Useful_lib_publicLibrary "Useful_lib_public"
Useful functions
CountBarsOfDay()
count bars for one for the diffrent time frames
Returns: number of bars for one day
LastBarsOfDay()
Index number for the las bar for one day
Returns: TRUE is that the last bar from day
isTuesday()
TRUE is tuesday
Returns: TRUE is tuesday else FALSE
Rsi(src, len)
RSI calulation
Parameters:
src (float) : RSI Source
len (simple int) : RSI Length
Returns: RSI Value
CalcIndex(netPos, weeks)
Index calulation
Parameters:
netPos (float) : Source
weeks (simple int) : Length
Returns: "COT Index"
RsiStock(src, len, smoothK)
TRUE is tuesday
Parameters:
src (float)
len (simple int)
smoothK (int)
Returns: RSI Stochastik
Offset()
Use Offset for Day time frame
Returns: Offset
PercentChange(Data, LastData)
Calc different in Percent
Parameters:
Data (float)
LastData (float)
Returns: Change in percent
Statistics

Dynamic Date and Price Tracker with Entry PriceThe Dynamic Date and Price Tracker indicator is a simple tool designed for traders to visualize and monitor their trade's progress in real-time from a specified starting point.
This tool provides an intuitive graphical representation of your trade's profitability based on a custom entry date and price.
Features:
-Starting Date Selection: Choose a specific starting date, after which the indicator begins tracking your trade's performance.
-Custom Entry Price: Input a starting price to accurately reflect your actual entry price for performance tracking across different timeframes.
-Real-Time Tracking: As new bars form, the indicator automatically adjusts a dynamic line to the current closing price.
-Profit/Loss Color Coding: The dynamic line color changes based on whether the current price is above (green for profit) or below (red for loss) your specified entry price.
-Performance Label: A real-time label displays the absolute and percentage change in price since your initial entry, color-coded for positive (green) or negative (red) performance.
-Entry Price Line: The horizontal line marks your starting price for easy visual comparison.

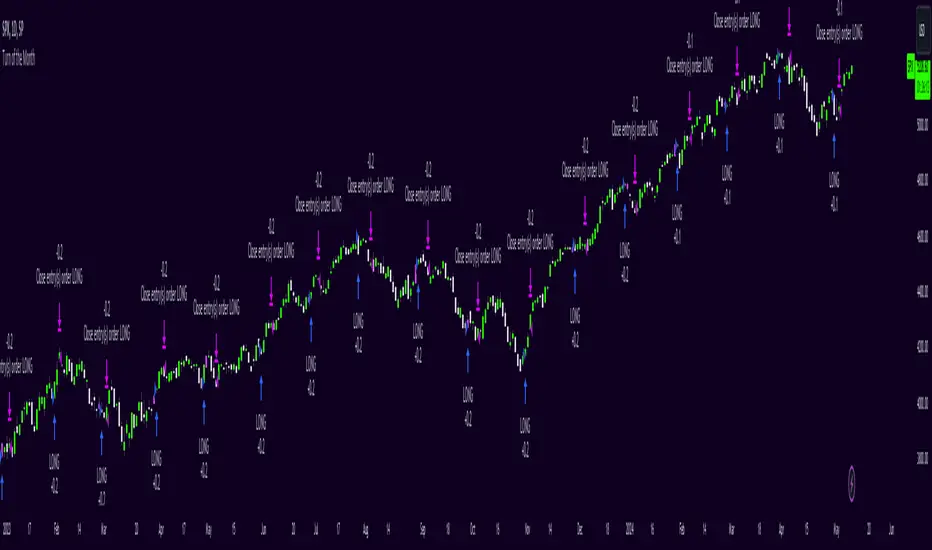
Turn of the Month Strategy [Honestcowboy]The end of month effect is a well known trading strategy in the stock market. Quite simply, most stocks go up at the end of the month. What's even better is that this effect spills over to the next phew days of the next month.
In this script we backtest this theory which should work especially well on SP500 pair.
By default the strategy buys 2 days before the end of each month and exits the position 3 days into the next month.
The strategy is a long only strategy and is extremely simple. The SP500 is one of the #1 assets people use for long term investing due to it's "9.8%" annualised return. However as a trader you want the best deal possible. This strategy is only inside the market for about 25% of the time while delivering a similar return per exposure with a lower drawdown.
Here are some hypothesis why turn of the month effect happens in the stock markets:
Increased inflow from savings accounts to stocks at end of month
Rebalancing of portfolios by fund managers at end of month
The timing of monthly cash flows received by pension funds, which are reinvested in the stock market.
The script also has some inputs to define how many days before end of the month you want to buy the asset and how long you want to hold it into the next month.
It is not possible to buy the asset exactly on this day every month as the market closes on the weekend. I've added some logic where it will check if that day is a friday, saturdady or sunday. If that is the case it will send the buy signal on the end of thursday, this way we enter on the friday and don't lose that months trading opportunity.
The backtest below uses 4% exposure per trade as to show the equity curve more clearly and because of publishing rules. However, most fund managers and investors use 100% exposure. This way you actually risk money to earn money. Feel free to adjust the settings to your risk profile to get a clearer picture of risks and rewards before implementing in your portfolio.
strategy_helpersThis library is designed to aid traders and developers in calculating risk metrics efficiently across different asset types like equities, futures, and forex. It includes comprehensive functions that calculate the number of units or contracts to trade, the value at risk, and the total value of the position based on provided entry prices, stop levels, and risk percentages. Whether you're managing a portfolio or developing trading strategies, this library provides essential tools for risk management. Functions also automatically select the appropriate risk calculation method based on asset type, calculate leverage levels, and determine potential liquidation points for leveraged positions. Perfect for enhancing the precision and effectiveness of your trading strategies.
Library "strategy_helpers"
Provides tools for calculating risk metrics across different types of trading strategies including equities, futures, and forex. Functions allow for precise control over risk management by calculating the number of units or contracts to trade, the value at risk, and the total position value based on entry prices, stop levels, and desired risk percentage. Additional utilities include automatic risk calculation based on asset type, leverage level calculations, and determination of liquidation levels for leveraged trades.
calculate_risk(entry, stop_level, stop_range, capital, risk_percent, trade_direction, whole_number_buy)
Calculates risk metrics for equity trades based on entry, stop level, and risk percent
Parameters:
entry (float) : The price at which the position is entered. Use close if you arent adding to a position. Use the original entry price if you are adding to a position.
stop_level (float) : The price level where the stop loss is placed
stop_range (float) : The price range from entry to stop level
capital (float) : The total capital available for trading
risk_percent (float) : The percentage of capital risked on the trade. 100% is represented by 100.
trade_direction (bool) : True for long trades, false for short trades
whole_number_buy (bool) : True to adjust the quantity to whole numbers
Returns: A tuple containing the number of units to trade, the value at risk, and the total value of the position:
calculate_risk_futures(risk_capital, stop_range)
Calculates risk metrics for futures trades based on the risk capital and stop range
Parameters:
risk_capital (float) : The capital allocated for the trade
stop_range (float) : The price range from entry to stop level
Returns: A tuple containing the number of contracts to trade, the value at risk, and the total value of the position:
calculate_risk_forex(entry, stop_level, stop_range, capital, risk_percent, trade_direction)
Calculates risk metrics for forex trades based on entry, stop level, and risk percent
Parameters:
entry (float) : The price at which the position is entered. Use close if you arent adding to a position. Use the original entry price if you are adding to a position.
stop_level (float) : The price level where the stop loss is placed
stop_range (float) : The price range from entry to stop level
capital (float) : The total capital available for trading
risk_percent (float) : The percentage of capital risked on the trade. 100% is represented by 100.
trade_direction (bool) : True for long trades, false for short trades
Returns: A tuple containing the number of lots to trade, the value at risk, and the total value of the position:
calculate_risk_auto(entry, stop_level, stop_range, capital, risk_percent, trade_direction, whole_number_buy)
Automatically selects the risk calculation method based on the asset type and calculates risk metrics
Parameters:
entry (float) : The price at which the position is entered. Use close if you arent adding to a position. Use the original entry price if you are adding to a position.
stop_level (float) : The price level where the stop loss is placed
stop_range (float) : The price range from entry to stop level
capital (float) : The total capital available for trading
risk_percent (float) : The percentage of capital risked on the trade. 100% is represented by 100.
trade_direction (bool) : True for long trades, false for short trades
whole_number_buy (bool) : True to adjust the quantity to whole numbers, applicable only for non-futures and non-forex trades
Returns: A tuple containing the number of units or contracts to trade, the value at risk, and the total value of the position:
leverage_level(account_equity, position_value)
Calculates the leverage level used based on account equity and position value
Parameters:
account_equity (float) : Total equity in the trading account
position_value (float) : Total value of the position taken
Returns: The leverage level used in the trade
calculate_liquidation_level(entry, leverage, trade_direction, maintenance_margine)
Calculates the liquidation price level for a leveraged trade
Parameters:
entry (float) : The price at which the position is entered
leverage (float) : The leverage level used in the trade
trade_direction (bool) : True for long trades, false for short trades
maintenance_margine (float) : The maintenance margin requirement, expressed as a percentage
Returns: The price level at which the position would be liquidated, or na if leverage is zero

US Net LiquidityAnalysis of US Net Liquidity: A Comprehensive Overview
Introduction:
The "US Net Liquidity" indicator offers a detailed analysis of liquidity conditions within the United States, drawing insights from critical financial metrics related to the Federal Reserve (FED) and other government accounts. This tool enables economists to assess liquidity dynamics, identify trends, and inform economic decision-making.
Key Metrics and Interpretation:
1. Smoothing Period: This parameter adjusts the level of detail in the analysis by applying a moving average to the liquidity data. A longer smoothing period results in a smoother trend line, useful for identifying broader liquidity patterns over time.
2. Data Source (Timeframe): Specifies the timeframe of the data used for analysis, typically daily (D). Different timeframes can provide varying perspectives on liquidity trends.
3. Data Categories:
- FED Balance Sheet: Represents the assets and liabilities of the Federal Reserve, offering insights into monetary policy and market interventions.
- US Treasury General Account (TGA): Tracks the balance of the US Treasury's general account, reflecting government cash management and financial stability.
- Overnight Reverse Repurchase Agreements (RRP): Highlights short-term borrowing and lending operations between financial institutions and the Federal Reserve, influencing liquidity conditions.
- Earnings Remittances to the Treasury: Indicates revenues transferred to the US Treasury from various sources, impacting government cash flow and liquidity.
4. Moving Average Length: Determines the duration of the moving average applied to the data. A longer moving average length smoothens out short-term fluctuations, emphasizing longer-term liquidity trends.
Variation Lookback Length: Specifies the historical period used to assess changes and variations in liquidity. A longer lookback length captures more extended trends and fluctuations.
Interpretation:
1. Data Retrieval: Real-time data from specified financial instruments (assets) is retrieved to calculate balances for each category (FED, TGA, RRP, Earnings Remittances).
2. Global Balance Calculation: The global liquidity balance is computed by aggregating the balances of individual categories (FED Balance - TGA Balance - RRP Balance - Earnings Remittances Balance). This metric provides a comprehensive view of net liquidity.
3. Smoothed Global Balance (SMA): The Simple Moving Average (SMA) is applied to the global liquidity balance to enhance clarity and identify underlying trends. A rising SMA suggests improving liquidity conditions, while a declining SMA may indicate tightening liquidity.
Insight Generation and Decision-Making:
1. Trend Analysis: By analyzing smoothed liquidity trends over time, economists can identify periods of liquidity surplus or deficit, which can inform monetary policy decisions and market interventions.
2. Forecasting: Understanding liquidity dynamics aids in economic forecasting, particularly in predicting market liquidity, interest rate movements, and financial stability.
3. Policy Implications: Insights derived from this analysis tool can guide policymakers in formulating effective monetary policies, managing government cash flow, and ensuring financial stability.
Conclusion:
The "US Net Liquidity" analysis tool serves as a valuable resource for economists, offering a data-driven approach to understanding liquidity dynamics within the US economy. By interpreting key metrics and trends, economists can make informed decisions and contribute to macroeconomic stability and growth.
Disclaimer: This analysis is based on real-time financial data and should be used for informational purposes only. It is not intended as financial advice or a substitute for professional expertise.

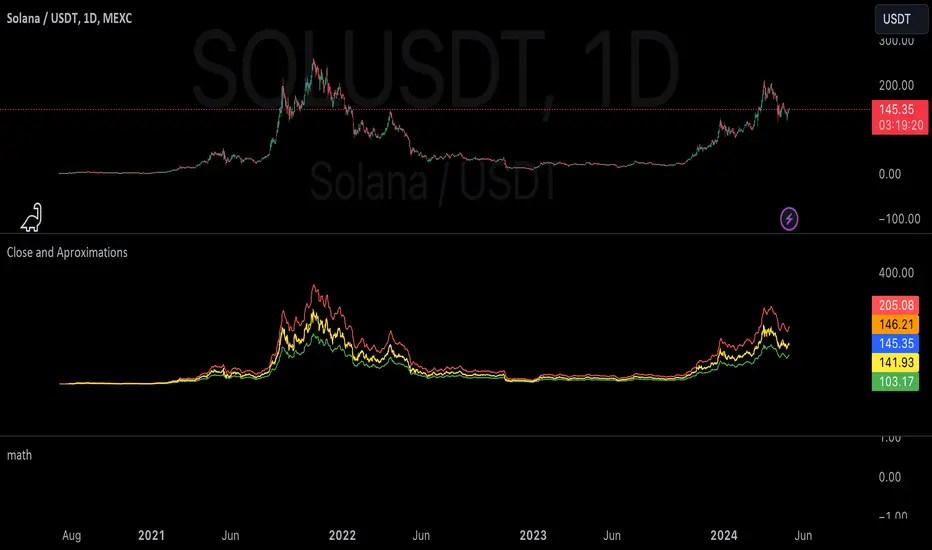
mathLibrary "math"
It's a library of discrete aproximations of a price or Series float it uses Fourier Discrete transform, Laplace Discrete Original and Modified transform and Euler's Theoreum for Homogenus White noice operations. Calling functions without source value it automatically take close as the default source value.
Here is a picture of Laplace and Fourier approximated close prices from this library:
Copy this indicator and try it yourself:
import AutomatedTradingAlgorithms/math/1 as math
//@version=5
indicator("Close Price with Aproximations", shorttitle="Close and Aproximations", overlay=false)
// Sample input data (replace this with your own data)
inputData = close
// Plot Close Price
plot(inputData, color=color.blue, title="Close Price")
ltf32_result = math.LTF32(a=0.01)
plot(ltf32_result, color=color.green, title="LTF32 Aproximation")
fft_result = math.FFT()
plot(fft_result, color=color.red, title="Fourier Aproximation")
wavelet_result = math.Wavelet()
plot(wavelet_result, color=color.orange, title="Wavelet Aproximation")
wavelet_std_result = math.Wavelet_std()
plot(wavelet_std_result, color=color.yellow, title="Wavelet_std Aproximation")
DFT3(xval, _dir)
Discrete Fourier Transform with last 3 points
Parameters:
xval (float) : Source series
_dir (int) : Direction parameter
Returns: Aproxiated source value
DFT2(xval, _dir)
Discrete Fourier Transform with last 2 points
Parameters:
xval (float) : Source series
_dir (int) : Direction parameter
Returns: Aproxiated source value
FFT(xval)
Fast Fourier Transform once. It aproximates usig last 3 points.
Parameters:
xval (float) : Source series
Returns: Aproxiated source value
DFT32(xval)
Combined Discrete Fourier Transforms of DFT3 and DTF2 it aproximates last point by first
aproximating last 3 ponts and than using last 2 points of the previus.
Parameters:
xval (float) : Source series
Returns: Aproxiated source value
DTF32(xval)
Combined Discrete Fourier Transforms of DFT3 and DTF2 it aproximates last point by first
aproximating last 3 ponts and than using last 2 points of the previus.
Parameters:
xval (float) : Source series
Returns: Aproxiated source value
LFT3(xval, _dir, a)
Discrete Laplace Transform with last 3 points
Parameters:
xval (float) : Source series
_dir (int) : Direction parameter
a (float) : laplace coeficient
Returns: Aproxiated source value
LFT2(xval, _dir, a)
Discrete Laplace Transform with last 2 points
Parameters:
xval (float) : Source series
_dir (int) : Direction parameter
a (float) : laplace coeficient
Returns: Aproxiated source value
LFT(xval, a)
Fast Laplace Transform once. It aproximates usig last 3 points.
Parameters:
xval (float) : Source series
a (float) : laplace coeficient
Returns: Aproxiated source value
LFT32(xval, a)
Combined Discrete Laplace Transforms of LFT3 and LTF2 it aproximates last point by first
aproximating last 3 ponts and than using last 2 points of the previus.
Parameters:
xval (float) : Source series
a (float) : laplace coeficient
Returns: Aproxiated source value
LTF32(xval, a)
Combined Discrete Laplace Transforms of LFT3 and LTF2 it aproximates last point by first
aproximating last 3 ponts and than using last 2 points of the previus.
Parameters:
xval (float) : Source series
a (float) : laplace coeficient
Returns: Aproxiated source value
whitenoise(indic_, _devided, minEmaLength, maxEmaLength, src)
Ehler's Universal Oscillator with White Noise, without extra aproximated src.
It uses dinamic EMA to aproximate indicator and thus reducing noise.
Parameters:
indic_ (float) : Input series for the indicator values to be smoothed
_devided (int) : Divisor for oscillator calculations
minEmaLength (int) : Minimum EMA length
maxEmaLength (int) : Maximum EMA length
src (float) : Source series
Returns: Smoothed indicator value
whitenoise(indic_, dft1, _devided, minEmaLength, maxEmaLength, src)
Ehler's Universal Oscillator with White Noise and DFT1.
It uses src and sproxiated src (dft1) to clearly define white noice.
It uses dinamic EMA to aproximate indicator and thus reducing noise.
Parameters:
indic_ (float) : Input series for the indicator values to be smoothed
dft1 (float) : Aproximated src value for white noice calculation
_devided (int) : Divisor for oscillator calculations
minEmaLength (int) : Minimum EMA length
maxEmaLength (int) : Maximum EMA length
src (float) : Source series
Returns: Smoothed indicator value
smooth(dft1, indic__, _devided, minEmaLength, maxEmaLength, src)
Smoothing source value with help of indicator series and aproximated source value
It uses src and sproxiated src (dft1) to clearly define white noice.
It uses dinamic EMA to aproximate src and thus reducing noise.
Parameters:
dft1 (float) : Value to be smoothed.
indic__ (float) : Optional input for indicator to help smooth dft1 (default is FFT)
_devided (int) : Divisor for smoothing calculations
minEmaLength (int) : Minimum EMA length
maxEmaLength (int) : Maximum EMA length
src (float) : Source series
Returns: Smoothed source (src) series
smooth(indic__, _devided, minEmaLength, maxEmaLength, src)
Smoothing source value with help of indicator series
It uses dinamic EMA to aproximate src and thus reducing noise.
Parameters:
indic__ (float) : Optional input for indicator to help smooth dft1 (default is FFT)
_devided (int) : Divisor for smoothing calculations
minEmaLength (int) : Minimum EMA length
maxEmaLength (int) : Maximum EMA length
src (float) : Source series
Returns: Smoothed src series
vzo_ema(src, len)
Volume Zone Oscillator with EMA smoothing
Parameters:
src (float) : Source series
len (simple int) : Length parameter for EMA
Returns: VZO value
vzo_sma(src, len)
Volume Zone Oscillator with SMA smoothing
Parameters:
src (float) : Source series
len (int) : Length parameter for SMA
Returns: VZO value
vzo_wma(src, len)
Volume Zone Oscillator with WMA smoothing
Parameters:
src (float) : Source series
len (int) : Length parameter for WMA
Returns: VZO value
alma2(series, windowsize, offset, sigma)
Arnaud Legoux Moving Average 2 accepts sigma as series float
Parameters:
series (float) : Input series
windowsize (int) : Size of the moving average window
offset (float) : Offset parameter
sigma (float) : Sigma parameter
Returns: ALMA value
Wavelet(src, len, offset, sigma)
Aproxiates srt using Discrete wavelet transform.
Parameters:
src (float) : Source series
len (int) : Length parameter for ALMA
offset (simple float)
sigma (simple float)
Returns: Wavelet-transformed series
Wavelet_std(src, len, offset, mag)
Aproxiates srt using Discrete wavelet transform with standard deviation as a magnitude.
Parameters:
src (float) : Source series
len (int) : Length parameter for ALMA
offset (float) : Offset parameter for ALMA
mag (int) : Magnitude parameter for standard deviation
Returns: Wavelet-transformed series
LaplaceTransform(xval, N, a)
Original Laplace Transform over N set of close prices
Parameters:
xval (float) : series to aproximate
N (int) : number of close prices in calculations
a (float) : laplace coeficient
Returns: Aproxiated source value
NLaplaceTransform(xval, N, a, repeat)
Y repetirions on Original Laplace Transform over N set of close prices, each time N-k set of close prices
Parameters:
xval (float) : series to aproximate
N (int) : number of close prices in calculations
a (float) : laplace coeficient
repeat (int) : number of repetitions
Returns: Aproxiated source value
LaplaceTransformsum(xval, N, a, b)
Sum of 2 exponent coeficient of Laplace Transform over N set of close prices
Parameters:
xval (float) : series to aproximate
N (int) : number of close prices in calculations
a (float) : laplace coeficient
b (float) : second laplace coeficient
Returns: Aproxiated source value
NLaplaceTransformdiff(xval, N, a, b, repeat)
Difference of 2 exponent coeficient of Laplace Transform over N set of close prices
Parameters:
xval (float) : series to aproximate
N (int) : number of close prices in calculations
a (float) : laplace coeficient
b (float) : second laplace coeficient
repeat (int) : number of repetitions
Returns: Aproxiated source value
N_divLaplaceTransformdiff(xval, N, a, b, repeat)
N repetitions of Difference of 2 exponent coeficient of Laplace Transform over N set of close prices, with dynamic rotation
Parameters:
xval (float) : series to aproximate
N (int) : number of close prices in calculations
a (float) : laplace coeficient
b (float) : second laplace coeficient
repeat (int) : number of repetitions
Returns: Aproxiated source value
LaplaceTransformdiff(xval, N, a, b)
Difference of 2 exponent coeficient of Laplace Transform over N set of close prices
Parameters:
xval (float) : series to aproximate
N (int) : number of close prices in calculations
a (float) : laplace coeficient
b (float) : second laplace coeficient
Returns: Aproxiated source value
NLaplaceTransformdiffFrom2(xval, N, a, b, repeat)
N repetitions of Difference of 2 exponent coeficient of Laplace Transform over N set of close prices, second element has for 1 higher exponent factor
Parameters:
xval (float) : series to aproximate
N (int) : number of close prices in calculations
a (float) : laplace coeficient
b (float) : second laplace coeficient
repeat (int) : number of repetitions
Returns: Aproxiated source value
N_divLaplaceTransformdiffFrom2(xval, N, a, b, repeat)
N repetitions of Difference of 2 exponent coeficient of Laplace Transform over N set of close prices, second element has for 1 higher exponent factor, dynamic rotation
Parameters:
xval (float) : series to aproximate
N (int) : number of close prices in calculations
a (float) : laplace coeficient
b (float) : second laplace coeficient
repeat (int) : number of repetitions
Returns: Aproxiated source value
LaplaceTransformdiffFrom2(xval, N, a, b)
Difference of 2 exponent coeficient of Laplace Transform over N set of close prices, second element has for 1 higher exponent factor
Parameters:
xval (float) : series to aproximate
N (int) : number of close prices in calculations
a (float) : laplace coeficient
b (float) : second laplace coeficient
Returns: Aproxiated source value
[BT] NedDavis Series: CPI Minus 5-Year Moving Average🟧 GENERAL
The script works on the Monthly Timeframe and has 2 main settings (explained in FEATURES ). It uses the US CPI data, reported by the Bureau of Labour Statistics.
🔹Functionality 1: The main idea is to plot the distance between the CPI line and the 5 year moving average of the CPI line. This technique in mathematics is called "deviation from the moving average". This technique is used to analyse how has CPI previously acted and can give clues at what it might do in the future. Economic historians use such analysis, together with specific period analysis to predict potential risks in the future (see an example of such analysis in HOW TO USE section. The mathematical technique is a simple subtraction between 2 points (CPI - 5yr SMA of CPI).
▶︎Interpretation for deviation from a moving average:
Positive Deviation: When the line is above its moving average, it indicates that the current value is higher than the average, suggesting potential strength or bullish sentiment.
Negative Deviation: Conversely, when the line falls below its moving average, it suggests weakness or bearish sentiment as the current value is lower than the average.
▶︎Applications:
Trend Identification: Deviations from moving averages can help identify trends, with sustained deviations indicating strong trends.
Reversal Signals: Significant deviations from moving averages may signal potential trend reversals, especially when combined with other technical indicators.
Volatility Measurement: Monitoring the magnitude of deviations can provide insights into market volatility and price movements.
Remember the indicator is applying this only for the US CPI - not the ticker you apply the indicator on!
🔹Functionality 2: It plots on a new pane below information about the Consumer Price Index. You can also find the information by plotting the ticker symbol USACPIALLMINMEI on TradingView, which is a Monthly economic data by the OECD for the CPI in the US. The only addition you would get from the indicator is the plot of the 5 year Simple Moving Average.
🔹What is the US Consumer Price Index?
Measures the change in the price of goods and services purchased by consumers;
Traders care about the CPI because consumer prices account for a majority of overall inflation. Inflation is important to currency valuation because rising prices lead the central bank to raise interest rates out of respect for their inflation containment mandate;
It is measured as the average price of various goods and services are sampled and then compared to the previous sampling.
Source: Bureau of Labor Statistics;
FEATURES OF INDICATOR
1) The US Consumer Price Index Minus the Five Year Moving Average of the same.
As shown on the picture above and explained in previous section. Here a more detailed view.
2) The actual US Consumer Price Index (Annual Rate of change) and the Five year average of the US Consumer Price Index. Explained above and shown below:
To activate 2) go into settings and toggle the check box.
HOW TO USE
It can be used for a fundamental analysis on the relationship between the stock market, the economy and the Feds decisions to hike or cut rates, whose main mandate is to control inflation over time.
I have created this indicator to show my analysis in this idea:
What does a First Fed Rate cut really mean?
CREDITS
I have seen such idea in the past posted by the institutional grade research of NedDavis and have recreated it for the TradingView platform, open-source for the community.

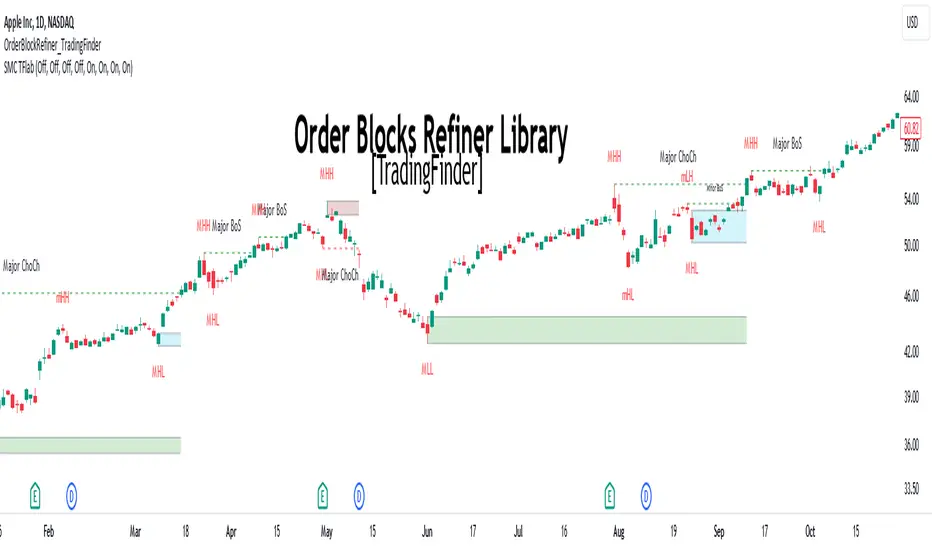
Order Block Refiner [TradingFinder]🔵 Introduction
The "Refinement" feature allows you to adjust the width of the order block according to your strategy. There are two modes, "Aggressive" and "Defensive," in the "Order Block Refine". The difference between "Aggressive" and "Defensive" lies in the width of the order block.
For risk-averse traders, the "Defensive" mode is suitable as it provides a lower loss limit and a greater reward-to-risk ratio. For risk-taking traders, the "Aggressive" mode is more appropriate. These traders prefer to enter trades at higher prices, and this mode, which has a wider order block width, is more suitable for this group of individuals.
Important :
One of the advantages of using this library is increased code accuracy. Not only does it have the capability to create order blocks, but you can also simply define the condition for order block creation (true/false) and "bar_index," and you'll find the primary range without applying any filters.
🟣 Order Block Refinement Algorithm
The order block ranges are filtered in two stages. In the first stage, the "Open," "High," "Low," and "Close" of the current order block candle, its two or three previous candles, and one subsequent candle (if available) are examined. In this stage, minimum and maximum distances are calculated, and logical range filters are applied.
In the second stage, two modes, "Aggressive" and "Defensive," are calculated.
For the "Defensive" mode, the width of these ranges is compared with the "ATR" (Average True Range) of period 55, and if they are smaller than "ATR" or 1 to more than 4 times "ATR," the width of the range is reduced from 0 to 80 percent.
For the "Aggressive" mode, you get the same output as the first filter, which usually has a wider width than the "Defensive" mode.
• Order Block Refiner : Off
• Order Block Refiner : On / "Aggressive Mode"
• Order Block Refiner : On / "Defensive Mode"
🔵 How to Use
OBRefiner(string OBType, string OBRefine, string RefineMethod, bool TriggerCondition, int Index) =>
Parameters:
• OBType (string)
• OBRefine (string)
• RefineMethod (string)
• TriggerCondition (bool)
• Index (int)
To add "Order Block Refiner Library", you must first add the following code to your script.
import TFlab/OrderBlockRefiner_TradingFinder/1
OBType : This parameter receives 2 inputs. If the order block you want to "Refine" is of type demand, you should enter "Demand," and if it's of type supply, you should enter "Supply."
OBRefine : Set to "On" if you want the "Refine" operation to be performed. Otherwise, set to "Off."
RefineMethod : This input receives 2 modes, "Aggressive" and "Defensive." You can switch between these modes according to your needs.
TriggerCondition : Enter the condition with which the order block is formed in this parameter.
Index : Enter the "bar_index" of the candle where the order block is formed in this parameter.
🟣 Function Outputs
This function has 6 outputs: "bar_index" at the beginning of the "Distal" line, "bar_index+1" at the end of the "Distal" line, "Price" at the "Distal" line, "bar_index" at the beginning of the "Proximal" line, "bar_index+1" at the end of the "Proximal" line, and "Price" at the "Proximal" line, which can be used to draw order blocks.
Sample :
= Refiner.OBRefiner('Demand', 'Off', 'Aggressive',BuMChMain_Trigger, BuMChMain_Index)
if BuMChMain_Trigger
BuMChHlineMain := line.new(BuMChMain_Xp1 , BuMChMain_Yp12 , bar_index , BuMChMain_Yp12, color = color.black , style = line.style_dotted)
BuMChLlineMain := line.new(BuMChMain_Xd1 , BuMChMain_Yd12 , bar_index , BuMChMain_Yd12, color = color.black , style = line.style_dotted)
BuMChFilineMain := linefill.new(BuMChHlineMain ,BuMChLlineMain , color = color.rgb(76, 175, 80 , 75 ) )
Monty3192_LibraryLibrary "Monty3192_Library"
Libreria Monty3192 - MontyTrader
calc_func(inversion1, inversion2, inversion3, inversion4, inversion5, inversion6, inversion7, inversion8, inversion9, inversion10, precio1, precio2, precio3, precio4, precio5, precio6, precio7, precio8, precio9, precio10, act_1, act_2, act_3, act_4, act_5, act_6, act_7, act_8, act_9, act_10)
Parameters:
inversion1 (float)
inversion2 (float)
inversion3 (float)
inversion4 (float)
inversion5 (float)
inversion6 (float)
inversion7 (float)
inversion8 (float)
inversion9 (float)
inversion10 (float)
precio1 (float)
precio2 (float)
precio3 (float)
precio4 (float)
precio5 (float)
precio6 (float)
precio7 (float)
precio8 (float)
precio9 (float)
precio10 (float)
act_1 (bool)
act_2 (bool)
act_3 (bool)
act_4 (bool)
act_5 (bool)
act_6 (bool)
act_7 (bool)
act_8 (bool)
act_9 (bool)
act_10 (bool)
rend_func(p1, p2, p3, p4, p5, p6, p7, p8, p9, p10, po)
Parameters:
p1 (float)
p2 (float)
p3 (float)
p4 (float)
p5 (float)
p6 (float)
p7 (float)
p8 (float)
p9 (float)
p10 (float)
po (float)
f_drawLine(cond, x1, y1, x2, y2, colorr, txt, act, offset, txtc, txts)
Parameters:
cond (bool)
x1 (int)
y1 (float)
x2 (int)
y2 (float)
colorr (color)
txt (string)
act (bool)
offset (int)
txtc (color)
txts (string)
f_Vline(cond, x1, y1, x2, y2, colorr, txt, sel, txts, txtc)
Parameters:
cond (bool)
x1 (int)
y1 (float)
x2 (int)
y2 (float)
colorr (color)
txt (string)
sel (bool)
txts (string)
txtc (color)
get_all_time_high()

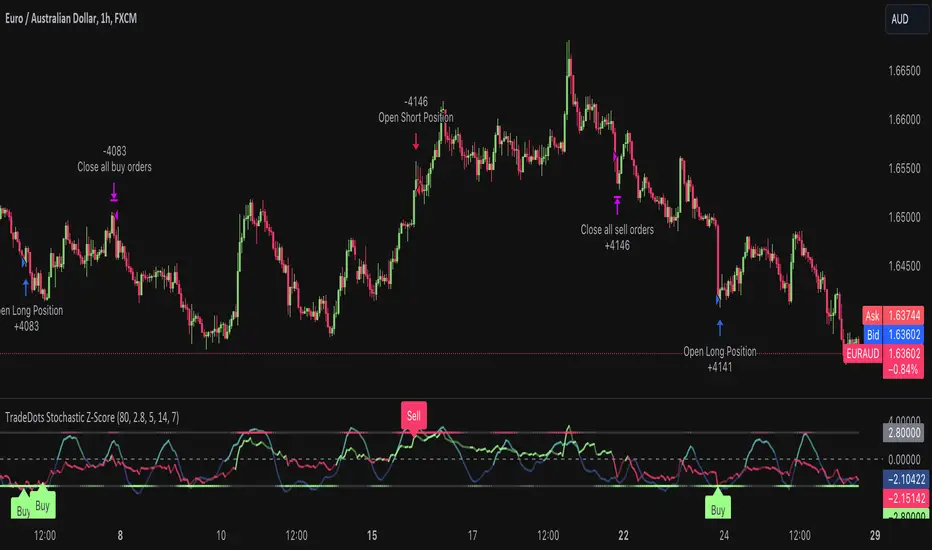
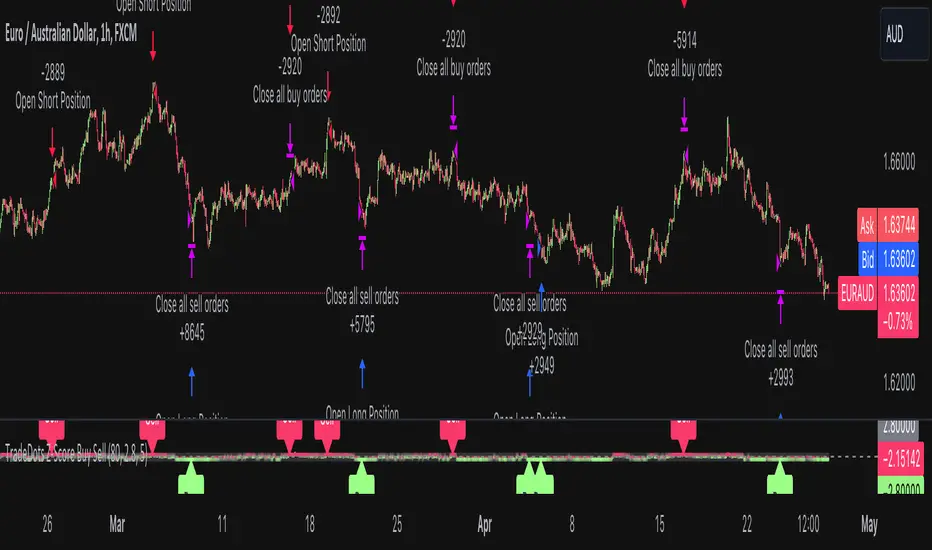
Stochastic Z-Score Oscillator Strategy [TradeDots]The "Stochastic Z-Score Oscillator Strategy" represents an enhanced approach to the original "Buy Sell Strategy With Z-Score" trading strategy. Our upgraded Stochastic model incorporates an additional Stochastic Oscillator layer on top of the Z-Score statistical metrics, which bolsters the affirmation of potential price reversals.
We also revised our exit strategy to when the Z-Score revert to a level of zero. This amendment gives a much smaller drawdown, resulting in a better win-rate compared to the original version.
HOW DOES IT WORK
The strategy operates by calculating the Z-Score of the closing price for each candlestick. This allows us to evaluate how significantly the current price deviates from its typical volatility level.
The strategy first takes the scope of a rolling window, adjusted to the user's preference. This window is used to compute both the standard deviation and mean value. With these values, the strategic model finalizes the Z-Score. This determination is accomplished by subtracting the mean from the closing price and dividing the resulting value by the standard deviation.
Following this, the Stochastic Oscillator is utilized to affirm the Z-Score overbought and oversold indicators. This indicator operates within a 0 to 100 range, so a base adjustment to match the Z-Score scale is required. Post Stochastic Oscillator calculation, we recalibrate the figure to lie within the -4 to 4 range.
Finally, we compute the average of both the Stochastic Oscillator and Z-Score, signaling overpriced or underpriced conditions when the set threshold of positive or negative is breached.
APPLICATION
Firstly, it is better to identify a stable trading pair for this technique, such as two stocks with considerable correlation. This is to ensure conformance with the statistical model's assumption of a normal Gaussian distribution model. The ideal performance is theoretically situated within a sideways market devoid of skewness.
Following pair selection, the user should refine the span of the rolling window. A broader window smoothens the mean, more accurately capturing long-term market trends, while potentially enhancing volatility. This refinement results in fewer, yet precise trading signals.
Finally, the user must settle on an optimal Z-Score threshold, which essentially dictates the timing for buy/sell actions when the Z-Score exceeds with thresholds. A positive threshold signifies the price veering away from its mean, triggering a sell signal. Conversely, a negative threshold denotes the price falling below its mean, illustrating an underpriced condition that prompts a buy signal.
Within a normal distribution, a Z-Score of 1 records about 68% of occurrences centered at the mean, while a Z-Score of 2 captures approximately 95% of occurrences.
The 'cool down period' is essentially the number of bars that await before the next signal generation. This feature is employed to dodge the occurrence of multiple signals in a short period.
DEFAULT SETUP
The following is the default setup on EURAUD 1h timeframe
Rolling Window: 80
Z-Score Threshold: 2.8
Signal Cool Down Period: 5
Stochastic Length: 14
Stochastic Smooth Period: 7
Commission: 0.01%
Initial Capital: $10,000
Equity per Trade: 40%
FURTHER IMPLICATION
The Stochastic Oscillator imparts minimal impact on the current strategy. As such, it may be beneficial to adjust the weightings between the Z-Score and Stochastic Oscillator values or the scale of Stochastic Oscillator to test different performance outcomes.
Alternative momentum indicators such as Keltner Channels or RSI could also serve as robust confirmations of overbought and oversold signals when used for verification.
RISK DISCLAIMER
Trading entails substantial risk, and most day traders incur losses. All content, tools, scripts, articles, and education provided by TradeDots serve purely informational and educational purposes. Past performances are not definitive predictors of future results.
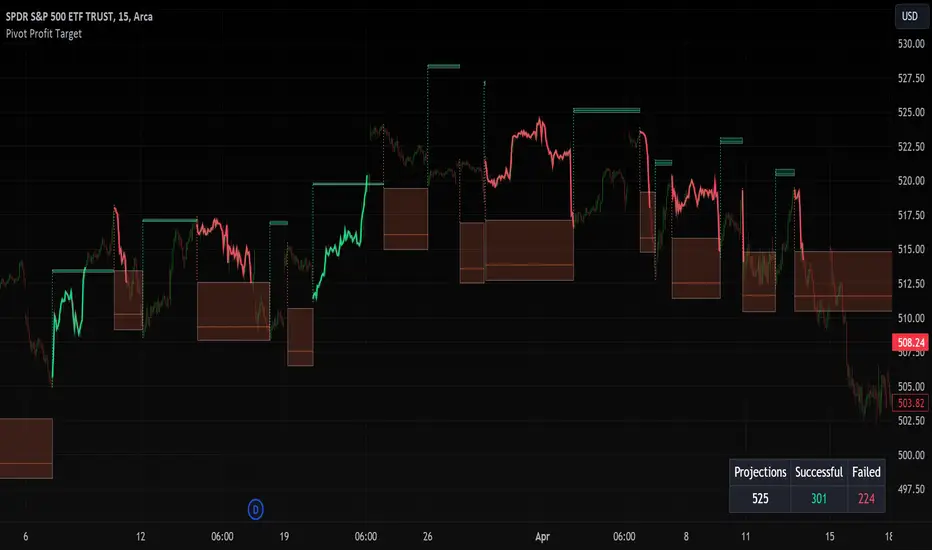
Pivot Profit Target [Mxwll]Introducing the Pivot Profit Target!
This script identifies recent pivot highs/lows and calculates the expected minimum distance for the next pivot, which acts as an approximate profit target.
The image above details the indicator's output.
The image above shows a table consisting of projection statistics.
How to use
The Pivot Profit Targets can be used to approximate a profit target for your trade.
Identify where your entry is relative to the most recent pivot, and assess whether the minimum expected distance for the most recent pivot has been exceeded. Treat the zones as an approximation.
If your trade aligns with the most recent pivot - treat the minimum expected distance zone as a potential profit target area. Of course, price might stop short or continue beyond the projection area!
That's it! Just a short and sweet script; thank you!
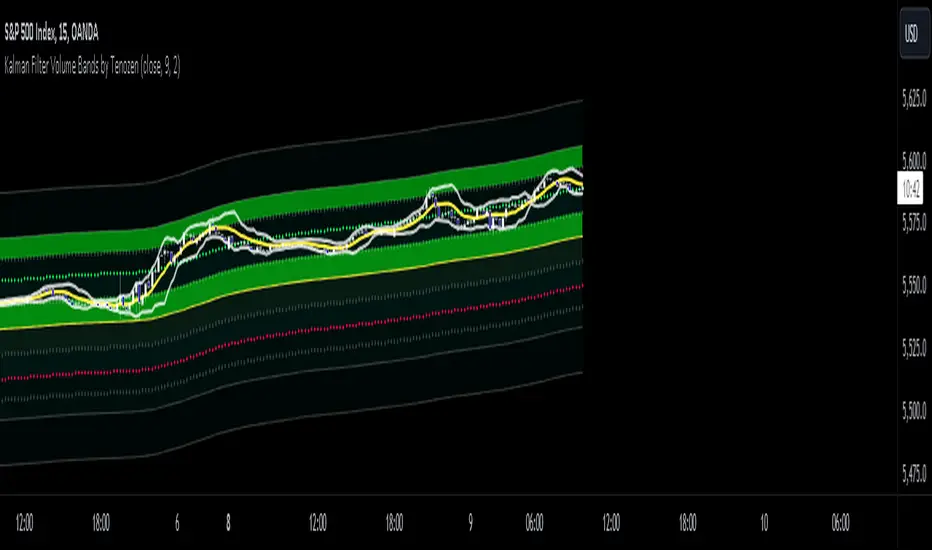
Kalman Filter Volume Bands by TenozenHello there! I am excited to introduce a new original indicator, the Kalman Filter Volume Bands. This indicator is calculated using the Kalman Filter, which is an adaptive-based smoothing quantitative tool. The Kalman Filter Volume Bands have two components that support the calculation, namely VWAP and VaR.
VWAP is used to determine the weight of the Kalman Filter Returns, but it doesn't have a significant impact on the calculation. On the other hand, VaR or Value at risk is calculated using the 99th percentile, which means that there is a 1% chance for the returns to exceed the 99th percentile level. After getting the VaR value, I manually adjust the bands based on the current market I'm trading on. I take the highest point (VaR*2) and the lowest point (-(VaR*2)) from the Kalman Filter, and then divide them into segments manually based on my preference.
This process results in 8 segments, where 2 segments near the Kalman Filter are further divided, making a total of 12 segments. These segments classify the current state of the price based on code-based coloring. The five states are very bullish, bullish, very bearish, bearish, and neutral.
I created this indicator to have an adaptive band that is not biased toward the volatility of the market. Most band-based indicators don't capture reversals that well, but the Kalman Filter Volume Bands can capture both trends and reversals. This makes it suitable for both trend-following and reversal trading approaches.
That's all for the explanation! Ciao!
Additional Reminder:
- Please use hourly timeframes or higher as lower timeframes are too noisy for reliable readings of this indicator.
Price alert multi symbols (Miu)This indicator won't plot anything to the chart.
Please follow steps below to set your alarms based on multiple symbols' prices:
1) Add indicator to the chart
2) Go to settings
3) Check symbols you want to receive alerts (choose up to 8 different symbols)
4) Set price for each symbol
5) Once all is set go back to the chart and click on 3 dots to set alert in this indicator, rename your alert and confirm
6) You can remove indicator after alert is set and it'll keep working as expected
What does this indicator do?
This indicator will generate alerts based on following conditions:
- If price set is met for any symbol
Once condition is met it will send an alert with the following information:
- Symbol name (e.g: BTC, ETH, LTC)
- Price reached
This script requests current price for each symbol through request.security() built-in function. It also requests amount of digits (mintick) for each symbol to send alerts with correct value.
This script was developed to attend a demand from a comment in other published script.
Feel free to give feedbacks on comments section below.
Enjoy!
Previous Day and Week RangesI've designed the "Previous Day and Week Ranges" indicator to enhance your trading strategy by clearly displaying daily and weekly price levels. This tool shows Open-Close and High-Low ranges for both daily and weekly timeframes directly on your trading chart.
Key Features :
Potential Support and Resistance: The indicator highlights previous day and week ranges that may serve as key support or resistance levels in subsequent trading sessions.
Customizable Display Options: Offers the flexibility to show or hide daily and weekly ranges based on your trading needs.
Color Customization: Adjust the color settings to differentiate between upward and downward movements, enhancing visual clarity and chart readability.
This indicator is ideal for traders aiming to understand market dynamics better, offering insights into potential pivot points and zones of price stability or volatility.

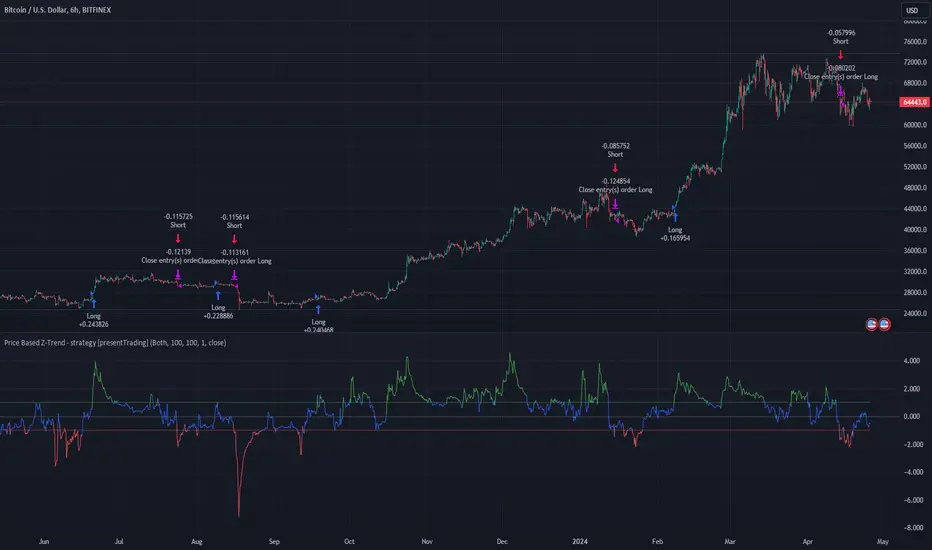
Price Based Z-Trend - Strategy [presentTrading]█ Introduction and How it is Different
Z-score: a statistical measurement of a score's relationship to the mean in a group of scores.
Simple but effective approach.
The "Price Based Z-Trend - Strategy " leverages the Z-score, a statistical measure that gauges the deviation of a price from its moving average, normalized against its standard deviation. This strategy stands out due to its simplicity and effectiveness, particularly in markets where price movements often revert to a mean. Unlike more complex systems that might rely on a multitude of indicators, the Z-Trend strategy focuses on clear, statistically significant price movements, making it ideal for traders who prefer a streamlined, data-driven approach.
BTCUSD 6h LS Performance
█ Strategy, How It Works: Detailed Explanation
🔶 Calculation of the Z-score
"Z-score is a statistical measurement that describes a value's relationship to the mean of a group of values. Z-score is measured in terms of standard deviations from the mean. If a Z-score is 0, it indicates that the data point's score is identical to the mean score. A Z-score of 1.0 would indicate a value that is one standard deviation from the mean. Z-scores may be positive or negative, with a positive value indicating the score is above the mean and a negative score indicating it is below the mean."
The Z-score is central to this strategy. It is calculated by taking the difference between the current price and the Exponential Moving Average (EMA) of the price over a user-defined length, then dividing this by the standard deviation of the price over the same length:
z = (x - μ) /σ
Local
🔶 Trading Signals
Trading signals are generated based on the Z-score crossing predefined thresholds:
- Long Entry: When the Z-score crosses above the positive threshold.
- Long Exit: When the Z-score falls below the negative threshold.
- Short Entry: When the Z-score falls below the negative threshold.
- Short Exit: When the Z-score rises above the positive threshold.
█ Trade Direction
The strategy allows users to select their preferred trading direction through an input option.
█ Usage
To use this strategy effectively, traders should first configure the Z-score thresholds according to their risk tolerance and market volatility. It's also crucial to adjust the length for the EMA and standard deviation calculations based on historical performance and the expected "noise" in price data.
The strategy is designed to be flexible, allowing traders to refine settings to better capture profitable opportunities in specific market conditions.
█ Default Settings
- Trade Direction: Both
- Standard Deviation Length: 100
- Average Length: 100
- Threshold for Z-score: 1.0
- Bar Color Indicator: Enabled
These settings offer a balanced starting point but can be customized to suit various trading styles and market environments. The strategy's parameters are designed to be adjusted as traders gain experience and refine their approach based on ongoing market analysis.
Z-score is a must-learn approach for every algorithmic trader.
1 Year Historical Trend AnalyzerHey everyone!
This is a new indicator of mine. If you know me, you know I really like Z-Score and there are a lot of cool things that can be done with Z-Score, especially as it pertains to trading!
This indicator uses Z-Score but in a different way from conventional Z-Score indicators (including mine). It uses Z-Score to plot out the current 1 year trend of a stock. Now, 1 year trend is not year to date (i.e. if we are in April, it is not just looking from January to April), but instead, its taking the last 1 trading year of candle data to plot out the trend, ranges and areas of z-score math based supports and resistances.
How it works:
The indicator will look at the current timeframe you are on, whether it be daily, 1 hour, 4 hours, weekly or even monthly. It will then look back the designated amount of candles that constitute 1 trading year. These are preprogrammed into the indicator so it knows to look back X number of Candles based on Y timeframe. This will give you a standard, scaled version of the past 1 year of trading data.
From there, the indicator will calculate the MAX Z-Score (or the highest Z-Score that the stock reached over the 1 trading year) and the MIN Z-score (or the lowest Z-Score that the stock reached over the 1 trading year). It plots these as a red and green line respectively:
It will then display the price that the MAX and MIN fall at. Keep in mind, the MAX and MIN price will change as the trading time elapses, but the Z-Score will remain the same until the stock does a lower or higher move from that z-score point.
It will then calculate the mean (average) of the Max and Min and then the mid points between the max and mean, and the min and mean. These all represent mathematical areas of support and resistance and key levels to watch when trading.
The indicator also has a table that is optional. The table can be toggled to either Auto or Manual. Auto will automatically calculate 5 Z-Score Points that are within the proximity of the annual trading range. However, you can select manual and input your own Z-Score values to see where the prices will fall based on the 1 year of data.
Some other options:
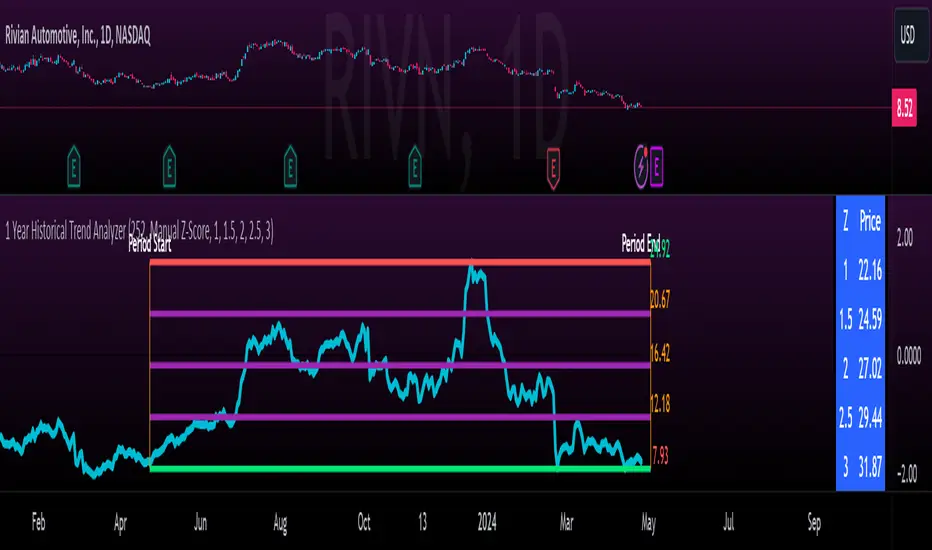
You can toggle on and off these midline support and resistance levels in the settings menu. Additionally, you can have the indicator plot actual scaled candles of the 1 year trading history. This is a great function to really see how the support and resistance works. Let’s take a look at RIVN, plotted as candles, on the 1 hour timeframe:
In this diagram, we can see two recent points in March where the Z-Score has acted as support for the stock. If we view this in conjunction with the actual ticker, you can see these were great buy points:
Do get this functionality, simply go into the plots menu in the settings menu and select “Plot as Candles”.
How to Use it:
While I have discussed some applications of the indicator, namely identify math supports and resistances, targets and such, there are some key things I really want to emphasize that this indicator excels at. I am going to group them for greater clarity:
All time Highs and All Time Lows:
AXP has recently been pushing ATHs. When a stock breaks an ATH or an ATL, it is said that there is no resistance or support. However, with Z-Score that is never true, there are always areas of math resistance and support. We can use this indicator to identify such areas. Let’s look at AXP:
Using this as a reference, we can see that AXP broke out of a Z-Score resistance level and re-tested the resistance as support. It held and continued up. We can see that the next area of math resistance is at 270:
And 234.65 is support. We would look for the ticker to hold this 234.65 line as support to continue the move up to the 270s.
Similar setup for ATLs with RIVN:
We can see that RIVN can indeed make a new ATL because support isn’t until 7.63.
Technical Tips on How to Use:
Because this indicator uses predefined lookback periods based on timeframes, its important that you are analyzing the data with pre-market turned off. The candles are calculated with the assumption that there is no pre-market data.
As well, the lowest timeframe that can be used to get 1 year worth of data is 1 hour. Anything below 1 hour will require you to manually input a lookback length (default is 252) which will be less than 1 year. This is simply because of the limitations of candle lookbacks through Pinescript.
That is not to say that this is not effective on smaller timeframes, it is! You just need to be sure that you understand you are not looking at a year trend worth of data. You can toggle your manual lookback parameters in the settings menu.
Concluding remarks
And that’s the indicator! I know the explanation is lengthy but I really suggest you read it carefully to understand how the indicator works and how you can best use it to analyze tickers and supplement your strategy.
Thanks for reading and safe trades as always!
Buy Sell Strategy With Z-Score [TradeDots]The "Buy Sell Strategy With Z-Score" is a trading strategy that harnesses Z-Score statistical metrics to identify potential pricing reversals, for opportunistic buying and selling opportunities.
HOW DOES IT WORK
The strategy operates by calculating the Z-Score of the closing price for each candlestick. This allows us to evaluate how significantly the current price deviates from its typical volatility level.
The strategy first takes the scope of a rolling window, adjusted to the user's preference. This window is used to compute both the standard deviation and mean value. With these values, the strategic model finalizes the Z-Score. This determination is accomplished by subtracting the mean from the closing price and dividing the resulting value by the standard deviation.
This approach provides an estimation of the price's departure from its traditional trajectory, thereby identifying market conditions conducive to an asset being overpriced or underpriced.
APPLICATION
Firstly, it is better to identify a stable trading pair for this technique, such as two stocks with considerable correlation. This is to ensure conformance with the statistical model's assumption of a normal Gaussian distribution model. The ideal performance is theoretically situated within a sideways market devoid of skewness.
Following pair selection, the user should refine the span of the rolling window. A broader window smoothens the mean, more accurately capturing long-term market trends, while potentially enhancing volatility. This refinement results in fewer, yet precise trading signals.
Finally, the user must settle on an optimal Z-Score threshold, which essentially dictates the timing for buy/sell actions when the Z-Score exceeds with thresholds. A positive threshold signifies the price veering away from its mean, triggering a sell signal. Conversely, a negative threshold denotes the price falling below its mean, illustrating an underpriced condition that prompts a buy signal.
Within a normal distribution, a Z-Score of 1 records about 68% of occurrences centered at the mean, while a Z-Score of 2 captures approximately 95% of occurrences.
The 'cool down period' is essentially the number of bars that await before the next signal generation. This feature is employed to dodge the occurrence of multiple signals in a short period.
DEFAULT SETUP
The following is the default setup on EURUSD 1h timeframe
Rolling Window: 80
Z-Score Threshold: 2.8
Signal Cool Down Period: 5
Commission: 0.03%
Initial Capital: $10,000
Equity per Trade: 30%
RISK DISCLAIMER
Trading entails substantial risk, and most day traders incur losses. All content, tools, scripts, articles, and education provided by TradeDots serve purely informational and educational purposes. Past performances are not definitive predictors of future results.
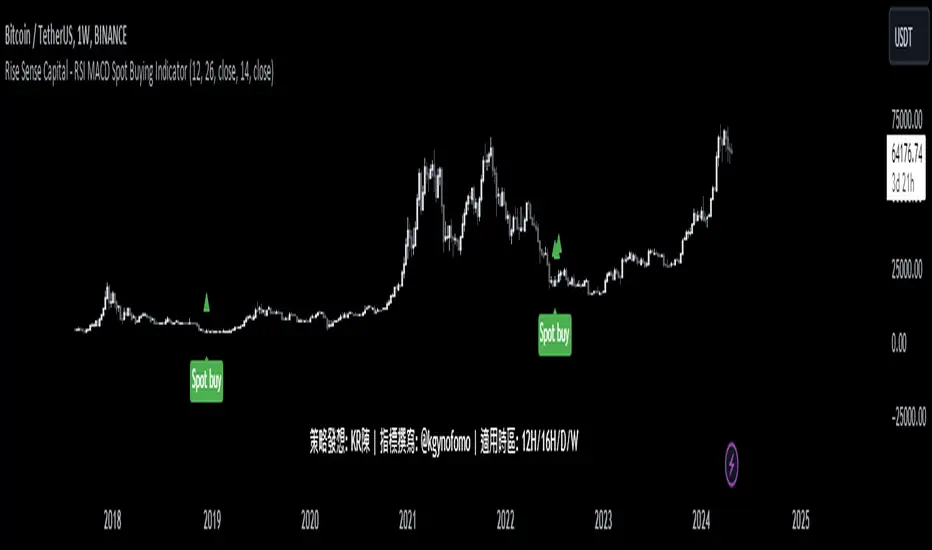
Rise Sense Capital - RSI MACD Spot Buying IndicatorToday, I'll share a spot buying strategy shared by a member @KR陳 within the DATA Trader Alliance Alpha group. First, you need to prepare two indicators:
今天分享一個DATA交易者聯盟Alpha群組裏面的群友@KR陳分享的現貨買入策略。
首先需要準備兩個指標
RSI Indicator (Relative Strength Index) - RSI is a technical analysis tool based on price movements over a period of time to evaluate the speed and magnitude of price changes. RSI calculates the changes in price over a period to determine whether the recent trend is relatively strong (bullish) or weak (bearish).
RSI指標,(英文全名:Relative Strength Index),中文稱為「相對強弱指標」,是一種以股價漲跌為基礎,在一段時間內的收盤價,用於評估價格變動的速度 (快慢) 與變化 (幅度) 的技術分析工具,RSI藉由計算一段期間內股價的漲跌變化,判斷最近的趨勢屬於偏強 (偏多) 還是偏弱 (偏空)。
MACD Indicator (Moving Average Convergence & Divergence) - MACD is a technical analysis tool proposed by Gerald Appel in the 1970s. It is commonly used in trading to determine trend reversals by analyzing the convergence and divergence of fast and slow lines.
MACD 指標 (Moving Average Convergence & Divergence) 中文名為平滑異同移動平均線指標,MACD 是在 1970 年代由美國人 Gerald Appel 所提出,是一項歷史悠久且經常在交易中被使用的技術分析工具,原理是利用快慢線的交錯,藉以判斷股價走勢的轉折。
In MACD analysis, the most commonly used values are 12, 26, and 9, known as MACD (12,26,9). The market often uses the MACD indicator to determine the future direction of assets and to identify entry and exit points.
在 MACD 的技術分析中,最常用的值為 12 天、26 天、9 天,也稱為 MACD (12,26,9),市場常用 MACD 指標來判斷操作標的的後市走向,確定波段漲幅並找到進、出場點。
Strategy analysis by member KR陳:
策略解析 by群友 KR陳 :
Condition 1: RSI value in the previous candle is below oversold zone(30).
條件1:RSI 在前一根的數值低於超賣區(30)
buycondition1 = RSI <30
Condition 2: MACD histogram changes from decreasing to increasing.
條件2:MACD柱由遞減轉遞增
buycondition2 = hist >hist and hist <hist
Strategy Effect Display:
策略效果展示:
Slight modification:
稍微修改:
I've added the ATR-MACD, developed earlier, as a filter signal alongside the classic MACD. The appearance of an upward-facing triangle indicates that the ATR MACD histogram also triggers the condition, aiming to serve as a filtering mechanism.
我在經典的macd作爲條件的同時 也加入了之前開發的ATR-MACD作爲過濾信號 出現朝上的三角圖示代表ATR MACD的柱狀圖一樣觸發條件 希望可以以此起到過濾的作用
Asset/Usage Instructions:
使用標的/使用説明
Through backtesting, it's found that it's not suitable for smaller time frames as there's a lot of noise. It's recommended to use it in assets with a long-term bullish view, focusing on time frames of 12 hours or longer such as 12H, 16H, 1D, 1W to find spot buying opportunities.
經過回測發現 并不適用與一些小級別時區 噪音會非常多,建議在一些長期看漲的標的中切入12小時以上的時區如12H,16H, 1D, 1W 中間尋找現貨買入的機會。
A few thoughts:
Overall, it's a very good indicator strategy for spot buying in the physical market. Thanks to member @KR陳 for sharing!
一些小感言 綜合來看是一個針對現貨買入非常好的指標策略,感謝群友@KR陳的分享!
Crypto Liquidation Heatmap [LuxAlgo]The Crypto Liquidation Heatmap tool offers real-time insights into the liquidations of the top cryptocurrencies by market capitalization, presenting the current state of the market in a visually accessible format. Assets are sorted in descending order, with those experiencing the highest liquidation values placed at the top of the heatmap.
Additional details, such as the breakdown of long and short liquidation values and the current price of each asset, can be accessed by hovering over individual boxes.
🔶 USAGE
The crypto liquidation heatmap tool provides real-time insights into liquidations across all timeframes for the top 29 cryptocurrencies by market capitalization. The assets are visually represented in descending order, prioritizing assets with the highest liquidation values at the top of the heatmap.
Different colors are used to indicate whether long or short liquidations are dominant for each asset. Green boxes indicate that long liquidations surpass short liquidations, while red boxes indicate the opposite, with short liquidations exceeding long liquidations.
Hovering over each box provides additional details, such as the current price of the asset, the breakdown of long and short liquidation values, and the duration for the calculated liquidation values.
🔶 DETAILS
🔹Crypto Liquidation
Crypto liquidation refers to the process of forcibly closing a trader's positions in the cryptocurrency market. It occurs when a trader's margin account can no longer support their open positions due to significant losses or a lack of sufficient margin to meet the maintenance requirements. Liquidations can be categorized as either a long liquidation or a short liquidation.
A long liquidation occurs when long positions are being liquidated, typically due to a sudden drop in the price of the asset being traded. Traders who were bullish on the asset and had opened long positions will face losses as the market moves against them.
On the other hand, a short liquidation occurs when short positions are being liquidated, often triggered by a sudden spike in the price of the asset. Traders who were bearish on the asset and had opened short positions will face losses as the market moves against them.
🔹Liquidation Data
It's worth noting that liquidation data is not readily available on TradingView. However, we recognize the close correlation between liquidation data, trading volumes, and asset price movements. Therefore, this script analyzes accessible data sources, extracts necessary information, and offers an educated estimation of liquidation data. It's important to emphasize that the presented data doesn't reflect precise quantitative values of liquidations. Traders and analysts should instead focus on observing changes over time and identifying correlations between liquidation data and price movements.
🔶 SETTINGS
🔹Cryptocurrency Asset List
It is highly recommended to select instruments from the same exchange with the same currency to maintain proportional integrity among the chosen assets, as different exchanges may have varying trading volumes.
Supported currencies include USD, USDT, USDC, USDP, and USDD. Remember to use the same currency when selecting assets.
List of Crypto Assets: The default options feature the top 29 cryptocurrencies by market capitalization, currently listed on the Binance Exchange. Please note that only crypto assets are supported; any other asset type will not be processed or displayed. To maximize the utility of this tool, it is crucial to heed the warning message displayed above.
🔹Liquidation Heatmap Settings
Position: Specifies the placement of the liquidation heatmap on the chart.
Size: Determines the size of the liquidation heatmap displayed on the chart.
🔶 RELATED SCRIPTS
Liquidations-Meter
Liquidation-Estimates
Liquidation-Levels

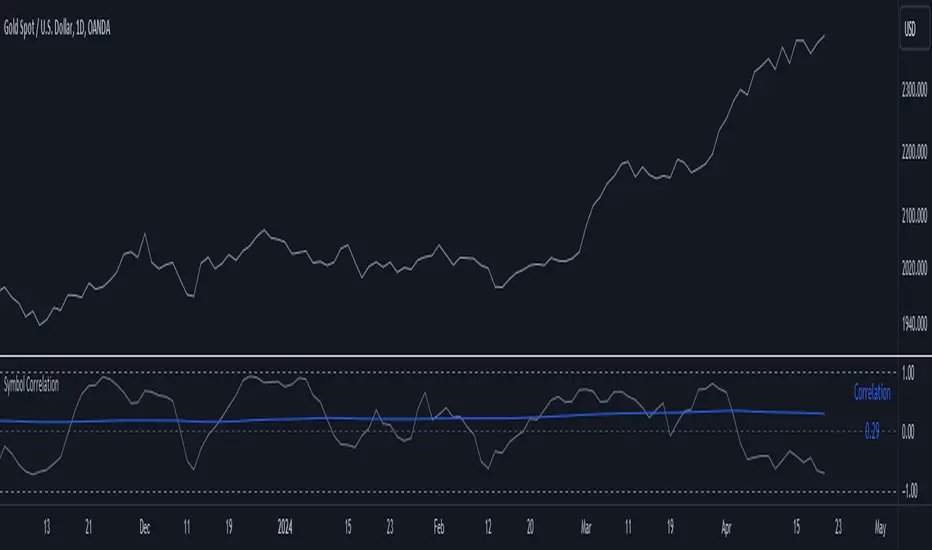
Symbol CorrelationThe "Symbol Correlation" indicator calculates and displays the correlation between the chosen symbol's price and another selected source over a specified period. It also includes a moving average (SMA) of this correlation to provide a smoothed view of the relationship.
Why SMA and Table Display ?
The inclusion of SMA (Simple Moving Average) with adjustable length (SMA Length) enhances the indicator's utility by smoothing out short-term fluctuations in correlation, allowing for clearer trend identification. The SMA helps to visualize the underlying trend in correlation, making it easier to spot changes and patterns over time.
The table display of the correlation SMA value offers a concise summary of this trend. By showcasing the current correlation SMA alongside its historical values, traders can quickly gauge the relationship's strength relative to previous periods.
Interpreting the Indicator:
1. Correlation Values: The primary plot shows the raw correlation values between the symbol's price and the specified source. A value of 1 indicates a perfect positive correlation, -1 signifies a perfect negative correlation, and 0 suggests no linear relationship.
2. Correlation SMA: The SMA line represents the average correlation over a defined period (SMA Length). Rising SMA values indicate strengthening correlation trends, while declining values suggest weakening correlations.
3. Choosing SMA Length: Traders can adjust the SMA Length parameter to tailor the moving average to their specific analysis horizon. Shorter SMA lengths react quickly to price changes but may be more volatile, while longer SMA lengths smooth out noise but respond slower to recent changes.
In summary, the "Symbol Correlation" indicator is a valuable tool for assessing the evolving relationship between a symbol's price and an external source. Its use of SMA and tabular presentation facilitates a nuanced understanding of correlation trends, aiding traders in making informed decisions based on market dynamics.
Tweet/X Post Timestamp - By LeviathanThis script allows you to generate visual timestamps of X/Twitter posts directly on your chart, highlighting the precise moment an X post/tweet was made. All you have to do is copy and paste the post URL.
◽️ Use Cases:
- News Trading: Traders can use this indicator to visually align market price actions with news or announcements made on X (formerly Twitter), aiding in the analysis of news impact on market volatility.
- Behavioral Analysis: Traders studying the influence of social media on price can use the timestamps to track correlations between specific posts and market reactions.
- Proof of Predictions: Traders can use this indicator to timestamp their market forecasts shared on X (formerly Twitter), providing a visual record of their predictions relative to actual market movements. This feature allows for transparent verification of the timing and accuracy of their analyses
◽️ Process of Timestamp Calculation
The calculation of the timestamp from a tweet ID involves the following steps:
Extracting the Post ID:
The script first parses the input URL provided by the user to extract the unique ID of the tweet or X post. This ID is embedded in the URL and is crucial for determining the exact posting time.
Calculating the Timestamp:
The post ID undergoes a mathematical transformation known as a right shift by 22 bits. This operation aligns the ID's timestamp to a base reference time used by the platform.
Adding Base Offset:
The result from the right shift is then added to a base offset timestamp (1288834974657 ms, the epoch used by Twitter/X). This converts the processed ID into a UNIX timestamp reflecting the exact moment the post was made.
Date-Time Conversion:
The UNIX timestamp is further broken down into conventional date and time components (year, month, day, hour, minute, second) using calculations that account for leap years and varying days per month.
Label Placement:
Based on user settings, labels displaying the timestamp, username, and other optional information such as price changes or pivot points are dynamically placed on the chart at the bar corresponding to the timestamp.

Bayesian Bias OscillatorWhat is a Bayes Estimator?
Bayesian estimation, or Bayesian inference, is a statistical method for estimating unknown parameters of a probability distribution based on observed data and prior knowledge about those parameters. At first , you will need a prior probability distribution, which is a prior belief about the distribution of the parameter that you are interested in estimating. This distribution represents your initial beliefs or knowledge about the parameter value before observing any data. Second , you need a likelihood function, which represents the probability of observing the data given different values of the parameter. This function quantifies how well different parameter values explain the observed data. Then , you will need a posterior probability distribution by combining the prior distribution and the likelihood function to obtain the posterior distribution of the parameter. The posterior distribution represents the updated belief about the parameter value after observing the data.
Bayesian Bias Oscillator
This tool calculates the Bayes bias of returns, which are directional probabilities that provide insight on the "trend" of the market or the directional bias of returns. It comes with two outputs: the default one, which is the Z-Score of the Bayes Bias, and the regular raw probability, which can be switched on in the settings of the indicator.
The Z-Score output value doesn't tell you the probability, but it does tell you how much of a standard deviation the value is from the mean. It uses both probabilities, the probability of a positive return and the probability of a negative return, which is just (1 - probability of a positive return).
The probability output value shows you the raw probability of a positive return vs. the probability of a negative return. The probability is the value of each line plotted (blue is the probability of a positive return, and purple is the probability of a negative return).
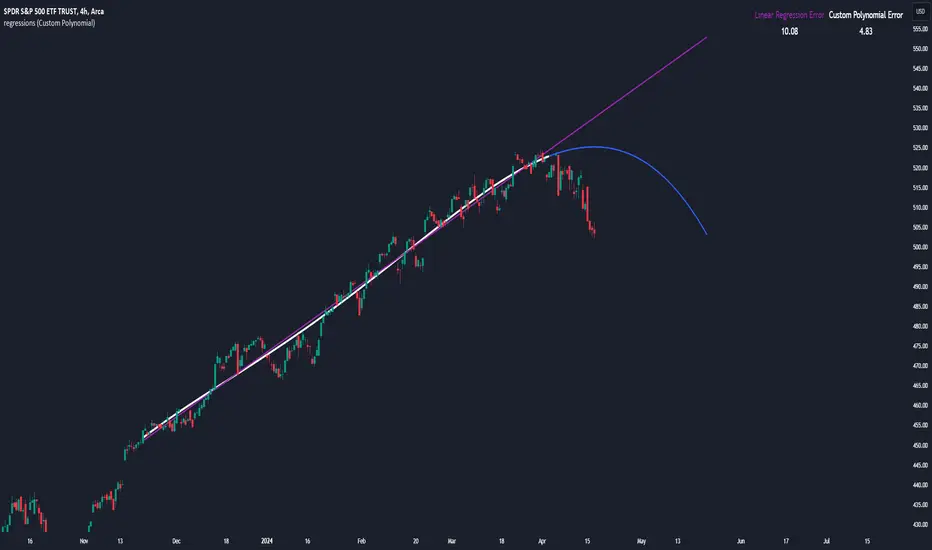
regressionsLibrary "regressions"
This library computes least square regression models for polynomials of any form for a given data set of x and y values.
fit(X, y, reg_type, degrees)
Takes a list of X and y values and the degrees of the polynomial and returns a least square regression for the given polynomial on the dataset.
Parameters:
X (array) : (float ) X inputs for regression fit.
y (array) : (float ) y outputs for regression fit.
reg_type (string) : (string) The type of regression. If passing value for degrees use reg.type_custom
degrees (array) : (int ) The degrees of the polynomial which will be fit to the data. ex: passing array.from(0, 3) would be a polynomial of form c1x^0 + c2x^3 where c2 and c1 will be coefficients of the best fitting polynomial.
Returns: (regression) returns a regression with the best fitting coefficients for the selecected polynomial
regress(reg, x)
Regress one x input.
Parameters:
reg (regression) : (regression) The fitted regression which the y_pred will be calulated with.
x (float) : (float) The input value cooresponding to the y_pred.
Returns: (float) The best fit y value for the given x input and regression.
predict(reg, X)
Predict a new set of X values with a fitted regression. -1 is one bar ahead of the realtime
Parameters:
reg (regression) : (regression) The fitted regression which the y_pred will be calulated with.
X (array)
Returns: (float ) The best fit y values for the given x input and regression.
generate_points(reg, x, y, left_index, right_index)
Takes a regression object and creates chart points which can be used for plotting visuals like lines and labels.
Parameters:
reg (regression) : (regression) Regression which has been fitted to a data set.
x (array) : (float ) x values which coorispond to passed y values
y (array) : (float ) y values which coorispond to passed x values
left_index (int) : (int) The offset of the bar farthest to the realtime bar should be larger than left_index value.
right_index (int) : (int) The offset of the bar closest to the realtime bar should be less than right_index value.
Returns: (chart.point ) Returns an array of chart points
plot_reg(reg, x, y, left_index, right_index, curved, close, line_color, line_width)
Simple plotting function for regression for more custom plotting use generate_points() to create points then create your own plotting function.
Parameters:
reg (regression) : (regression) Regression which has been fitted to a data set.
x (array)
y (array)
left_index (int) : (int) The offset of the bar farthest to the realtime bar should be larger than left_index value.
right_index (int) : (int) The offset of the bar closest to the realtime bar should be less than right_index value.
curved (bool) : (bool) If the polyline is curved or not.
close (bool) : (bool) If true the polyline will be closed.
line_color (color) : (color) The color of the line.
line_width (int) : (int) The width of the line.
Returns: (polyline) The polyline for the regression.
series_to_list(src, left_index, right_index)
Convert a series to a list. Creates a list of all the cooresponding source values
from left_index to right_index. This should be called at the highest scope for consistency.
Parameters:
src (float) : (float ) The source the list will be comprised of.
left_index (int) : (float ) The left most bar (farthest back historical bar) which the cooresponding source value will be taken for.
right_index (int) : (float ) The right most bar closest to the realtime bar which the cooresponding source value will be taken for.
Returns: (float ) An array of size left_index-right_index
range_list(start, stop, step)
Creates an from the start value to the stop value.
Parameters:
start (int) : (float ) The true y values.
stop (int) : (float ) The predicted y values.
step (int) : (int) Positive integer. The spacing between the values. ex: start=1, stop=6, step=2:
Returns: (float ) An array of size stop-start
regression
Fields:
coeffs (array__float)
degrees (array__float)
type_linear (series__string)
type_quadratic (series__string)
type_cubic (series__string)
type_custom (series__string)
_squared_error (series__float)
X (array__float)