Z-Score Forecaster[SS]Hello everyone,
I just released a neat library for Forecasting stock and equities. In it, it has a couple of novel approaches to forecasting (namely, a Moving Average forecaster and a Z-Score Forecaster). These were accomplished applying basic theories on Autoregression, ARIMA modelling and Z-Score to make new approaches to forecasting.
This is one of the novel approaches, the Z-Score forecaster.
How this function works is it identifies the current trend over the duration of the Z-Score assessment period. So, if the Z-Score is being assessed over the previous 75 candles, it will identify the trend over the previous 75 candles. It will then plot out the forecasted levels according to the trend, up to a maximum of the max Z-Score the ticker has reached within its period. At that point, it will show a likely trend reversal.
Here is an example:
This shows that SPY may go to 475.42 before reversing, as 475.42 is the highest z-score that has been achieved in the current trend.
When it is in an uptrend, the forecast line will be green, when in a downtrend, it will be red.
The forecasting line is accomplished through pinescript's new polyline feature.
In addition to the line, you can also have the indicator plot out a forecast table. The Z-Score Forecast table was formatted in a similar way to ARIMA, where it makes no bias about trend, it simply plots out both ends of the spectrum. So, if an uptrend were to continue, it will list the various uptrend targets along the way, vice versa for downtrends.
It will also display what Z-Score these targets would amount to. Here is an example:
Looking at SPY on the daily, we can see that a likely upside target would be around 484 at just over 2 Standard Deviations (Z-Score).
Its not liklely to go higher than that because then we are getting into 3 and 4 standard deviations.
Remember, everything generally should be within 1 and -1 standard deviations of the mean. So if we look at the table, we can see that would be between 466 and 430.
Customization
You can customize the Z-Score length and source. You can also toggle off and on alerts. The alerts will pop up when a ticker is trading at a previous maximum or previous minimum.
I have also added a manual feature to plot the Z-Score SMA, which is simply the SMA over the desired Z-Score lookback time.
And that's the indicator!
If you are interested in the library, you can access it here .
Thanks for checking this out and leave your questions below!
Forecasting

VWAP, MFI, RSI with S/R StrategyBest for 0dte/intraday trading on AMEX:SPY with 1 minute chart
Strategy Concept
This strategy aims to identify potential reversal points in a price trend by combining momentum indicators (RSI and MFI), volume-weighted price (VWAP), and recent price action trends. It looks for conditions where the price is poised to change direction, either bouncing off a support level in a potential uptrend or falling from a resistance level in a potential downtrend.
By incorporating both price level analysis (support/resistance) and momentum indicators, the strategy seeks to increase the likelihood of identifying significant trend reversals, taking into consideration both recent price movements and the current price's position relative to historical highs and lows.
VWAP (Volume-Weighted Average Price)
VWAP acts as a benchmark to determine the general market trend. It's an average price weighted by volume.
A price above VWAP is often considered bullish, and a price below VWAP is seen as bearish.
MFI (Money Flow Index) and RSI (Relative Strength Index) Parameters
MFI is a volume-weighted RSI, used to identify overbought (above 70) or oversold (below 30) conditions.
RSI is a momentum indicator that measures the magnitude of recent price changes to identify overbought or oversold conditions, similar to MFI.
The script uses standard overbought (70) and oversold (30) thresholds for both MFI and RSI.
Trend Check Function
The function trendCheck analyzes the past pastBars candles to count how many were bullish (closing price higher than the opening price) and bearish.
This function is used to assess the recent trend direction.
Support and Resistance Detection
The script calculates the highest high (highestHigh) and lowest low (lowestLow) over the last lookbackSR (50) periods to identify potential support and resistance levels.
isNearSupport and isNearResistance are conditions to check if the current price is within 0.08% of these identified levels, indicating proximity to support or resistance.
Buy and Sell Logic
Buy Signal:
The RSI crosses over the oversold threshold (30).
The MFI is also below its oversold level (30).
The current price is above the VWAP.
The recent trend (past 20 bars) has been predominantly bearish.
The price is near the identified support level.
Sell Signal:
The RSI crosses under the overbought threshold (70).
The MFI is above its overbought level (70).
The current price is below the VWAP.
The recent trend has been predominantly bullish.
The price is near the identified resistance level.
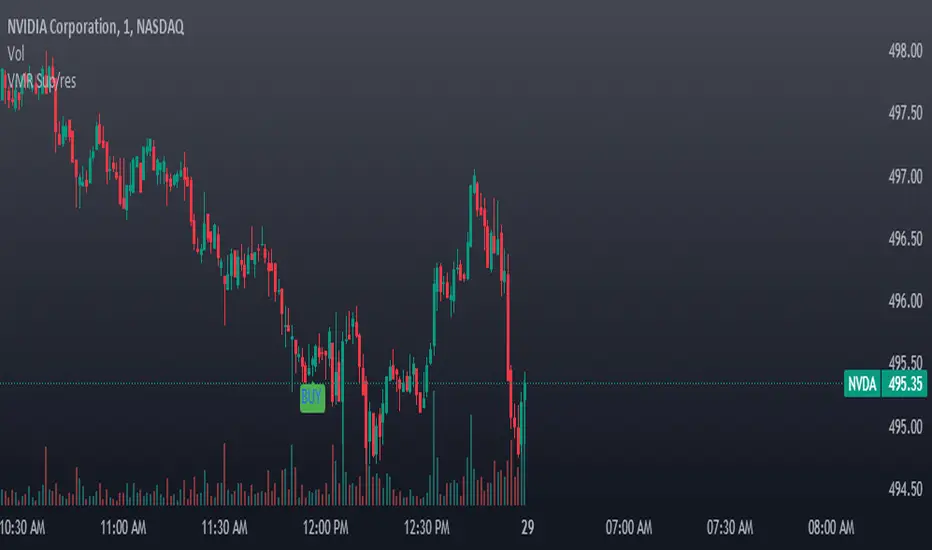
ICT Handle CounterThe "Handle Counter" is a unique TradingView script designed for ease and effectiveness in tracking price movements. It's particularly useful for traders who follow ICT methodologies. Users manually input their trade entry price, and the script then dynamically calculates and displays the number of Handles, or price changes, in a clear box above the latest candle on the chart. This real-time updating feature provides traders with crucial, current data on price movement, aiding in informed decision-making and a better understanding of market dynamics.
The "Handle Counter" script operates in the following way:
User Input: It starts by allowing you to input your trade's entry price. This is the price level from which the script will measure price movement.
Handles Calculation: The script calculates "Handles," which represent the price difference from your entry point to the current market price. This is done using a mathematical formula that finds the absolute value of this difference.
Display Mechanism: The calculated Handles are then displayed in a box, which is positioned above the latest candle on your trading chart. This box updates in real-time, giving you an ongoing view of how many Handles (price changes) have occurred since your entry point.
This script is designed to be straightforward and easy to use, providing clear, real-time information.
How to use:
Add the Indicator.
Open the Menu by clicking on the 'Settings' icon.
Navigate to the 'Inputs' tab and enter your entry price.
Click 'OK.' The indicator should immediately place a box above the latest candle, showing the current handles.
Additional Settings
Change Color of the Box
Change Color of the Font
Stock's Intrinsic Value| DCF modelScript Description
This pine script is based on a YouTube video titled: Warren Buffett: How to Calculate the Intrinsic Value of a Stock. Warren Buffett is a famous value investor who follows the principles of his mentor Benjamin Graham. He looks for companies that have strong competitive advantages, consistent earnings, and low debt. He also considers the intrinsic value of a company, which is the present value of its future cash flows, and compares it to the market price. He prefers to buy stocks that are trading below their intrinsic value and hold them for a long time.
One of the methods that Buffett uses to estimate the intrinsic value of a company is the discounted cash flow (DCF) model. This involves projecting the free cash flow (FCF) of the company for several years and then discounting it back to the present using an appropriate discount rate. The discount rate is usually the weighted average cost of capital (WACC) of the company, which reflects its cost of equity and debt. The sum of the discounted FCFs and terminal value is the intrinsic value of the company.
Lastly, a margin of safety is included when using the DCF method for stock valuation because of uncertainty and error in estimating future cash flows and the intrinsic value of the company.
When the current price is below margin of safety, it means that the stock is currently undervalued and being price at significantly below its intrinsic value.
Guideline for determining each variable in this script
FCF growth rate: This is the annual rate at which the free cash flow (FCF) of the company is expected to grow over a forecast 10-year period. You can use historical FCF growth rates, industry averages, analyst estimates, or your assumptions to project the FCF growth rate. The higher the FCF growth rate, the higher the intrinsic value will be.
Discount rate: This is the rate of return that you require to invest in the company. It reflects the risk and opportunity cost of investing in the company. You can use the weighted average cost of capital (WACC) of the company, capital pricing model (CAPM), hurdle rate, or market rate as the discount rate. The lower the discount rate, the higher the intrinsic value.
The margin of safety: Provides a cushion against errors in the valuation or adverse events that may affect the company. The margin of safety depends on your personal preference and risk tolerance. Normally is at 15% - 30%, the higher the margin of safety you set, the lower the chance that the stock will hit that level.
How to use this script
Step 1: This script only works for stocks that have financial data of free cash flow and total common shares outstanding
Step 2: Please use a yearly chart (12-month chart)
Step 3: You are required to determine a growth rate that will grow the free cash flow 10 years into the future
Step 4: You are required to determine a discount rate for the calculations
Step 5: You are required to add a margin of safety (Accounting for uncertainty)
Step 6: The rest of the calculations will be done automatically.
Disclaimer when using this script
I'm not a financial advisor
This script is for education purposes only
There are risks involved with stock market investing and investors should not act upon the content or information found here without first seeking advice from an accountant, financial planner, lawyer or other professional.
I can’t guarantee that this script will be error-free as I still consider myself a Pinescript beginner
Before making any decisions, investors should always research companies individually
I'll not be liable for any loss incurred, arising from the use of, or reliance on, this script
Limitations of this script
This script only works on the yearly chart (12 monthly charts)
The intrinsic value of a company will be negative if the company have a negative forecasted free cash flow
You need to make an educated guess about the growth rate, discount rate and margin of safety
This script uses free cash flow instead of owner's earnings (Operating cash flow - Maintenance capital expenditure), therefore it can't accurately estimate the maintenance capital expenditure.
Need at least 6 years’ worth of financial data
Market capitalisation uses total common shares outstanding multiplied by the closing price instead of using company-level total outstanding shares multiplied by the closing price

MA+ ProjectionThe "MA+ Projection" indicator is designed to visualize the potential future direction of a moving average, taking into account the impact of historical data loss. It is primarily aimed at providing a practical perspective on how moving averages could evolve as older data points are no longer considered.
Key Features:
Supported Moving Averages: SMA, EMA, WMA, VWMA, and VAWMA (Volume Adjusted WMA).
Flexible Time Span Settings: Customize the moving average length in bars, minutes, or days.
Adjustable Projection Scope: Set a percentage of the measurement to project forward.
Projection 'Cone': Show/hide the deviation and control the multiple.
Use Last Source Value: An option to add the latest known value to the moving window instead of only letting the window shrink. (Enabled by default.)
How It Works:
Given the specified parameters, it takes the selected moving average type (a known formula like SMA, EMA, or WMA), and projects the future data points by continuing to move the data 'window' forward without adding any more data. By default, it extends the average by assuming the price hasn't changed after the last bar. Alternatively, the projection can be the result of shrinking the window as it moves forward without adding any new data points.
Note:
This tool is for visual projection, not prediction. Its purpose is to aid in the analysis of potential future trends based on historical data, not to provide definitive market forecasts.

Seek liquidityGuided by ICT tutoring, I create this versatile "Seek liquidity" indicator.
This indicator shows an easy way to view the Liquidity that has been Created - Eliminated - and what liquidity is left to eliminate.
Liquidity levels appear after the sessions are over, and the lines get stuck on the candle that eliminates them.
Timing session =
//---Asian
- 18:00-00:00
//---London
- 00:00-02:00
- 02:00-05:00
- 00:00-06:00
//---New York
- 06:00-12:00
- 09.30-12.00
//---Lunch
- 12:00-13:30
//---PM
- 1.30pm - 4.00pm
- 12:00-18:00
The user has the possibility to:
- Choose whether or not to view sessions
- Choose to show levels from previous sessions
- Choose to show today's session levels
- Choose whether to view the boxes
- Choose to view the division is open daily
The indicator should be used as ICT shows in its concepts, the indicator takes into consideration both the previous and today's Liquidity, and the session levels can be used for a reversal as in the example below:

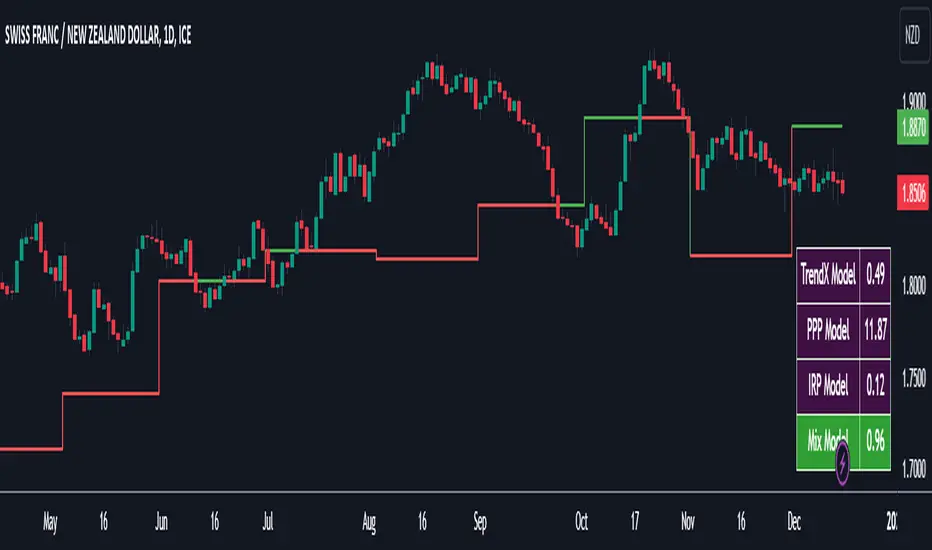
FX Forecasting Model [TrendX_]FX Forecasting Model indicator is a forecasting tool that takes advantages of macroeconomic analysis and market surveillance to predict Exchange rate movement.
*** Customize the macro data for home country (base currency) and foreign country
USAGE
This consists of 4 editable options align with 4 Forecasting Models
TrendX Model)
TrendX Model is a type of multiple linear regression, which is a statistical method that estimates the relationship between the currency exchange rate and various macroeconomic indicators.
*** Remember the 1st thing to do is to customize the macro data for home country (base currency) and foreign country, before take any further steps.
Purchasing Power Parity (PPP Model)
The PPP model is a conceptual model of currency exchange. The model illustrates how the exchange rate between two countries’ currencies is influenced by the variations in the prices of goods and services in those countries, which depend on the inflation rate. The activity of buying and selling goods and services internationally will shift the exchange rate to balance the prices in both countries.
Interest Rate Parity (IRP Model)
Interest Rate Parity (IRP) model is a theoretical model that relates the interest rates and the exchange rates of two countries. According to IRP, the difference between the forward and spot exchange rates of two currencies should be equal to the difference between their interest rates. IRP helps traders to determine the fair value of a currency pair and compare it with the market value. If the market value deviates from the fair value, then there is a potential for arbitrage or hedging.
Combined Forecast Model (Mixed Model)
Since each model has its own advantages, many people are interested in the concept of using a mix of forecasts to get better results than any single forecast. Mix Model is a method that uses different proportions of the forecasts from three models: TrendX, PPP and IRP models. The default proportion is 0.2 for TrendX, and 0.4 for both PPP and IRP. You can change these proportions according to your liking.
CONCLUSION
FX Forecasting Model Indicator is very practical for FOREX traders who wants to make informed and rational decisions based on Macroeconomic Analysis. It can help find arbitrage opportunity in currency exchange market. Accordingly, it can also be helpful for traders to use alongside other forms of Technical Analysis.
DISCLAIMER
The results achieved in the past are not all reliable sources of what will happen in the future. There are many factors and uncertainties that can affect the outcome of any endeavor, and no one can guarantee or predict with certainty what will occur.
Therefore, you should always exercise caution and judgment when making decisions based on past performance.
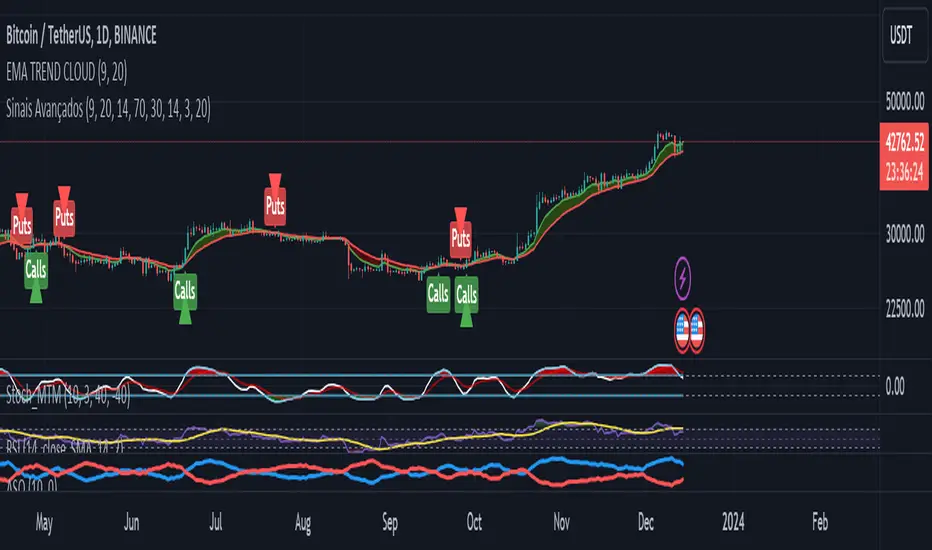
Advanced Buy and Sell SignalsThis script for TradingView is designed for technical traders seeking a more comprehensive and discerning market analysis. The script combines buy and sell signals from multiple popular technical indicators, providing a holistic view that can be useful for short to medium-term trading strategies. It incorporates the following features:
EMA Trend Cloud:
Two Exponential Moving Averages (EMAs) are calculated: a fast EMA and a slow EMA.
A "cloud" is formed on the chart, changing color as the EMAs cross, indicating potential trend shifts.
Additional Indicators:
RSI (Relative Strength Index): Used to identify overbought or oversold conditions.
Stochastic Oscillator: Helps determine the strength or weakness of the price.
OBV (On-Balance Volume) with EMA: Combines volume and price to show how volume might be influencing price direction.
Combined Buy and Sell Signals:
Buy and sell signals are generated based on a combination of the following criteria:
Crossings of the EMAs (indicative of trend changes).
Conditions of the RSI (identifying potential market extremes).
Crossings of the Stochastic Oscillator (indicating momentum).
Crossings of the OBV with its EMA (assessing the influence of volume on price movement).
Buy signals are indicated by green triangles below the price bars, while sell signals are indicated by red triangles above the price bars.
Alerts:
The script also includes alert conditions to notify the user when potential buy or sell signals are detected.
Application:
This script is suitable for traders who utilize technical analysis and seek to confirm their trading decisions with multiple sources of information. It is particularly useful in volatile markets, where the combination of different indicators can provide more reliable insights.
Note:
It is important to remember that no script or indicator can guarantee success in trading, and one should always consider risk and conduct thorough analysis before making trading decisions.
This script is most effective when used in conjunction with fundamental analysis and a solid understanding of the market.
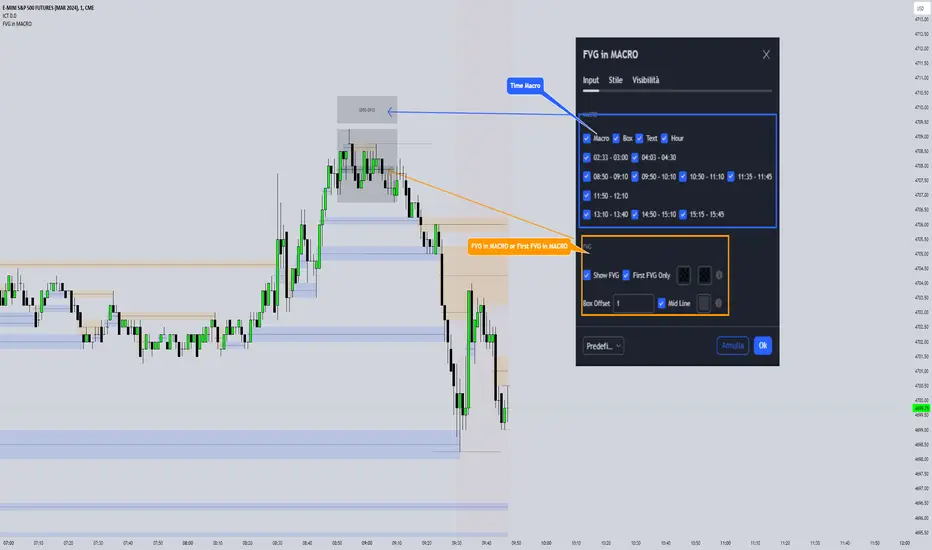
FVG in MACROGuided by ICT tutoring, I created this versatile indicator to scan the FVG in MACRO time.
This indicator combines the MACRO time with the Fair value GAP (FVG) in an alternative way, showing a simple way of viewing the FVG within the MACRO time, so you can have a clearer view of which direction the MACRO is influencing
''MACRO is a delivery time frame of the interbank price in which it undergoes a series of controls and is likely to move towards liquidity.''
The user has the possibility to:
- Choose the relevant MACRO time
- Choose whether to view all FVGs in the MACROS
- Choose to view only the First FVG at each MACRO
The indicator should be used as shown by the ICT in its concepts, during the MACRO time the price can consolidate or can head towards liquidity.
The probability that the direction is correct increases with respect for the FVG, in this way it is possible to evaluate the entry zone in the FVG and the Take profit zone for Liquidity
As in the following example:
TrendFriendOverview
TrendFriend (TF) combines various technical analysis components, including trend calculations, moving averages, RSI signals, and Fair Value Gaps (FVG) detection to determine trend reversal and continuation points. The FVG feature identifies potential consolidation periods and displays mitigation levels.
Features
Trend Analysis: Utilizes short and long-term Running Moving Averages (RMA) to identify trends.
Average True Range (ATR): Plots ATR to depict market volatility.
RSI Signals: Calculates RSI and provides buy/sell signals based on RSI conditions.
Fair Value Gaps (FVG): Detects FVG patterns and offers options for customization, including dynamic FVG, mitigation levels, and auto threshold.
Usage
Buy Signals: Generated based on pullback conditions, contra-buy signals, and crossovers of specified moving averages.
Sell Signals: Generated based on pullback conditions, contra-sell signals, and crossunders of specified moving averages.
Visualization: FVG areas are visually represented on the chart, and unmitigated levels can be displayed.
Configuration
Adjustable parameters for trend periods, ATR length, RSI settings, FVG threshold, and display preferences.
Dynamic FVG detection and mitigation level visualization can be enabled/disabled.
Usage Example
Trend Analysis: Identify trends with short and long-term moving averages.
RSI Signals: Interpret RSI signals for potential reversals.
FVG Detection: Visualize Fair Value Gaps and mitigation levels on the chart.
Buy/Sell Signals: Receive alerts for buy/sell signals based on specified conditions.
Disclaimer
This Pine Script code is subject to the terms of the Mozilla Public License 2.0. Use this code at your own risk, and always conduct additional analysis before making trading decisions.
Author
Author: devoperator84
License: Mozilla Public License 2.0
ICT IPDAGuided by ICT tutoring, I create this versatile indicator "IPDA".
This indicator shows a different way of viewing the “IPDA” by calculating from START
(-20 / -40 / -60) to (+20 /+40 /+60) Days, showing the Highs and Lows of the IPDA of the Previous days and both of the subsequent ones, the levels of (-20 / -40 / -60) Days can be taken into consideration as objectives to be achieved in the range of days (+20 /+40 /+60)
The user has the possibility to:
- Choose whether to display IPDAs before and after START
- Choose to show High and Low levels
- Choose to show Prices
The indicator should be used as ICT shows in its concepts.
Example on how to evaluate a possible Start IPDA:
Example for Entry targeting IPDAs :
If something is not clear, comment below and I will reply as soon as possible.

Potential Profit at ATHUsage:
Enter how much of the particular coin you are holding within the settings area.
What this indicator does:
Grabs the current All Time High (ATH).
Uses the ATH to calculate the potential profit in percentage from the current price to ATH.
Calculates the potential profit in EUR based on the percentage in the previous calculation.
Displays the above-mentioned values on the screen as labels.
You now have a forecast of the potential profit you can make when you hodl to the ATH.
Attention: "The example uses 1 coin as default.
For a calculation of your holdings, make sure you enter the amount of the current coin you are holding"

WRESBAL PlusWRESBAL Plus is an improved way of looking at the same data that drives WRESBAL, which is a commonly used series on FRED.
WRESBAL is a weekly average of combined balances on FRED using inputs that are weekly averages in some cases. For example the Treasury General Account has multiple FRED series including WDTGAL (wednesday level) and WTREGEN (wednesday weekly average) There are data sets that are tracking the same metrics which are updated daily such as RRPONTSYD as opposed to WLRRAL.
This situation leads to an opportunity to create a new and improved WRESBAL with the data that is updated more frequently. WRESBAL Plus solves the problem of waiting for weekly averages to update trends.
WRESBAL plus combines data sets from FRED that are updated more frequently and are the basis for the original WRESBAL equation. WRESBAL Plus offers a signal that predicts where WRESBAL will go, and this is important when determining the direction of asset prices as they relate to liquidity. One example of an asset that closely follows WRESBAL is Bitcoin.

ICT Premium/DiscountGuided by ICT mentorship and help from TraderTim and its community, I created this versatile indicator to mark a "Premium/Discount" price range.
This indicator shows the Premium and Discount Zones in an alternative way, manually setting the start of the band and automatically shows the HTF and LTF FVG present only in the set band, having a cleaning of the graph from possible other distractions, so as to be able to have a clear vision clear of the set trading range
The user has the possibility to:
- Choose the start of the interval from the graph by moving the start line
- Choose to show levels 50% - 75% - 25% of the range
- Choose the color, style and size of the lines
- Choose to display FVG LTF or HTF in range
- Choose the FVG mitigation mode
The indicator must be used as shown by the ICT in its concepts, the Premium and Discount zones are nothing more than zones where the price risks retracing, and consequently we can evaluate making entries in the Premium Zone, Sell is evaluated, in the Discoutn Zone they are evaluated as Buy, taking the opposite area as Take Profit
As in the example below:
If anything is unclear, comment below and I will get back to you as soon as possible.
How to change range:

Historical Volatility StudyThe goal of this script it to provide you an idea to forecast the future momentum by looking at historical volatility.
This chart has basically three parts.
1. Three lines are there. The multi color line represents the historical annualized volatility in terms of minimum look back period . The white line represents the historical annualized volatility in terms of medium term look back period . The green line represents the historical annualized volatility in terms of longer term look back period .
2. The back ground color has three components. Green zone is the zone where overall volatility is on the lower side. Red zone is the zone where overall volatility is on the higher side. Purple zone means fluctuating volatility.
3. The multi color line has three colors. Red color means volatility moving towards extreme low. Yellow means it is moving towards extreme high. Purple means it is in normal course of action.
This tool can be used as a confirmation tool with other studies to aid you to make better decisions. For example- look at the diagram below.
Make your thorough study before making any trading decision. Thanks.

One Setup for Life ICTGuided by ICT tutoring, I create this versatile 'One Trading Set Up For Life' indicator
This indicator shows a different way of viewing the "Highs and Lows" of Previous Sessions, drawing from the current day until 09:30 AM, the time at which the Highs and Lows of the previous day's sessions can be taken into consideration for a Reversal or for a Take profit.
Levels tested after 9.30am will be blocked so you have a good and clear view of the levels affected
Timing Session =
London: 02:00 to 05:00
New York: 9.30am to 12.30pm
Lunch: 12.30pm to 1pm
PM Session: 1.30pm to 4pm
The user has the possibility to:
- Choose to view sessions or not
- Choose to show levels from previous sessions
- Choose to show today's session levels
- Choose between 08:30 and 09:30 the starting time for the Liquidity taken
- Choose to view High and Low only from the previous day
- See both the name of the Sessions and the price of the levels
The indicator must be used as ICT shows in its concepts, the indicator takes into consideration both previous sessions and today's sessions, and the session levels can be used both for a reversal and for a possible Take Profit like the example here under
Reversal =
Possible Take Profit =
If something is not clear, comment below and I will reply as soon as possible.

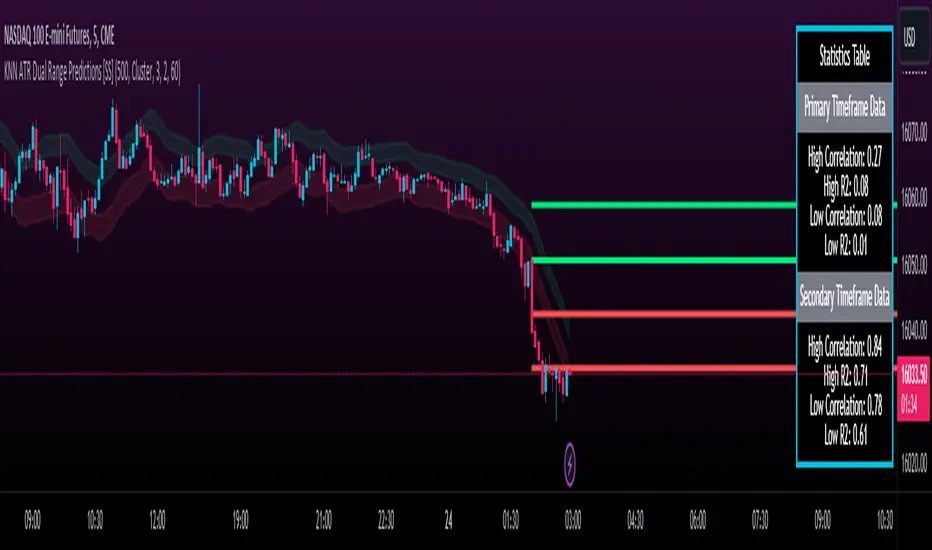
KNN ATR Dual Range Predictions [SS]Excited to release this indicator!
I wanted to do a machine learning, ATR based indicator for a while, but I first had to learn about machine learning algos haha.
Now that I have created a KNN based regression methodology (shared in a previous indicator), I can finally do it!
So this is a Nearest Known Neighbor or KNN regression based indicator that uses ATR (average ranges) to predict future ranges.
It operates by calculating the move from High to Open and Open to Low and performing KNN regression to look for other, similar instances of similar movements and what followed those movements.
It provides for 2 methods of KNN regression, the traditional Cluster method (where it identifies a number of clusters within a tolerance range and averages them out), or the method of last instance (where it finds the most recent identical instance and plots the result from that).
You can toggle the parameters as you wish, including the:
a) Type of Regression
b) Number of Clusters
c) Tolerance for Clusters
Others functions:
The indicator provides for the ability to view 2 different timeframe targets. The default calculation is the current timeframe you are on. So if you are on the 1 minute, 5 minute or 1 hour, it will automatically default the primary range to this timeframe. This cannot be changed.
But it permits for a second prediction to be calculated for a timeframe you can specify. The example in the chart above is the 1 hour overlaid on the 5 minute chart.
You can see how the model is performing in the statistics table. The statistics table can be removed as well if you don't want it overlaid on your chart.
You can also toggle off and on the various ranges. IF you only want to visualize 1 hour levels on a 5 minute chart, you can toggle off the bands and just view the higher tf data. Inversely, if you only want the current timeframe data and not the higher tf data, you can toggle the higher tf data off as well.
General Use Tips:
Some general use tips include:
🎯The default settings are appropriate for most common tickers. Because this is performing an autoregression on itself, the parameters tend to be more tight vs. performing dual correlation between two separate tickers which are sizably different in scale (which would require a higher tolerance).
Here is an example of YM1!, which is a sizably larger ticker, however it is performing well with the current settings.
🎯 If you get not great results from your ranges or an error in the correlation table, something like this:
It means the parameters are too tight for what you want to do and it is having trouble identifying other, similar cases (in this case, the lookback length was significantly shortened). The first step is to:
a) Expand your lookback range (up to 500 is usually sufficient). This should resolve most issues in most cases. If not:
b) If you are using the Cluster method, try broadening your cluster tolerance by 0.5 increments.
Between those two implementations, you should get a functional model. And it actually honestly hasn't happened to me in general use, I had to force that example by significantly shortening the lookback period.
Concluding Remarks
And that's pretty much the indicator.
I hope you enjoy it! I was really excited to be finally able to do it, like I said I attempted to do this for a while but needed to research the whole KNN process and how its performed.
Enjoy and leave your comments and questions below!
Data from dataThe "Data from Data" indicator, developed by OmegaTools, is a sophisticated and versatile tool designed to offer a nuanced analysis of various market dynamics, catering to traders and investors seeking a comprehensive understanding of price movements considering a large amount of data and variables.
The uses of this indicator are nonconventional. You can use the indicator as a stand-alone tool on the chart, hiding the current symbol price data, to be able to analyze the price action with the Semaphore visualization method, you can also hide the indicator and choose from your favorite indicators and oscillator one of the data output as a source to have additional insight on the asset.
The last use of this indicator, which depends on the X Value that you set in the settings, is to have a possible scenario for the future outcomes of the markets. Remember that there is no tool that can really predict what the market will do in the future, this tool applies a large amount of formulas to use past prices as an indication that aims to be as close as possible to the future prices. The X Value not only changes the lookback of the formulas but also changes the number of future scenarios that the indicator will plot on the chart.
Key Features:
1. Rate of Change Analysis:
The indicator evaluates the rate of change variations in closing prices, providing insights into the current rate of change and expected rate of change variation.
2. Momentum Analysis:
Momentum is analyzed through calculations involving simple moving averages, offering expected values derived from momentum and momentum variation.
3. High/Low Variation:
The expected market behavior is assessed based on the average variation between high and low prices, contributing to a more holistic analysis.
4. Liquidity Targets:
Liquidity targets can be found by analyzing the highs and lows in the direction of the current fair price.
5. Regression Sequence:
Linear regression analysis is applied to closing prices, assessing momentum and providing expected values based on regression sequences.
6. Volume Presence:
The indicator evaluates the Rate of Change (ROC) by volume presence, offering insights into price movements influenced by trading volume.
7. Liquidity Grabs:
Expected market behavior is determined based on liquidity grabs, considering both current and historical price levels.
8. Fair Value Analysis:
Expected values are derived from fair value closes and fair value highs and lows, contributing to a more nuanced analysis of market conditions.
9. STT (Sequential Trend Test):
The Sequential Trend Test is employed to analyze market trends, providing expected values for a more informed decision-making process.
Visualization:
The indicator shows a "Semaphore" on the chart, visually representing all of the data extrapolated from the script. The visualization can be more minimalistic or more complex, to let the user decide that, in the settings, it's possible to decide if to show all of the data or only the average.
Additionally, the user can choose to display bars on the chart, that visualize the standard high and low of the price data, with the difference between the expected forecasted value and the actual closing price.
My suggestion is to try to change the colors of the data to fit best your eye and the data that you find more useful, and also to try to change some parameters from circle to line as a visualization method to catch with more ease some price patterns.
Error Analysis:
The indicator provides a detailed error analysis, including historical error, average error, and present error. This information is presented in a user-friendly table for quick reference. This table can be used to analyze the margin of error of the expected future price.

Backtest Strategy Optimizer Adapter - Supertrend ExampleSample Code
This is a sample code for my Backtest Strategy Optimizer Adapter library.
You can find the library at:
Backtest Strategy Optimizer Tester
With this indicator, you will be able to run one or multiple backtests with different variables (combinations). For example, you can run dozens of backtests of Supertrend at once with an increment factor of 0.1, or whatever you prefer. This way, you can easily grab the most profitable settings and use them in your strategy. The chart above shows different color plots, each indicating a profit backtest equal to tradingview backtesting system. This code uses my backtest library, available in my profile.
Below the code you should edit yourself
You can use ChatGPT or write a python script to autogenerate code for you.
// #################################################################
// # ENTRIES AND EXITS
// #################################################################
// You can use the link and code in the description to create
// your code for the desired number of entries / exits.
// #################################################################
// AUTO GENERATED CODE
// ▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼
= ti.supertrend(10, 0.1)
= ti.supertrend(10, 0.2)
= ti.supertrend(10, 0.3)
= ti.supertrend(10, 0.4)
// 005 etc...
pnl_001 = backtest.profit(date_start, date_end, entry_001, exit_001)
pnl_002 = backtest.profit(date_start, date_end, entry_002, exit_002)
pnl_003 = backtest.profit(date_start, date_end, entry_003, exit_003)
pnl_004 = backtest.profit(date_start, date_end, entry_004, exit_004)
plot(pnl_001, title='0.1', color=backtest.color(001))
plot(pnl_002, title='0.2', color=backtest.color(002))
plot(pnl_003, title='0.3', color=backtest.color(003))
plot(pnl_004, title='0.4', color=backtest.color(004))
// Make sure you set the correct array size.
// The amount of tests + 1 (e.g. 4 tests you set it to 5)
var results_list = array.new_string(5)
if (ta.change(pnl_001))
array.set(results_list, 0, str.tostring(pnl_001) + '|0.1')
if (ta.change(pnl_002))
array.set(results_list, 1, str.tostring(pnl_002) + '|0.2')
if (ta.change(pnl_003))
array.set(results_list, 2, str.tostring(pnl_003) + '|0.3')
if (ta.change(pnl_004))
array.set(results_list, 3, str.tostring(pnl_004) + '|0.4')
// ▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲
// AUTO GENERATED CODE
// #################################################################
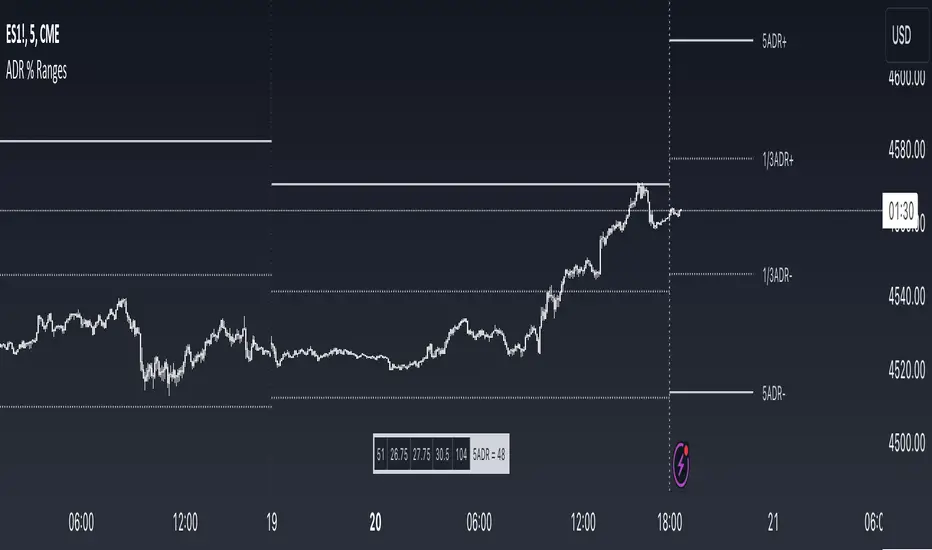
ADR % RangesThis indicator is designed to visually represent percentage lines from the open of the day. The % amount is determined by X amount of the last days to create an average...or Average Daily Range (ADR).
1. ADR Percentage Lines: The core function of the script is to apply lines to the chart that represent specific percentage changes from the daily open. It first calculates the average over X amount of days and then displays two lines that are 1/3rd of that average. One line goes above the other line goes below. The other two lines are the full "range" of the average. These lines can act as boundaries or targets to know how an asset has moved recently. *Past performance is not indicative of current or future results.
The calculation for ADR is:
Step 1. Calculate Today's Range = DailyHigh - DailyLow
Step 2. Store this average after the day has completed
Step 3. Sum all day's ranges
Step 4. Divide by total number of days
Step 5. Draw on chart
2. Customizable Inputs: Users have the flexibility to customize the script through various inputs. This includes the option to display lines only for the current trading day (`todayonly`), and to select which lines are displayed. The user can also opt to show a table the displays the total range of previous days and the average range of those previous days.
3. No Secondary Timeframe: The ADR is computed based on whatever timeframe the chart is and does not reference secondary periods. Therefore the script cannot be used on charts greater than daily.
This script is can be used by all traders for any market. The trader might have to adjust the "X" number of days back to compute a historical average. Maybe they only want to know the average over the past week (5 days) or maybe the past month (20 days).
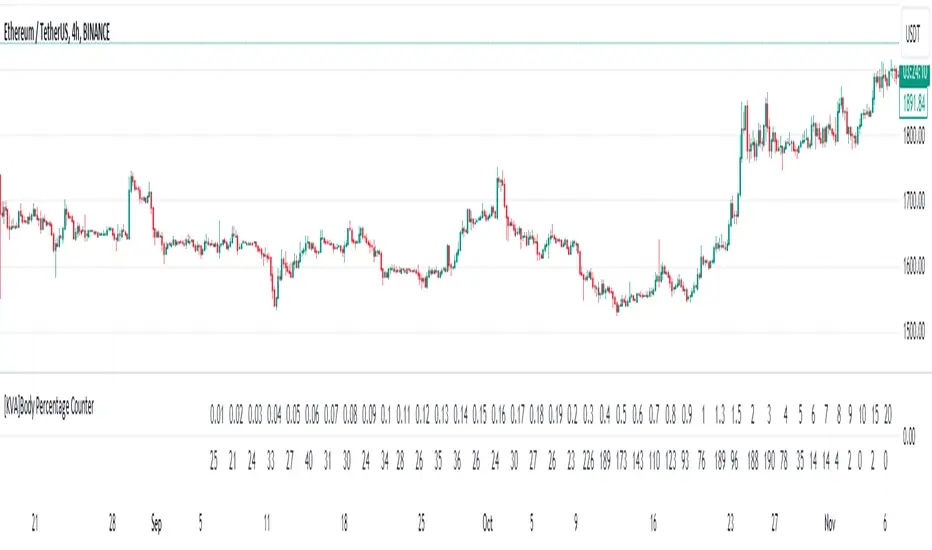
[KVA]Body Percentage Counter This indicator presents a comprehensive view of the historical candle data within user-defined body percentage ranges. Each column represents a specific body size percentage threshold, starting from as low as 0.01% and extending up to 20%.
The rows categorize candles by their closing and opening price differences, effectively sorting them into green (bullish) and red (bearish) candles based on whether they closed higher or lower than their opening prices.
First Row of the table is the bu
For developers, this table can be immensely useful in determining stop-loss ranges. By analyzing the frequency of candles that fall within certain body percentage ranges, developers can better understand where to set stop-loss orders. For instance, if a developer notices a high frequency of candles with body sizes within a specific percentage range, they may choose to set their stop-loss orders outside of this range to avoid being stopped out by normal market fluctuations.
Moreover, the indicator can be used to:
Volatility Assessment : The indicator can be used to gauge market volatility. Smaller bodies may indicate consolidation periods, while larger bodies might suggest more volatile market conditions.
Optimize Trading Strategies : Adjust entry and exit points based on the prevalence of certain candle sizes.
Risk Management : Determine the commonality of price movements within a certain range to better manage risks.
Backtesting : Use historical data to backtest how different stop-loss ranges would have performed in the past.
Comparative Analysis : Traders can compare the frequency of different body sizes over a selected period, providing insights into how the market is evolving.
Educational Use : For new traders, the indicator can serve as an educational tool to understand the implications of candlestick sizes and their relationship with market dynamics
The data provided in this output can guide developers to make more informed decisions about where to place stop-loss orders, potentially increasing the effectiveness of their trading algorithms or manual trading strategies.
The output of the " Body Percentage Counter" indicator is organized into a table format, which can be broken down as follows:
Header (First Row) : This row lists the body percentage thresholds used to categorize the candles. It starts from 0.01% and increases incrementally to 20%. These thresholds are likely set by the user and represent the range of candle body sizes as a percentage of the total candle size.
Green Candle Count (Second Row) : This row displays the count of green candles—candles where the close price is higher than the open price—that fall within each body percentage threshold. For example, under the column "0.01", the number 25 indicates there are 25 green candles whose body size is 0.01% of the total candle size.
Red Candle Count (Third Row) : This row shows the count of red candles—candles where the close price is lower than the open price—for each body percentage threshold. The numbers in this row reflect the number of red candles that match the body percentage criteria in the corresponding column.
Total Candle Count (Fourth Row) : This row sums the counts of both green and red candles for each body percentage threshold, providing a total count of candles that have a body size within the specific range. For instance, if under "0.01" the green count is 25 and the red count is 26, then the total would be 51.
This organized data representation allows users to quickly assess the distribution of candle body sizes over a historical period, which is especially useful for determining the frequency of price movements that are significant enough to consider for stop-loss settings or other trade management decisions.
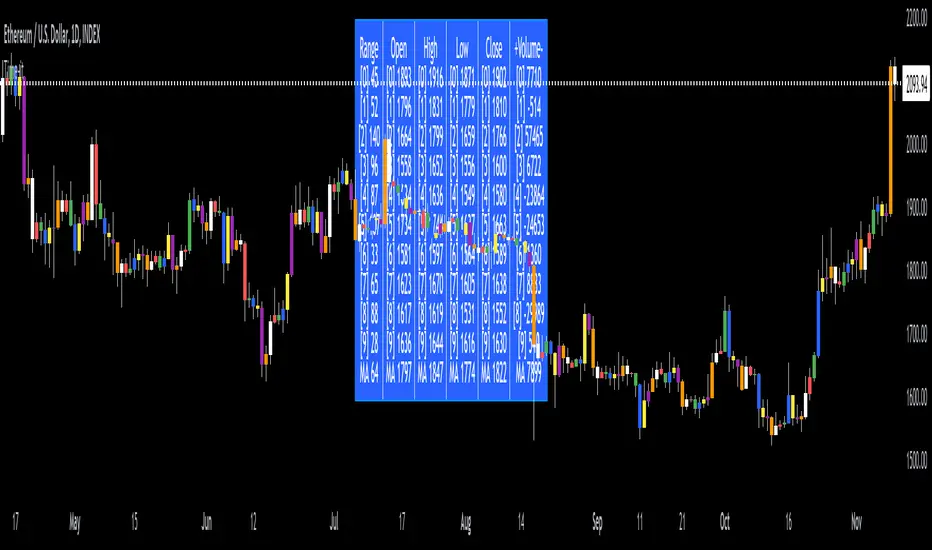
Time-itTime-it = Time based indicator
The Time-it indicator parses data by the day of week. Every tradeable instrument has its own personality. Some are more volatile on Mondays, and some are more bullish / bearish on Fridays or any day in between. The key metrics Time-it parses is range, open, high, low, close and +volume-.
The Time-it parsed data is printed in a table format. The table, position, size & color and text color & size can be changed to your preference. Each column parsed data is the last 10 which is numbered 0-9 which refers to the number of the selected day bars ago. For example: if Monday is chosen, 0 is the last closed Monday bar and 9 is the last closed Monday 9 Monday bars ago.
Range = measures the range between high and low for the day.
Open = is the opening price for the day.
High = is the high price for the day.
Low = is the low price for the day.
Close = is the closing price for the day.
+volume- = is the positive or negative volume for the day.
Default settings:
*Represents a how to use tooltip*
Source = ohlc4
* The source used for MA
MA length = 20
* The moving average used
Day bar color on / off
* checked on / unchecked off
Monday = blue
Tuesday = yellow
Wednesday = purple
Thursday = orange
Friday = white
Saturday = red
Sunday = green
Day M, T, W, TH, F, ST, SN.
* Parsed data for the day of week tables
Table, position, size & color:
Top, middle, bottom, left, center, right
* Table position on the chart.
Frame width & border width = 1
Text color and text size
Border color and frame color
Decimal place = 0
* example: use 0 for a round number, use 4 for Forex
*** The Time-it indicator uses parts and/or pieces of code from "Tradingview Up/Down Volume" and "Tradingview Financials on Chart".
Trend Line XrossTrend Line Xross (TLX) Uses User Input Points to draw trendlines and displays the exact intersection point of those trendlines.
This is the public indicator of the practical application for this intersection method included in my entry for Pinefest #1.
To determine the exact intersection point I am using the y-intercept method as seen below.
The code is notated for more information on the technical workings.
One difference to note between this version and the pinefest version is that I had to change the line drawings to use bar_index values so that I can use line.get_price() to grab the current value of the line to make alerts from.
Additionally, there are alerts built-in to this version for every type of cross on all of the visible lines.
Enjoy!
