold.
Visualization: The script plots two key risk measures:
VaR: The maximum potential loss at the specified confidence level.
CVaR: The average of the losses beyond the VaR threshold.
The script also includes a neutral line at zero to help visualize the losses and their magnitude.
Source and Scientific Background:
The concept of Value at Risk (VaR) was popularized by J.P. Morgan in the 1990s, and it has since become a widely-used tool for risk management (Jorion, 2007). Conditional Value at Risk (CVaR), also known as Expected Shortfall, addresses the limitation of VaR by considering the severity of losses beyond the VaR threshold (Rockafellar & Uryasev, 2002). CVaR provides a more comprehensive risk measure, especially in extreme tail risk scenarios.
References:
Jorion, P. (2007). Value at Risk: The New Benchmark for Managing Financial Risk. McGraw-Hill Education.
Rockafellar, R.T., & Uryasev, S. (2002). Conditional Value-at-Risk for General Loss Distributions. Journal of Banking & Finance, 26(7), 1443–1471.

Manual Trading Checklist by Afnan TajuddinHey traders! This Trading Checklist indicator like your personal to-do list right on your chart! Here’s what it does:
Easy Tracking: Seven checkboxes to make sure you’ve done all your trading steps.
Colorful Signs: Green "✔" for done stuff and red "✘" for things you need to fix.
Make It Yours: Change where the table is on the chart, pick your favorite colors, and set the text size just how you like it.
Simple Setup: Rename the checklist items and toggle them on or off in the settings.
Clean Look: It stays neat on your chart without messing things up.
Whether you’re just starting out or you’ve been trading for a while, this checklist helps you stay organized and stick to your plan. Perfect for anyone who loves keeping things tidy and on track!
Important to Know: This checklist is not dynamic or automatic and not specific to any symbol. You need to manually check it every time for all the stocks you’re planning to trade. It won’t do the checking for you, so make sure to update it yourself! 🚨

RHR_CANDLELibrary "RHR_CANDLE"
Library for Expansion Contraction Indicator, a zero-lag dual perspective indicator based on Jake Bernstein’s principles of Moving Average Channel system.
calc(shortLookback, longLookback)
Calculates Expansion Contraction values.
Parameters:
shortLookback (int) : Integer for the short lookback calculation, defaults to 8
longLookback (int) : Integer for the long lookback calculation, defaults to 32
@return Returns array of Expansion Contraction values
stdevCalc(positiveShort, negativeShort, positiveLong, negativeLong, stdevLookback)
Calculates standard deviation lines based on Expansion Contraction Long and Short values.
Parameters:
positiveShort (float) : Float for the positive short XC value from calculation
negativeShort (float) : Float for the negative short XC value from calculation
positiveLong (float) : Float for the positive long XC value from calculation
negativeLong (float) : Float for the negative long XC value from calculation
stdevLookback (int) : Integer for the standard deviation lookback, defaults to 500
@return Returns array of standard deviation values
trend(positiveShort, negativeShort, positiveLong, negativeLong)
Determines if trend is strong or weak based on Expansion Contraction values.
Parameters:
positiveShort (float) : Float for the positive short XC value from calculation
negativeShort (float) : Float for the negative short XC value from calculation
positiveLong (float) : Float for the positive long XC value from calculation
negativeLong (float) : Float for the negative long XC value from calculation
@return Returns array of boolean values indicating strength or weakness of trend

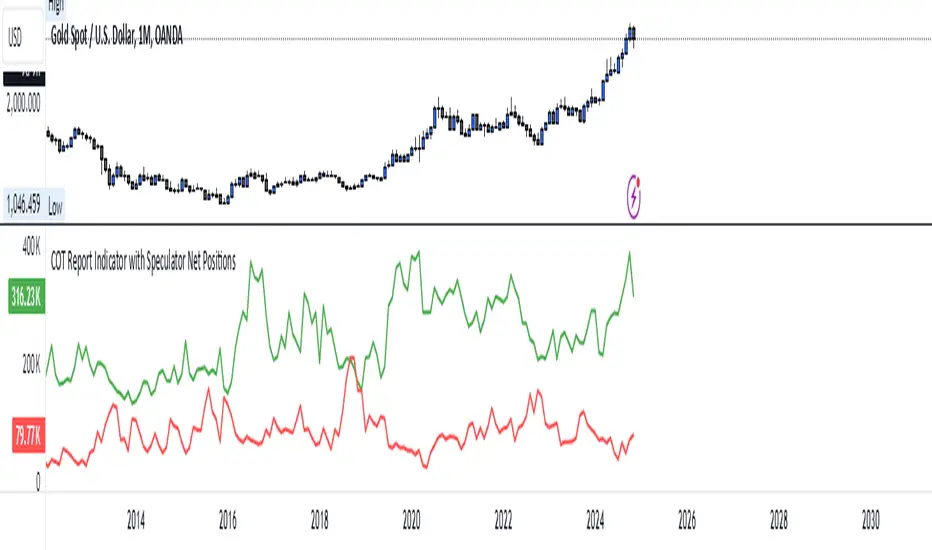
COT Report Indicator with Speculator Net PositionsThe COT Report Indicator with Speculator Net Positions is designed to give traders insights into the behavior of large market participants, particularly speculators, based on the Commitment of Traders (COT) report data. This indicator visualizes the long and short positions of non-commercial traders, allowing users to gauge the sentiment and positioning of large speculators in key markets, such as Gold, Silver, Crude Oil, S&P 500, and currency pairs like EURUSD, GBPUSD, and others.
The indicator provides three essential components:
Net Long Position (Green) - Displays the total long positions held by speculators.
Net Short Position (Purple) - Shows the total short positions held by speculators.
Net Difference (Long - Short) (Yellow) - Illustrates the difference between long and short positions, helping users identify whether speculators are more bullish or bearish on the asset.
Recommended Timeframes:
Best Timeframes: Weekly and Monthly
The COT report data is released on a weekly basis, making higher timeframes like the Weekly and Monthly charts ideal for this indicator. These timeframes provide a more accurate reflection of the underlying trends in speculator positioning, avoiding the noise present in lower timeframes.
How to Use:
Market Sentiment: Use this indicator to gauge the sentiment of large speculators, who often drive market trends. A strong net long position can indicate bullish sentiment, while a high net short position might suggest bearish sentiment.
Trend Reversal Signals: Sudden changes in the net difference between long and short positions may indicate potential trend reversals.
Confirmation Tool: Pair this indicator with your existing analysis to confirm the strength of a trend or identify overbought/oversold conditions based on speculator activity.
Supported Symbols:
This indicator currently supports a range of commodities and currency pairs, including:
Gold ( OANDA:XAUUSD )
Silver ( OANDA:XAGUSD )
Crude Oil ( TVC:USOIL )
Natural Gas ( NYMEX:NG1! )
S&P 500 ( SP:SPX )
Dollar Index ( TVC:DXY )
EURUSD ( FX:EURUSD )
GBPUSD ( FX:GBPUSD )
GBPJPY( FX:GBPJPY )
By providing clear insight into the positions of large speculators, this indicator is a powerful tool for traders looking to align with institutional sentiment and enhance their trading strategy.